Python에서 Tesseract를 사용하여 이미지에서 텍스트 읽기

Python에서 Tesseract를 사용하여 이미지에서 텍스트를 읽을 수 있는 프로그램을 만드는 방법을 소개합니다.
파이썬의 테서랙트
이미지에서 텍스트를 읽어야 하는 기능이 있는 시스템에서 작업할 때 Python의 Tesseract를 사용합니다. 이미지에서 텍스트를 보다 정확하고 효율적으로 읽을 수 있도록 도와주는 강력한 기능을 제공합니다.
이 기사에서는 인기 있는 OpenCV 라이브러리를 사용하여 이미지에서 텍스트를 추출하는 방법도 소개합니다.
Tesseract는 광학 문자 인식(OCR) 및 기타 이미지-텍스트 프로세스를 위한 컴퓨터 기반 시스템입니다. 주로 라틴 알파벳을 사용하지 않는 언어의 텍스트 인식에 사용됩니다.
이 시스템은 텍스트 및 데이터 마이닝, 교육, 번역, 기계 번역 등 다양한 용도로 사용됩니다.
Tesseract는 소프트웨어의 오픈 소스 버전 이름이기도 합니다. 텍스트 분류 및 기타 텍스트 관련 작업을 위해 자연어 처리 및 기계 학습에 자주 사용됩니다.
먼저 다음 코드 줄을 사용하여 Python에 Tesseract 도구를 설치하겠습니다.
pip install pytesseract
Tesseract 도구를 설치하고 나면 예제에서 이미지에서 텍스트를 읽는 데 사용할 다른 중요한 라이브러리를 설치합니다. 먼저 다음 명령으로 OpenCV를 설치합니다.
pip install opencv-python
이제 사용자 친화적인 명령줄 인터페이스를 만드는 데 사용할 ArgParse 라이브러리를 설치합니다. 다음 명령을 사용하여 쉽게 설치할 수 있습니다.
pip install argparse
이제 Python 이미징 라이브러리인 Pillow 라이브러리를 설치합니다. 이 라이브러리는 파이썬 인터프리터에 이미지 처리 기능을 추가합니다.
아래 표시된 명령을 사용하여 이 라이브러리를 설치할 수 있습니다.
pip install Pillow
Python에서 Tesseract를 사용하여 이미지에서 텍스트 읽기
이제 Tesseract를 사용하여 Python의 이미지에서 텍스트를 읽어 봅시다. 작동하려면 다음 단계를 따라야 합니다.
먼저 텍스트를 읽고 싶은 갤러리에서 이미지를 가져오거나 로드하고, 이미지가 없으면 Chrome에서 다운로드한 다음 로드할 수 있습니다.
이미지를 가져오면 로드된 이미지를 이진 파일로 변환합니다. 마지막 단계에서 바이너리 파일을 Tesseract로 보내면 Tesseract에서 텍스트를 찾고 이미지에서 텍스트를 반환합니다.
이전에 설치한 모든 라이브러리를 가져옵니다.
# python
import cv2
import os
import argparse
import pytesseract
from PIL import Image
아래와 같이 ArgParse 함수 ArgumentParser()를 사용하여 인수 파서를 구성합니다.
# python
imgArg = argparse.ArgumentParser()
imgArg.add_argument("-i", "--image", required=True, help="Enter path of image folder")
imgArg.add_argument(
"-p", "--pre_processor", default="thresh", help="the preprocessor usage"
)
arguments = vars(imgArg.parse_args())
이제 다음 코드와 함께 OpenCV 라이브러리를 사용하여 텍스트가 있는 이미지를 읽습니다.
# python
imageRead = cv2.imread(arguments["image"])
이제 아래와 같이 OpenCV 라이브러리를 사용하여 이미지를 그레이스케일로 변환합니다.
# python
imgGray = cv2.cvtColor(imageRead, cv2.COLOR_BGR2GRAY)
그런 다음 if-else 문을 사용하여 이미지가 잘렸는지 또는 흐릿한지 확인합니다. 그렇다면 아래와 같이 thresh와 blur를 변경할 수 있습니다.
# python
if arguments["pre_processor"] == "thresh":
cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
if arguments["pre_processor"] == "blur":
cv2.medianBlur(gray, 3)
아래와 같이 OpenCV 및 Tesseract 라이브러리를 사용하여 메모리에 이미지를 추가합니다.
# python
nameImg = "{}.jpg".format(os.getpid())
cv2.imwrite(nameImg, gray)
imgText = pytesseract.image_to_string(Image.open(nameImg))
os.remove(nameImg)
print(imgText)
이제 다음 코드를 사용하여 이미지 출력을 보여드리겠습니다.
# python
cv2.imshow("Images Uploaded", imageRead)
cv2.imshow("Images Converted In Grayscale", imgGray)
cv2.waitKey(0)
이제 위의 코드를 다음 코드로 실행하여 어떻게 작동하는지, 이미지에서 텍스트를 얼마나 잘 읽는지 확인해 봅시다.
# python
python main.py --image img/read.jpg
우리가 보낸 이미지는 아래와 같습니다.
이미지가 처리되면 아래와 같이 그레이스케일로 저장됩니다.

명령 프롬프트에 다음과 같은 결과가 표시됩니다.
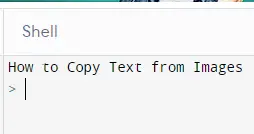
위의 예에서 볼 수 있듯이 이미지를 쉽게 사용하고 텍스트를 읽을 수 있습니다. 원하는 경우 저장하거나 콘솔에 표시할 수 있습니다.

Rana is a computer science graduate passionate about helping people to build and diagnose scalable web application problems and problems developers face across the full-stack.
LinkedIn