Leer texto de imágenes usando Tesseract en Python

Presentaremos cómo crear un programa que pueda leer texto de imágenes usando Tesseract en Python.
Teseracto en Python
Usamos Tesseract en Python cuando trabajamos en sistemas con funciones en las que necesitamos leer textos de imágenes. Proporciona potentes funciones que nos ayudan a leer el texto de las imágenes con mayor precisión y eficiencia.
Este artículo también presentará la extracción de texto de una imagen utilizando la popular biblioteca OpenCV.
Tesseract es un sistema basado en computadora para el reconocimiento óptico de caracteres (OCR) y otros procesos de imagen a texto. Se utiliza principalmente para el reconocimiento de texto en idiomas que no utilizan el alfabeto latino.
El sistema se utiliza para diversos fines, incluidos la extracción de texto y datos, la educación, la traducción y la traducción automática.
Tesseract es también el nombre de la versión de código abierto del software. A menudo se usa en el procesamiento del lenguaje natural y el aprendizaje automático para la clasificación de textos y otras tareas relacionadas con el texto.
Primero, instalemos la herramienta Tesseract en Python usando la siguiente línea de código.
pip install pytesseract
Una vez que hayamos instalado la herramienta Tesseract, instalaremos otras bibliotecas importantes que usaremos en nuestros ejemplos para leer texto de imágenes. Primero, instalaremos OpenCV con el siguiente comando.
pip install opencv-python
Ahora instalaremos la biblioteca ArgParse que usaremos para crear una interfaz de línea de comandos fácil de usar. Podemos instalarlo fácilmente usando el siguiente comando.
pip install argparse
Ahora instalaremos la biblioteca Pillow, una biblioteca de imágenes de Python. Esta biblioteca agregará las capacidades de procesamiento de imágenes a nuestro intérprete de python.
Podemos instalar esta biblioteca usando el comando que se muestra a continuación.
pip install Pillow
Leer texto de imágenes usando Tesseract en Python
Ahora, usemos Tesseract para leer texto de imágenes en Python. Necesitamos seguir los siguientes pasos para que funcione.
En primer lugar, importaremos o cargaremos la imagen de nuestra galería desde la que queremos leer el texto, y si no la tenemos, podemos descargarla de Chrome y luego cargarla.
Una vez que hayamos importado nuestras imágenes, convertiremos la imagen cargada en un archivo binario. En el último paso, enviaremos el archivo binario a Tesseract, que buscará texto en ellos y devolverá el texto de las imágenes.
Importaremos todas las bibliotecas que instalamos anteriormente.
# python
import cv2
import os
import argparse
import pytesseract
from PIL import Image
Construiremos el analizador de argumentos usando la función ArgParse ArgumentParser() como se muestra a continuación.
# python
imgArg = argparse.ArgumentParser()
imgArg.add_argument("-i", "--image", required=True, help="Enter path of image folder")
imgArg.add_argument(
"-p", "--pre_processor", default="thresh", help="the preprocessor usage"
)
arguments = vars(imgArg.parse_args())
Ahora leeremos la imagen con el texto usando la biblioteca OpenCV con el siguiente código.
# python
imageRead = cv2.imread(arguments["image"])
Ahora, convertiremos la imagen a escala de grises utilizando la biblioteca OpenCV, como se muestra a continuación.
# python
imgGray = cv2.cvtColor(imageRead, cv2.COLOR_BGR2GRAY)
Luego, usaremos la declaración if-else para verificar si la imagen está trillada o borrosa. Si es así, podemos cambiar el umbral y el desenfoque como se muestra a continuación.
# python
if arguments["pre_processor"] == "thresh":
cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
if arguments["pre_processor"] == "blur":
cv2.medianBlur(gray, 3)
Como se muestra a continuación, agregaremos una imagen a la memoria utilizando las bibliotecas OpenCV y Tesseract.
# python
nameImg = "{}.jpg".format(os.getpid())
cv2.imwrite(nameImg, gray)
imgText = pytesseract.image_to_string(Image.open(nameImg))
os.remove(nameImg)
print(imgText)
Ahora, mostraremos la salida de la imagen usando el siguiente código.
# python
cv2.imshow("Images Uploaded", imageRead)
cv2.imshow("Images Converted In Grayscale", imgGray)
cv2.waitKey(0)
Ahora, ejecutemos el código anterior con el siguiente código y verifiquemos cómo funciona y qué tan bien lee el texto de las imágenes.
# python
python main.py --image img/read.jpg
La imagen que enviamos se muestra a continuación:
Una vez procesada la imagen, se guardará en escala de grises como se muestra a continuación:

Tendremos el siguiente resultado en el símbolo del sistema:
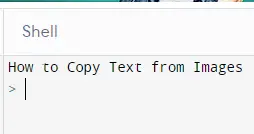
Como puede ver en el ejemplo anterior, podemos usar fácilmente las imágenes y leer su texto. Y podemos almacenarlos si queremos o mostrarlos en la consola.

Rana is a computer science graduate passionate about helping people to build and diagnose scalable web application problems and problems developers face across the full-stack.
LinkedIn