Pandas DataFrame-Zeilen nach Regex filtern
- Pandas DataFrame-Zeilen in Python filtern
- Pandas DataFrame-Zeilen nach Regex filtern
- Filtern Sie Pandas DataFrame-Zeilen nach Zeichenfolge

In diesem Artikel erfahren Sie, wie Sie unseren Pandas-Datenrahmen mit Hilfe von Regex-Ausdrücken und Zeichenfolgenfunktionen filtern. Wir werden auch lernen, wie man die filter-Funktion auf einen Pandas-Datenrahmen in Python anwendet.
Pandas DataFrame-Zeilen in Python filtern
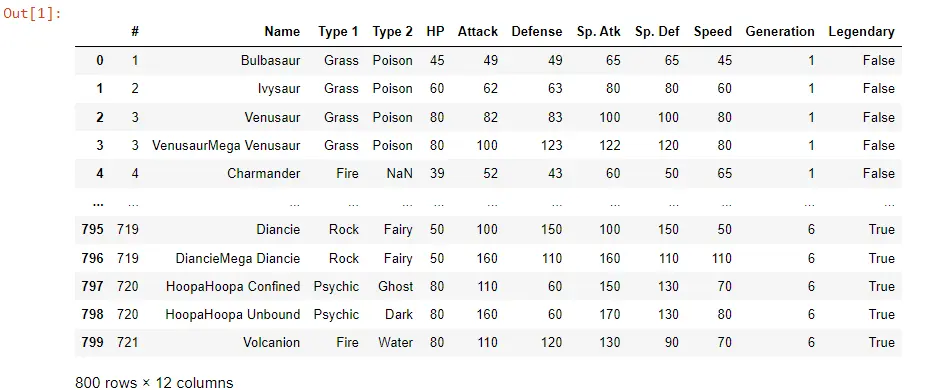
In unserem Code haben wir zuerst pandas importiert. Dann importierten wir die pokemon_data aus einer CSV-Datei; Die ersten 50 Original-Pokemon-Daten sind da.
Wir sehen verschiedene Informationen wie den Namen, den Typ 1, Typ 2 und die verschiedenen Attribute, die sie haben, wie Spezialangriffe, Geschwindigkeit und so weiter.
import pandas as pd
POK_Data = pd.read_csv("pokemon_data.csv")
POK_Data
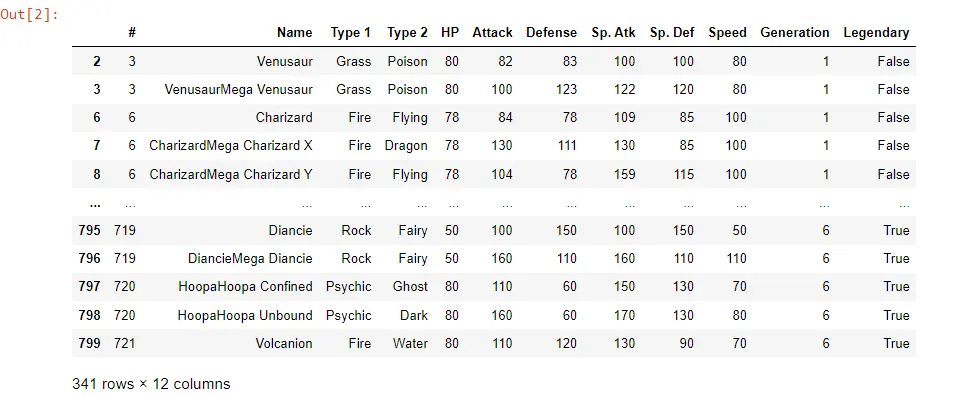
Es gibt verschiedene Optionen, um den Datenrahmen zu filtern, aber wir möchten die Zeilen filtern oder alle Pokémon mit einer Instanz behalten. Wir könnten dies für einen Angriff über 80 mit dem folgenden Code tun.
PK_Filtered_Data = POK_Data[POK_Data["Attack"] > 80]
PK_Filtered_Data
Zum Filtern verwenden wir Klammern. Wir möchten basierend auf der Spalte filtern; In diesem Fall wäre unsere Spalte Angriff.
Dadurch haben wir alle Daten größer als 80. Wenn wir dies ausführen, können wir sehen, dass wir jetzt einen anderen Datenrahmen haben.
Wenn wir uns die Spalte Angriff ansehen, sehen wir, dass alle jetzt über 80 liegen. Wir speichern den gefilterten Datenrahmen in einer anderen Variablen namens PK_Filtered_Data.
Pandas DataFrame-Zeilen nach Regex filtern
Wir können dies auch für andere Säulen tun oder dies für mehrere Säulen kombinieren. Angenommen, wir filtern die Daten größer als 80 unter der Spalte Attack und filtern gleichzeitig die Sp. Atk über 100 liegen.
Wir müssen die Klammern nicht verwenden. Eine weitere Möglichkeit besteht darin, den Datenrahmen mit POK_Data[POK_Data.Attack>80] zu filtern.
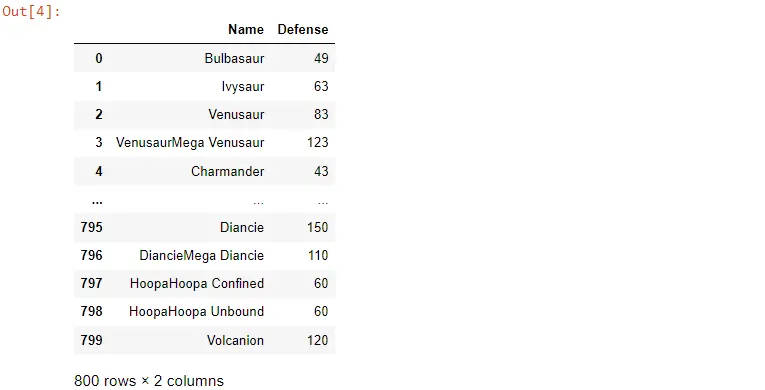
Wir können den Datenrahmen auch mit der Funktion filter() filtern und die Regex anwenden.
Reguläre Ausdrücke können die Spalten eines Datenrahmens mit der Funktion filter() filtern. Wir spezifizieren die regulären Ausdrücke mit dem Parameter regex in dieser Funktion.
Wir übergeben einen Wert an regex, um alle Spalten zu behalten, die mit dem Buchstaben e enden, und das Dollarzeichen bedeutet, dass wir die Spalten filtern, deren Namen mit e enden. Da wir uns auf Spaltenebene befinden, müssen wir auch angeben, dass die Achse gleich 1 ist.
POK_Data.filter(regex="e$", axis=1)
Es wird der vollständige Datenrahmen zurückgegeben, aber nur die Spalten, die mit e enden.
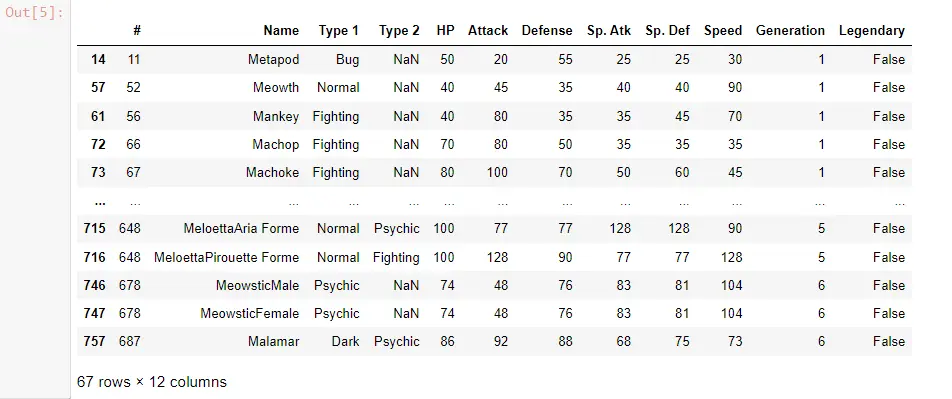
In diesem Fall filtern wir die Zeilen mit einem Name, der mit M beginnt, während wir einen regulären Ausdruck anwenden.
POK_Data[POK_Data["Name"].str.contains("^M")]
Filtern Sie Pandas DataFrame-Zeilen nach Zeichenfolge
Wir können die Zeilen des Datenrahmens auch mit regulären Ausdrücken filtern. Der obige Code funktioniert nicht genau so, da wir die spezifische Spalte angeben müssten. Wenn wir den Datenrahmen filtern wollen, verwenden wir die Funktion contains().
In diesem Fall wird der Datenrahmenfilter auf Name angewendet, und innerhalb der Funktion contains() übergeben wir ur als String. Wir verwenden die Funktion str(), weil contains() hier eigentlich eine Funktion ist, die auf Stringwerten basiert, und POK_Data['Name'] selbst eine Pandas-Serie ist.
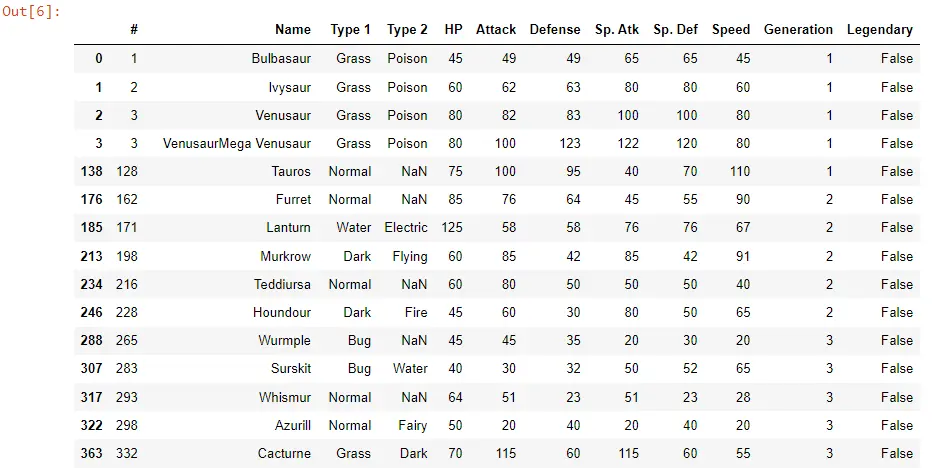
POK_Data[POK_Data["Name"].str.contains("ur")]
Wenn wir das jetzt ausführen, sehen wir, dass nur wenige Pokémon ur enthalten.
Vollständiger Python-Code:
# In[1]:
import pandas as pd
POK_Data = pd.read_csv("pokemon_data.csv")
POK_Data
# In[ ]:
# In[2]:
# PK_Filtered_Data= POK_Data[POK_Data['Attack'] >80]
# PK_Filtered_Data
# In[3]:
# PK_Filtered_Data= POK_Data[POK_Data.Attack>80]
# PK_Filtered_Data
# In[4]:
# POK_Data.filter(regex='e$',axis=1)
# In[5]:
POK_Data[POK_Data["Name"].str.contains("^M")]
# In[6]:
POK_Data[POK_Data["Name"].str.contains("ur")]
Lesen Sie weitere Lösungen hier.

Hello! I am Salman Bin Mehmood(Baum), a software developer and I help organizations, address complex problems. My expertise lies within back-end, data science and machine learning. I am a lifelong learner, currently working on metaverse, and enrolled in a course building an AI application with python. I love solving problems and developing bug-free software for people. I write content related to python and hot Technologies.
LinkedIn