Eliminar filas duplicadas en MySQL
-
Eliminar filas duplicadas mediante la instrucción
DELETE JOIN - Eliminar filas duplicadas mediante consulta anidada
- Eliminar filas duplicadas mediante una tabla temporal
-
Eliminar filas duplicadas con la función
ROW_NUMBER()
Este artículo le mostrará las numerosas formas de eliminar filas duplicadas presentes en la tabla en MySQL. Hay cuatro enfoques diferentes para realizar esta tarea.
- Elimine filas duplicadas usando la declaración
DELETE JOIN - Elimina filas duplicadas mediante consulta anidada.
- Elimina filas duplicadas con una tabla temporal.
- Elimine filas duplicadas usando la función
ROW_NUMBER()
El siguiente script crea una tabla customers con cuatro columnas (custid, first_name, last_name y email).
CREATE TABLE customers (custid INT, first_name VARCHAR(50) NOT NULL, last_name VARCHAR(50) NOT NULL, email VARCHAR(255) NOT NULL );
CREATE TABLE customers (custid INT, first_name VARCHAR(50) NOT NULL, last_name VARCHAR(50) NOT NULL, email VARCHAR(255) NOT NULL );
Inserte valores de datos de muestra en la tabla customers para la demostración.
INSERT INTO customers
VALUES (110,'Susane','Mathew','sussane.mathew@gmail.com'),
(124,'Jean','Carl','jean.carl@gmail.com'),
(331,'Peter','cohelo','peter.coh@google.com'),
(114,'Jaine','Lora','jaine.l@abs.com'),
(244,'Junas','sen','jonas.sen@mac.com');
INSERT INTO customers
VALUES (113,'Jaine','Lora','jaine.l@abs.com'),
(111,'Susane','Mathew','sussane.mathew@gmail.com'),
(665,'Roma','Shetty','roma.sh11@yahoo.com'),
(997,'Beatrice','shelon','beatrice.ss22@yahoo.com'),
(332,'Peter','cohelo','peter.coh@google.com');
Nota: Puede usar esto para insertar valores nuevamente después de la eliminación.
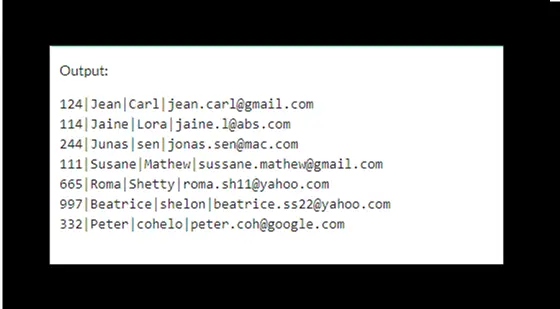
A continuación se muestra la consulta dada que devuelve todos los datos de la tabla customers:
SELECT * FROM customers order by custid;
Para buscar los registros duplicados de la tabla, ejecutaremos la consulta que se menciona a continuación en la tabla customers.
SELECT custid, COUNT(custid) FROM customers GROUP BY custid HAVING COUNT(custid) > 1;
Como puede ver, tenemos tres filas con una identificación de cliente duplicada en nuestros resultados.
Eliminar filas duplicadas mediante la instrucción DELETE JOIN
El uso de INNER JOIN con la sentencia Delete le permite eliminar filas duplicadas de su tabla en MySQL.
La siguiente consulta utiliza el concepto de consulta anidada seleccionando todas las filas que tienen registros duplicados con el ID de cliente más bajo. Una vez encontrados, borraremos estos registros duplicados con el custid más bajo:
Delete from customers where custid IN (Select c1.custid FROM customers as c1
INNER JOIN customers as c2 ON c1.custid < c2.custid AND c1.email = c2.email);
Se hace referencia a la tabla de clientes dos veces en esta consulta; por lo tanto, usa el alias c1 y c2.
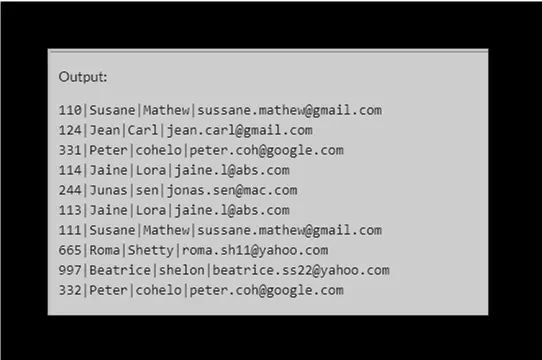
La salida será:
Indicó que se habían eliminado tres filas.
SELECT custid, COUNT(custid) FROM customers GROUP BY custid HAVING COUNT(custid) > 1;
Ahora, esta consulta devuelve un conjunto vacío, lo que significa que las filas duplicadas se han eliminado.
Podemos verificar los datos de la tabla customers mediante la consulta seleccionar:
SELECT * FROM customers;
En caso de que desee eliminar filas duplicadas y mantener el custid más bajo, puede usar la misma consulta pero con una ligera variación en la condición, como se muestra en la siguiente declaración:
Delete from customers where custid IN (Select c1.custid FROM customers as c1
INNER JOIN customers as c2 ON c1.custid > c2.custid AND c1.email = c2.email);
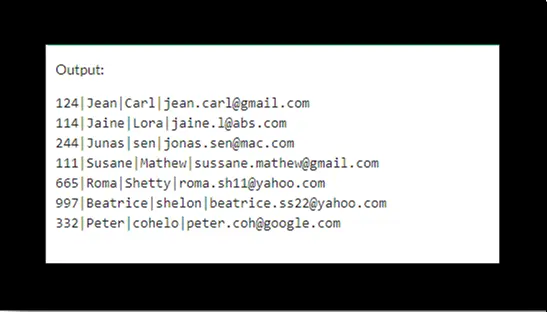
El siguiente resultado muestra los datos de la tabla customers después de eliminar filas duplicadas.
Eliminar filas duplicadas mediante consulta anidada
Echemos ahora un vistazo al procedimiento paso a paso para eliminar filas duplicadas mediante una consulta anidada. Este es un enfoque relativamente sencillo para resolver el problema.
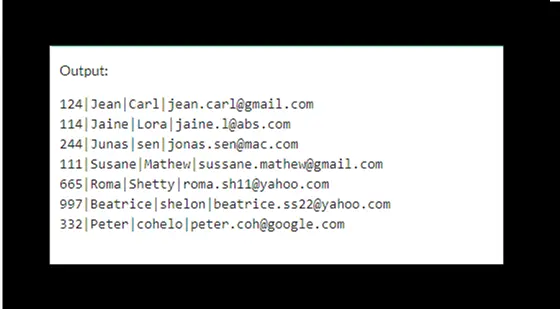
En primer lugar, seleccionaremos registros únicos de la tabla utilizando esta consulta.
Select * from (select max(custid) from customers group by email);
Luego usaremos la consulta Delete con la cláusula where, como se muestra a continuación, para eliminar filas duplicadas en la tabla.
Delete from customers where custid not in
(select * from (select max(custid) from customers group by email));
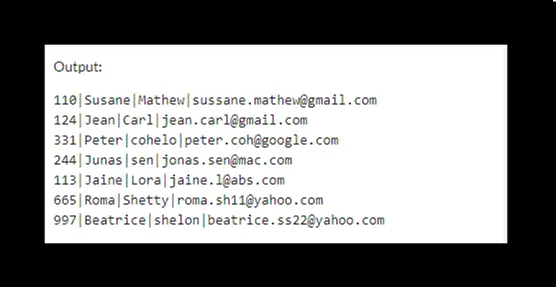
La salida será:
Eliminar filas duplicadas mediante una tabla temporal
Echemos ahora un vistazo al procedimiento paso a paso para eliminar filas duplicadas usando una tabla temporal:
- En primer lugar, debe crear una nueva tabla con la misma estructura que la tabla original.
- Ahora, inserte filas distintas de la tabla original en la tabla temporal.
- Elimine la tabla original y cambie el nombre de la tabla temporal a la tabla original.
Paso 1: creación de la tabla utilizando la palabra clave CREATE TABLE y LIKE
La sintaxis para copiar toda la estructura de la tabla es la que se muestra a continuación.
CREATE TABLE destination_table LIKE source;
Entonces, suponiendo que tengamos la misma tabla de clientes, escribiremos la consulta que se proporciona a continuación.
CREATE TABLE temporary LIKE customers;
Paso 2. Insertar filas en una tabla temporal
La consulta que se proporciona a continuación copia la fila única de los clientes y la escribe en una tabla temporal. Aquí, estamos agrupando por correo electrónico.
INSERT INTO temporary SELECT * FROM customers GROUP BY email;
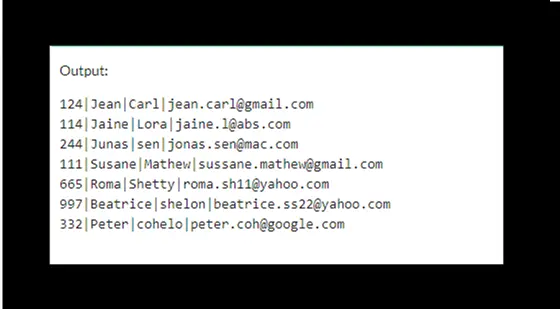
Paso 3. Suelta la mesa de cliente original y crea una mesa temporal para que actúe como la mesa original cambiándola de nombre a clientes.
DROP TABLE customers;
ALTER TABLE temporary RENAME TO customers;
La salida será:
Este enfoque requiere mucho tiempo, ya que requiere una alteración en la estructura de la tabla en lugar de simplemente trabajar con los valores de los datos.
Eliminar filas duplicadas con la función ROW_NUMBER()
La función ROW_NUMBER() se ha introducido en MySQL versión 8.02. Por lo tanto, puede optar por este enfoque si está ejecutando una versión de MySQL superior a 8.02.
Esta consulta asigna un valor numérico a cada fila usando la función ROW_NUMBER(). En el caso de correos electrónicos duplicados, el número de fila será mayor que uno.
SELECT custid, email, ROW_NUMBER() OVER ( PARTITION BY email ORDER BY email ) AS row FROM customers;
El fragmento de código anterior devuelve una lista de identificación de las filas duplicadas:
SELECT custid
FROM ( SELECT custid, ROW_NUMBER() OVER (PARTITION BY email ORDER BY email) AS row FROM customers) t WHERE row > 1;
Una vez que obtenemos la lista de clientes con valores duplicados, podemos eliminarla usando la instrucción Delete con la subconsulta en la cláusula where, como se muestra a continuación.
DELETE FROM customers
WHERE custid IN
(SELECT custid FROM
(SELECT custid, ROW_NUMBER() OVER
(PARTITION BY email ORDER BY email) AS row FROM customers) t
WHERE row > 1);
La salida será: