How to Delete Duplicate Rows in MySQL
-
Delete Duplicate Rows Using the
DELETE JOINStatement - Delete Duplicate Rows Using Nested Query
- Delete Duplicate Rows Using a Temporary Table
-
Delete Duplicate Rows Using the
ROW_NUMBER()Function
This article will show you the numerous ways to delete duplicate rows present in the table in MySQL. There are four different approaches to accomplishing this task.
- Delete Duplicate rows using the
DELETE JOINstatement - Delete Duplicate rows using Nested Query
- Delete Duplicate rows using a temporary table
- Delete Duplicate rows using
ROW_NUMBER()Function
The following script creates a table customers with four columns (custid, first_name, last_name, and email).
CREATE TABLE customers (custid INT, first_name VARCHAR(50) NOT NULL, last_name VARCHAR(50) NOT NULL, email VARCHAR(255) NOT NULL );
CREATE TABLE customers (custid INT, first_name VARCHAR(50) NOT NULL, last_name VARCHAR(50) NOT NULL, email VARCHAR(255) NOT NULL );
Insert sample data values into the customers table for the demonstration.
INSERT INTO customers
VALUES (110,'Susane','Mathew','sussane.mathew@gmail.com'),
(124,'Jean','Carl','jean.carl@gmail.com'),
(331,'Peter','cohelo','peter.coh@google.com'),
(114,'Jaine','Lora','jaine.l@abs.com'),
(244,'Junas','sen','jonas.sen@mac.com');
INSERT INTO customers
VALUES (113,'Jaine','Lora','jaine.l@abs.com'),
(111,'Susane','Mathew','sussane.mathew@gmail.com'),
(665,'Roma','Shetty','roma.sh11@yahoo.com'),
(997,'Beatrice','shelon','beatrice.ss22@yahoo.com'),
(332,'Peter','cohelo','peter.coh@google.com');
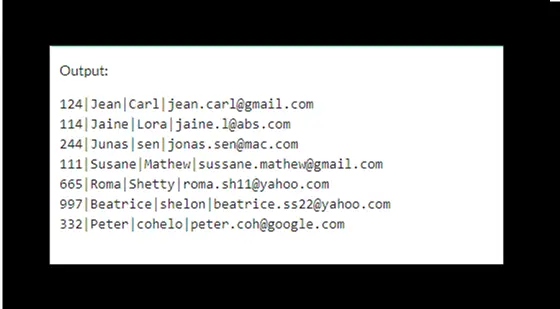
Below is the given query that returns all data from the customers table:
SELECT * FROM customers order by custid;
To look for the duplicate records from the table, we will execute the query mentioned below in the customers table.
SELECT custid, COUNT(custid) FROM customers GROUP BY custid HAVING COUNT(custid) > 1;
As you can see, we have three rows with duplicate customer id in our results.
Delete Duplicate Rows Using the DELETE JOIN Statement
Using INNER JOIN with the Delete statement allows you to remove duplicate rows from your table in MySQL.
The following query uses the concept of the nested query by selecting all the rows that have duplicate records with the lowest customer id. Once found, we will then delete these duplicate records with the lowest custid:
Delete from customers where custid IN (Select c1.custid FROM customers as c1
INNER JOIN customers as c2 ON c1.custid < c2.custid AND c1.email = c2.email);
The customer table is referenced twice in this query; therefore, it uses the alias c1 and c2.
The output will be:
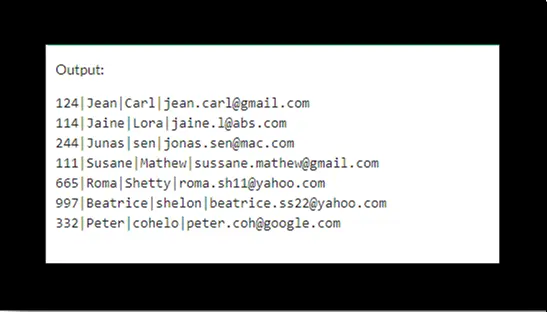
It indicated that three rows had been deleted.
SELECT custid, COUNT(custid) FROM customers GROUP BY custid HAVING COUNT(custid) > 1;
Now, this query returns an empty set, which means that the duplicate rows have been deleted.
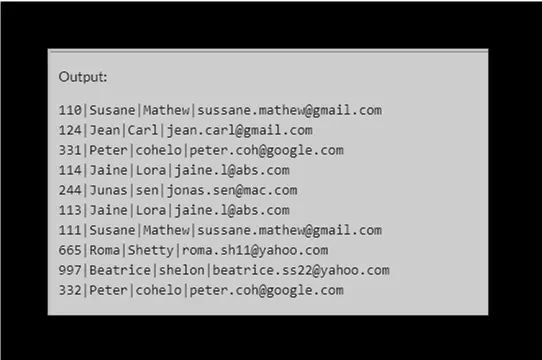
We can verify the data from the customers table using the select query:
SELECT * FROM customers;
In case you wish to delete duplicate rows and keep the lowest custid, then you can use the same query but with slight variation in the condition as shown in the following statement:
Delete from customers where custid IN (Select c1.custid FROM customers as c1
INNER JOIN customers as c2 ON c1.custid > c2.custid AND c1.email = c2.email);
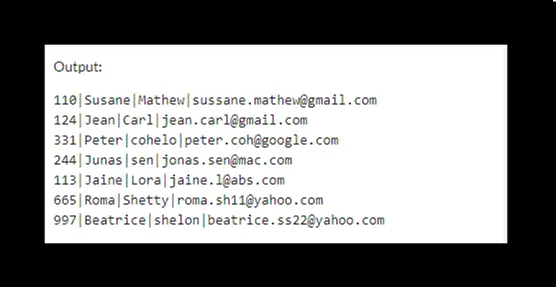
The following output shows the data of the customers table after removing duplicate rows.
Delete Duplicate Rows Using Nested Query
Let us now have a look at the step-by-step procedure to remove duplicate rows using a nested query. This is a comparatively straightforward approach to solving the problem.
Firstly, we will select unique records from the table using this query.
Select * from (select max(custid) from customers group by email);
Then we will use the delete query with where clause, as shown below, to delete duplicate rows in the table.
Delete from customers where custid not in
(select * from (select max(custid) from customers group by email));
The output will be:
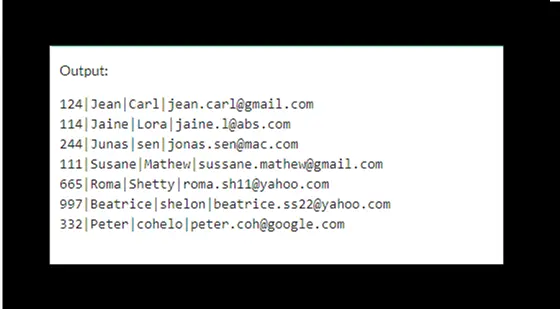
Delete Duplicate Rows Using a Temporary Table
Let us now have a look at the step by step procedure to remove duplicate rows using a temporary table:
- Firstly, you need to create a new table with the same structure as the original table.
- Now, insert distinct rows from the original table to the temporary table.
- Drop the original table and rename the temporary table to the original table.
Step 1: Table creation using CREATE TABLE and LIKE keyword
Syntax to copy the whole structure of the table is as shown below.
CREATE TABLE destination_table LIKE source;
So, assuming we have the same customer table, we will write the query given below.
CREATE TABLE temporary LIKE customers;
Step 2. Inserting rows in a temporary table
The query given below copies the unique row from the customers and writes that to a temporary table. Here, we are grouping by email.
INSERT INTO temporary SELECT * FROM customers GROUP BY email;
Step 3. Drop the original customer table and make a temporary table to act as the original table by renaming it to customers.
DROP TABLE customers;
ALTER TABLE temporary RENAME TO customers;
The output will be:
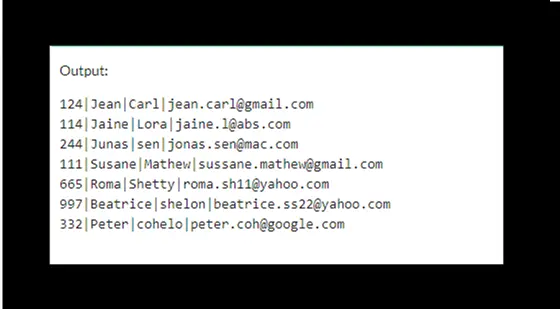
This approach is time-consuming as it requires an alteration in the table’s structure rather than just working on data values.
Delete Duplicate Rows Using the ROW_NUMBER() Function
The ROW_NUMBER() function has been introduced in MySQL version 8.02. So, You can go for this approach if you are running a MySQL version higher than 8.02.
This query assigns a numerical value to each row using the ROW_NUMBER() function. In the case of duplicate emails, the row number will be greater than one.
SELECT custid, email, ROW_NUMBER() OVER ( PARTITION BY email ORDER BY email ) AS row FROM customers;
The code snippet above returns an id list of the duplicate rows:
SELECT custid
FROM ( SELECT custid, ROW_NUMBER() OVER (PARTITION BY email ORDER BY email) AS row FROM customers) t WHERE row > 1;
Once we get the list of customers with duplicate values, we can delete this using the delete statement with subquery in the where clause as shown below.
DELETE FROM customers
WHERE custid IN
(SELECT custid FROM
(SELECT custid, ROW_NUMBER() OVER
(PARTITION BY email ORDER BY email) AS row FROM customers) t
WHERE row > 1);
The output will be: