Filtrar filas de Pandas DataFrame por Regex
- Filtrar filas de Pandas DataFrame en Python
- Filtrar filas de Pandas DataFrame por Regex
- Filtrar filas de Pandas DataFrame por cadena

En este artículo, aprenderemos cómo filtrar nuestro marco de datos de Pandas con la ayuda de expresiones regulares y funciones de cadena. También aprenderemos a aplicar la función filter en un dataframe de Pandas en Python.
Filtrar filas de Pandas DataFrame en Python
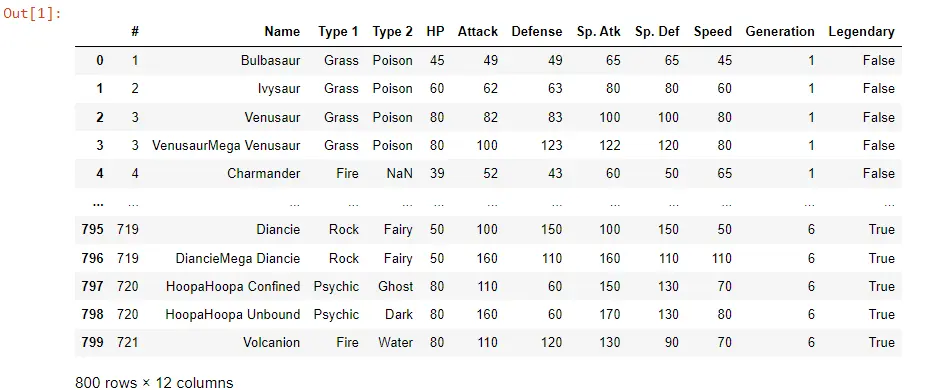
En nuestro código, primero importamos pandas. Luego, importamos los pokemon_data desde un archivo CSV; los primeros 50 datos originales de Pokémon están aquí.
Vemos diversa información como el Nombre, el Tipo 1, Tipo 2, y los diferentes atributos que tienen, como ataques especiales, velocidad, etc.
import pandas as pd
POK_Data = pd.read_csv("pokemon_data.csv")
POK_Data
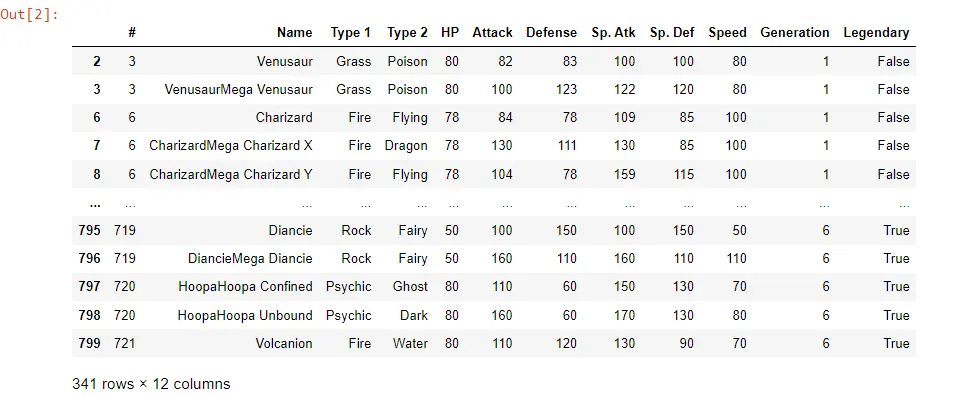
Hay varias opciones para filtrar el marco de datos, pero queremos filtrar las filas o mantener todos los Pokémon con una instancia. Podríamos hacer esto para un ataque por encima de 80 usando el siguiente código.
PK_Filtered_Data = POK_Data[POK_Data["Attack"] > 80]
PK_Filtered_Data
Para filtrar, usaremos corchetes. Queremos filtrar según la columna; en este caso, nuestra columna sería Ataque.
Al hacer esto, tendremos todos los datos mayores a 80. Si ejecutamos esto, podemos ver que ahora tenemos un marco de datos diferente.
Mirando la columna Ataque, veremos que ahora todos están por encima de 80. Almacenaremos el marco de datos filtrado en otra variable llamada PK_Filtered_Data.
Filtrar filas de Pandas DataFrame por Regex
También podemos hacer esto para otras columnas o combinar esto para varias columnas. Supongamos que filtramos los datos superiores a 80 en la columna Ataque y, simultáneamente, filtramos los datos Sp. Atk por encima de 100.
No necesitamos usar los corchetes. Otra opción es filtrar el marco de datos utilizando POK_Data[POK_Data.Attack>80].
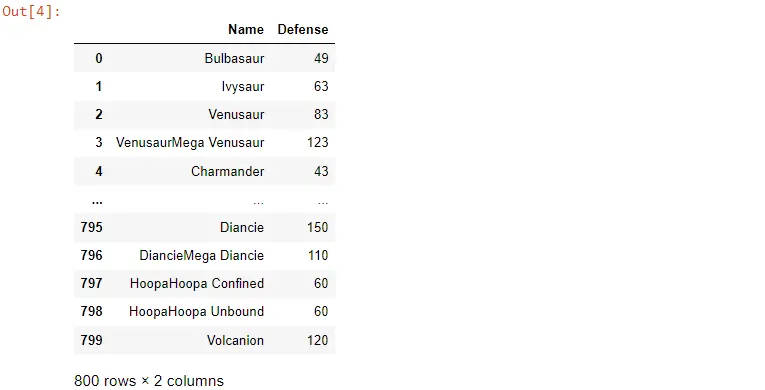
También podemos filtrar el dataframe usando la función filter() y aplicar la expresión regular.
Las expresiones regulares pueden filtrar las columnas de un dataframe usando la función filter(). Especificamos las expresiones regulares usando el parámetro regex en esta función.
Pasamos un valor a regex para mantener todas las columnas que terminan con la letra e, y el símbolo del dólar significa que filtramos las columnas cuyos nombres terminan con e. Como estamos en el nivel de una columna, también debemos especificar que el eje es igual a 1.
POK_Data.filter(regex="e$", axis=1)
Devolverá el marco de datos completo, pero solo las columnas que terminan con e.
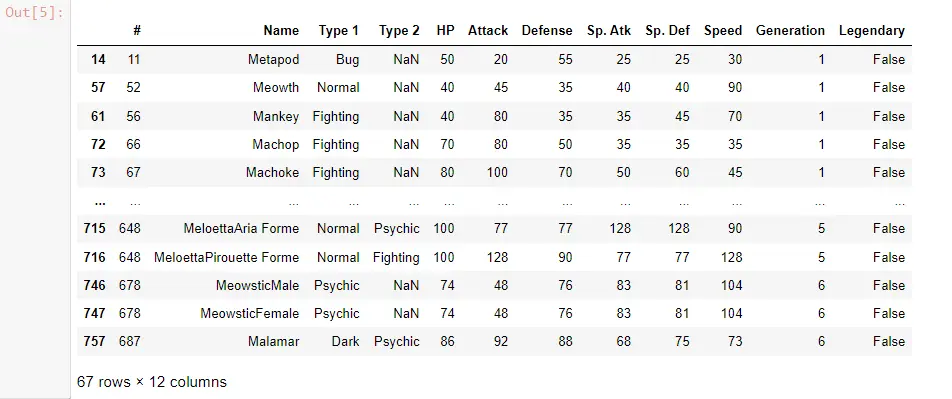
En este caso, filtramos las filas usando un Nombre que comienza con M mientras aplicamos una expresión regular.
POK_Data[POK_Data["Name"].str.contains("^M")]
Filtrar filas de Pandas DataFrame por cadena
También podemos filtrar las filas del dataframe usando expresiones regulares. El código anterior no funciona exactamente de esa manera porque necesitaríamos especificar la columna específica. Si queremos filtrar el dataframe, usaremos la función contains().
En este caso, el filtro de marco de datos se aplica en el Nombre, y dentro de la función contiene(), pasamos ur como una cadena. Estamos utilizando la función str() porque contains() es en realidad una función basada en valores de cadena aquí y POK_Data['Name'] en sí mismo es una serie de Pandas.
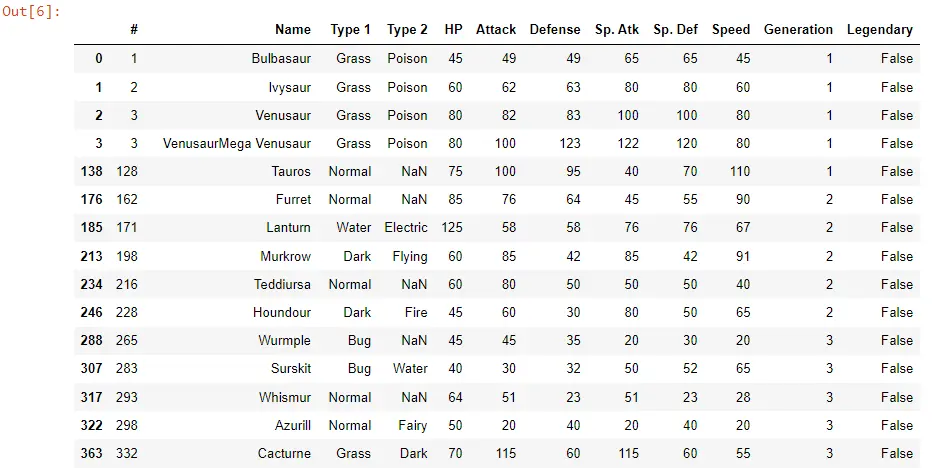
POK_Data[POK_Data["Name"].str.contains("ur")]
Ahora, si ejecutamos esto, vemos que solo unos pocos Pokémon contienen ur.
Código Python completo:
# In[1]:
import pandas as pd
POK_Data = pd.read_csv("pokemon_data.csv")
POK_Data
# In[ ]:
# In[2]:
# PK_Filtered_Data= POK_Data[POK_Data['Attack'] >80]
# PK_Filtered_Data
# In[3]:
# PK_Filtered_Data= POK_Data[POK_Data.Attack>80]
# PK_Filtered_Data
# In[4]:
# POK_Data.filter(regex='e$',axis=1)
# In[5]:
POK_Data[POK_Data["Name"].str.contains("^M")]
# In[6]:
POK_Data[POK_Data["Name"].str.contains("ur")]
Lea más soluciones aquí.

Hello! I am Salman Bin Mehmood(Baum), a software developer and I help organizations, address complex problems. My expertise lies within back-end, data science and machine learning. I am a lifelong learner, currently working on metaverse, and enrolled in a course building an AI application with python. I love solving problems and developing bug-free software for people. I write content related to python and hot Technologies.
LinkedIn