Pandas DataFrame 行を正規表現でフィルタリングする
- Python で Pandas DataFrame 行をフィルタリングする
- Pandas DataFrame 行を正規表現でフィルタリングする
- Pandas DataFrame の行を文字列でフィルタリングする

この記事では、正規表現と文字列関数を使用して Pandas データフレームをフィルタリングする方法を学習します。 また、Python で Pandas データフレームに filter 関数を適用する方法も学びます。
Python で Pandas DataFrame 行をフィルタリングする
このコードでは、最初に pandas をインポートしました。 次に、CSV ファイルから pokemon_data をインポートしました。 最初の 50 個の元のポケモン データはここにあります。
Name、Type 1、Type 2、および特殊攻撃、速度などのさまざまな属性など、さまざまな情報が表示されます。
import pandas as pd
POK_Data = pd.read_csv("pokemon_data.csv")
POK_Data
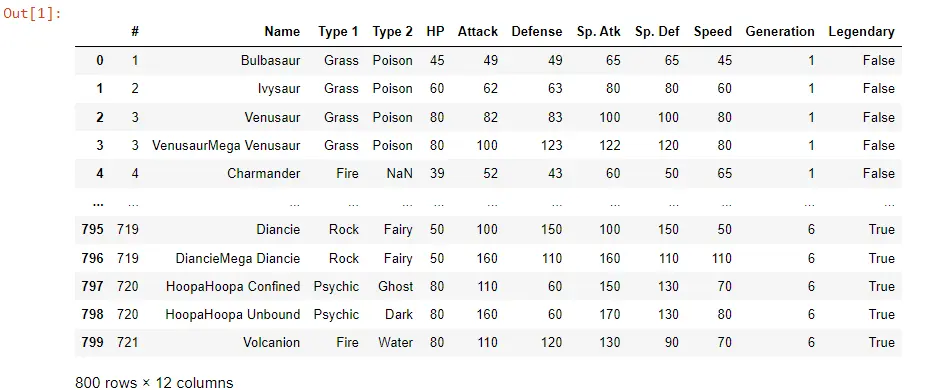
データフレームをフィルタリングするにはさまざまなオプションがありますが、行をフィルタリングするか、すべてのポケモンをインスタンスに保持したいと考えています。 次のコードを使用して、80 を超える攻撃に対してこれを行うことができます。
PK_Filtered_Data = POK_Data[POK_Data["Attack"] > 80]
PK_Filtered_Data
フィルタリングするには、ブラケットを使用します。 列に基づいてフィルタリングします。 この場合、列は Attack になります。
これを行うと、すべてのデータが 80 を超えます。これを実行すると、別のデータフレームがあることがわかります。
Attack 列を見ると、すべてが 80 を超えていることがわかります。フィルタリングされたデータフレームを PK_Filtered_Data という別の変数に保存します。
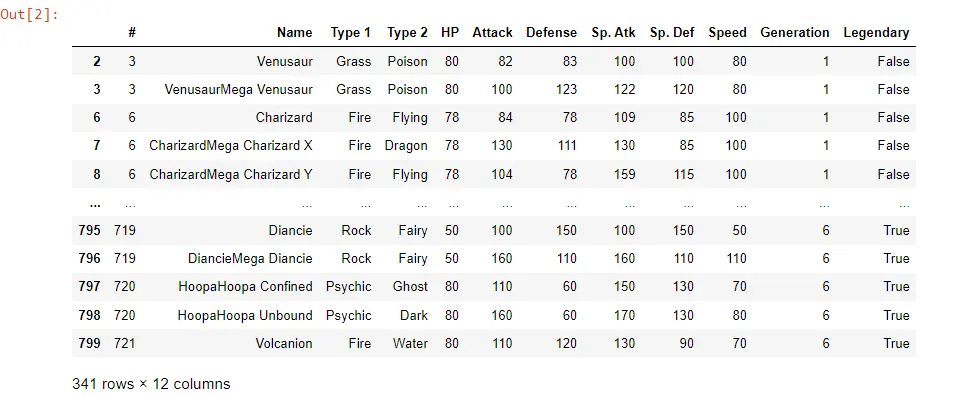
Pandas DataFrame 行を正規表現でフィルタリングする
他の列に対してこれを行うことも、複数の列に対してこれを結合することもできます。 Attack 列で 80 を超えるデータをフィルター処理し、同時に Sp をフィルター処理するとします。 Atkが100以上であること。
ブラケットを使用する必要はありません。 別のオプションは、POK_Data[POK_Data.Attack>80] を使用してデータフレームをフィルタリングすることです。
filter() 関数を使用してデータフレームをフィルタリングし、正規表現を適用することもできます。
正規表現は、filter() 関数を使用してデータフレームの列をフィルタリングできます。 この関数で regex パラメータを使用して正規表現を指定します。
e で終わるすべての列を保持するために regex に値を渡します。ドル記号は、名前が e で終わる列をフィルター処理することを意味します。 列レベルであるため、軸が 1 に等しいことも指定する必要があります。
POK_Data.filter(regex="e$", axis=1)
完全なデータフレームを返しますが、e で終わる列のみを返します。
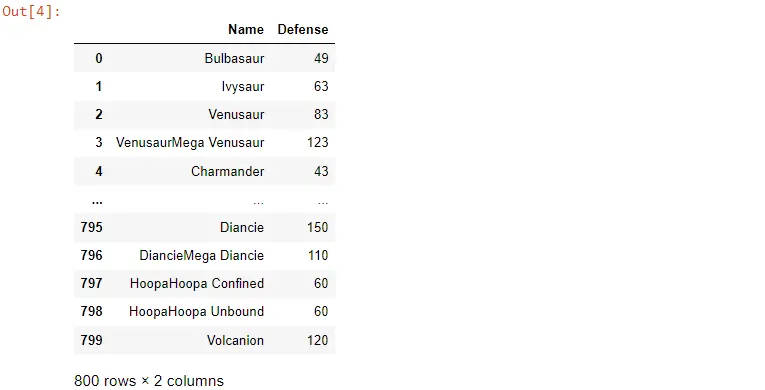
この場合、正規表現を適用しながら M で始まる Name を使用して行をフィルタリングします。
POK_Data[POK_Data["Name"].str.contains("^M")]
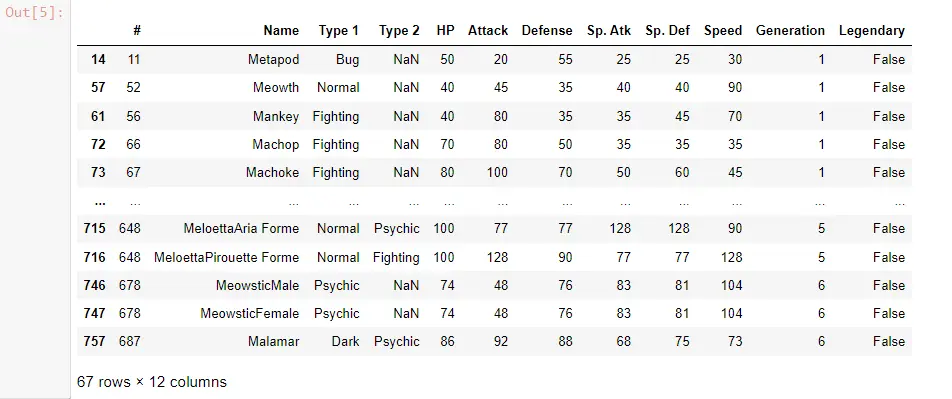
Pandas DataFrame の行を文字列でフィルタリングする
正規表現を使用してデータフレームの行をフィルタリングすることもできます。 上記のコードは、特定の列を指定する必要があるため、正確には機能しません。 データフレームをフィルタリングしたい場合は、contains() 関数を使用します。
この場合、データフレーム フィルターは Name に適用され、contains() 関数内で ur を文字列として渡します。 contains() は実際には文字列値に基づく関数であり、POK_Data['Name'] 自体は Pandas シリーズであるため、str() 関数を使用しています。
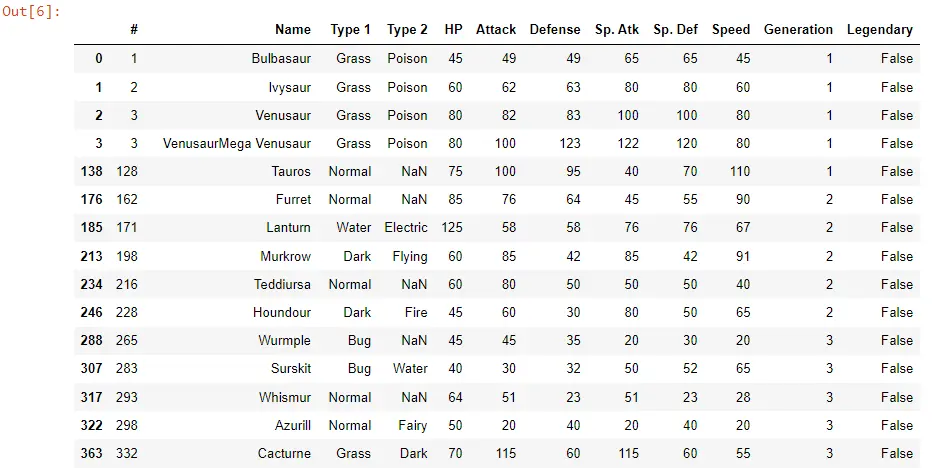
POK_Data[POK_Data["Name"].str.contains("ur")]
これを実行すると、ur を含むポケモンはごくわずかであることがわかります。
完全な Python コード:
# In[1]:
import pandas as pd
POK_Data = pd.read_csv("pokemon_data.csv")
POK_Data
# In[ ]:
# In[2]:
# PK_Filtered_Data= POK_Data[POK_Data['Attack'] >80]
# PK_Filtered_Data
# In[3]:
# PK_Filtered_Data= POK_Data[POK_Data.Attack>80]
# PK_Filtered_Data
# In[4]:
# POK_Data.filter(regex='e$',axis=1)
# In[5]:
POK_Data[POK_Data["Name"].str.contains("^M")]
# In[6]:
POK_Data[POK_Data["Name"].str.contains("ur")]
こちら でその他のソリューションをお読みください。

Hello! I am Salman Bin Mehmood(Baum), a software developer and I help organizations, address complex problems. My expertise lies within back-end, data science and machine learning. I am a lifelong learner, currently working on metaverse, and enrolled in a course building an AI application with python. I love solving problems and developing bug-free software for people. I write content related to python and hot Technologies.
LinkedIn