Funzione Pandas DataFrame DataFrame.to_csv()
-
Sintassi di
pandas.DataFrame.to_csv() -
Codici di esempio:
DataFrame.to_csv() -
Codici di esempio:
DataFrame.to_csv()per specificare un separatore per i dati CSV -
Codici di esempio:
DataFrame.to_csv()per selezionare poche colonne e rinominare le colonne
La funzione Python Pandas DataFrame.to_csv() salva i valori contenuti nelle righe e nelle colonne di un DataFrame in un file CSV. Possiamo anche convertire un DataFrame in una stringa CSV.
Sintassi di pandas.DataFrame.to_csv()
DataFrame.to_csv(
path_or_buf=None,
sep=",",
na_rep="",
float_format=None,
columns=None,
header=True,
index=True,
index_label=None,
mode="w",
encoding=None,
compression="infer",
quoting=None,
quotechar='""',
line_terminator=None,
chunksize=None,
date_format=None,
doublequote=True,
escapechar=None,
decimal=".",
)
Parametri
Questa funzione ha diversi parametri. I valori di default di tutti i parametri sono menzionati sopra.
path_or_buf |
È una stringa o un file handle. Rappresenta il nome di un file o di un oggetto file. Se il suo valore è Nessuno, il DataFrame viene convertito in una stringa CSV. |
sep |
È una stringa. Rappresenta il separatore utilizzato nel file CSV. |
na_rep |
È una stringa. Rappresenta i dati mancanti. |
float_format |
È una stringa. Rappresenta il formato per i numeri in virgola mobile. |
columns |
È una sequenza. Rappresenta le colonne del DataFrame che verranno salvate nel file CSV. |
header |
È un valore booleano o una lista di stringhe. Se il suo valore è impostato su False, i nomi delle colonne non vengono salvati nel file CSV. Se viene passato una lista di stringhe, queste vengono salvate come nomi di colonna. |
index |
È un valore booleano. Se il suo valore è True, vengono salvati i nomi delle righe, ovvero l’indice. |
index_label |
È una stringa o una sequenza. Rappresenta il nome della colonna per un indice specifico. |
mode |
È una stringa. Rappresenta la modalità del processo. Dato che stiamo scrivendo un DataFrame in un file CSV, il suo valore è la modalità di scrittura Python w. |
encoding |
È una stringa. Rappresenta lo schema di codifica da utilizzare nel file CSV. Lo schema di codifica predefinito è utf-8. |
compression |
È una stringa o un dizionario. Se è una stringa, rappresenta la modalità di compressione. Se è un dizionario, il valore nel method rappresenta la modalità di compressione. Esistono diverse modalità di compressione. Puoi controllare qui. |
quoting |
Rappresenta una costante da un modulo CSV. |
quotechar |
È una stringa. Ha una lunghezza di 1. Rappresenta il carattere utilizzato per citare i campi. |
line_terminator |
È una stringa. Rappresenta il carattere per una nuova riga nel file CSV. |
chunksize |
È un numero intero. Rappresenta il numero di righe da scrivere nel file CSV alla volta. |
date_format |
È una stringa. Rappresenta il formato per gli oggetti DateTime. |
doublequote |
È un valore booleano. Controlla la citazione di quotechar. |
escapechar |
È una stringa. Ha una lunghezza di 1. Rappresenta il carattere usato per uscire da sep e quotechar. |
decimal |
È una stringa. Rappresenta il carattere utilizzato per il punto decimale. |
Ritorno
Restituisce None o una stringa. Se path_or_buf è Nessuno, converte DataFrame in una stringa e restituisce la stringa. In caso contrario, restituisce None.
Codici di esempio: DataFrame.to_csv()
Implementeremo questa funzione in modi diversi nei prossimi codici.
import pandas as pd
dataframe=pd.DataFrame({
'Attendance':
{0: 60,
1: 100,
2: 80,
3: 78,
4: 95},
'Name':
{0: 'Olivia',
1: 'John',
2: 'Laura',
3: 'Ben',
4: 'Kevin'},
'Obtained Marks':
{0: 90,
1: 75,
2: 82,
3: 64,
4: 45}
})
print(dataframe)
L’esempio DataFrame è,
Attendance Name Obtained Marks
0 60 Olivia 90
1 100 John 75
2 80 Laura 82
3 78 Ben 64
4 95 Kevin 45
Tutti i parametri di questa funzione sono opzionali. Se eseguiamo questa funzione senza passare alcun parametro, produce il seguente output.
import pandas as pd
dataframe = pd.DataFrame(
{
"Attendance": {0: 60, 1: 100, 2: 80, 3: 78, 4: 95},
"Name": {0: "Olivia", 1: "John", 2: "Laura", 3: "Ben", 4: "Kevin"},
"Obtained Marks": {0: 90, 1: 75, 2: 82, 3: 64, 4: 45},
}
)
csvstring = dataframe.to_csv()
print(csvstring)
Produzione:
,Attendance,Name,Obtained Marks
0,60,Olivia,90
1,100,John,75
2,80,Laura,82
3,78,Ben,64
4,95,Kevin,45
La funzione ha prodotto l’output utilizzando tutti i valori di default. Ha restituito una stringa CSV. Ora salveremo i dati nel file CSV.
import pandas as pd
dataframe = pd.DataFrame(
{
"Attendance": {0: 60, 1: 100, 2: 80, 3: 78, 4: 95},
"Name": {0: "Olivia", 1: "John", 2: "Laura", 3: "Ben", 4: "Kevin"},
"Obtained Marks": {0: 90, 1: 75, 2: 82, 3: 64, 4: 45},
}
)
returnValue = dataframe.to_csv("myfile.csv")
print(returnValue)
Produzione:
None
La funzione ha creato un nuovo file CSV nella directory in cui è salvato questo programma.
Codici di esempio: DataFrame.to_csv() per specificare un separatore per i dati CSV
import pandas as pd
dataframe = pd.DataFrame(
{
"Attendance": {0: 60, 1: 100, 2: 80, 3: 78, 4: 95},
"Name": {0: "Olivia", 1: "John", 2: "Laura", 3: "Ben", 4: "Kevin"},
"Obtained Marks": {0: 90, 1: 75, 2: 82, 3: 64, 4: 45},
}
)
returnValue = dataframe.to_csv(sep="@")
print(returnValue)
Produzione:
@Attendance@Name@Obtained Marks
0@60@Olivia@90
1@100@John@75
2@80@Laura@82
3@78@Ben@64
4@95@Kevin@45
Codici di esempio: DataFrame.to_csv() per selezionare poche colonne e rinominare le colonne
import pandas as pd
dataframe = pd.DataFrame(
{
"Attendance": {0: 60, 1: 100, 2: 80, 3: 78, 4: 95},
"Name": {0: "Olivia", 1: "John", 2: "Laura", 3: "Ben", 4: "Kevin"},
"Obtained Marks": {0: 90, 1: 75, 2: 82, 3: 64, 4: 45},
}
)
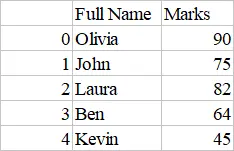
returnValue = dataframe.to_csv(
"myfile.csv", columns=["Name", "Obtained Marks"], header=["Full Name", "Marks"]
)
print(returnValue)
Produzione:
None
Proprio come i codici sopra, possiamo personalizzare il nostro file CSV utilizzando diversi parametri. Questa funzione fornisce diversi parametri da utilizzare.