How to Count Records in MongoDB
- Operations in MongoDB
- Aggregate Operation in MongoDB
-
$countin MongoDB -
db.collection.count()in MongoDB - MongoDB Group by Count
- MongoDB Group by Count Sort
- MongoDB Group by Counting Multiple Fields
- MongoDB Group by Date and Count
-
.toArray()Method in MongoDB -
.itcount()in MongoDB

This article discusses operators in MongoDB, the aggregate operator, and the different methods to count total records.
Operations in MongoDB
CRUD operations are the concepts of a user interface that allow users to browse, search, and change objects in a database.
MongoDB documents are altered by connecting to a server, querying the appropriate documents, and then transforming them before sending that data back to the database to be processed. CRUD is a data-driven process that uses HTTP action verbs to standardize it.
Create- used to insert new documents in the MongoDB database.Read- used to query a document in the database.Update- used to modify existing documents in the database.Delete- removes documents in the database.
Aggregate Operation in MongoDB
It’s a data processing operation consisting of stages that perform many operations on grouped data to produce a single result. The following are three options for doing the aggregate operation.
-
Pipeline for aggregation - Documents are supplied through a multi-stage pipeline, integrating them into one output. The MongoDB aggregate process is divided into multiple stages.
An example is given below.
db.collection_name.aggregate([ //First stage { $match: { status: "" } }, //Second stage { $group: { _id: "$cust_id", total: { $sum: "$amount" } } }, //Third Stage { $sort : {sort_field: -1 }} ])
- Single Purpose Aggregation Methods - Single-purpose aggregating methods are straightforward, but they lack the power of an aggregate pipeline.
- Map-Reduce - Map-reduce operations have been deprecated since MongoDB 5.0. Instead, use an aggregate pipeline.
$count in MongoDB
Sends a document to the next step with a count of the number of records it has received.
Behavior:
The following $group + $project sequence is equal to the $count stage.
db.collection.aggregate( [
{ $group: { _id: null, myCount: { $sum: 1 } } },
{ $project: { _id: 2 } }
] )
Where myCount denotes, the output field contains the count. You can give the output field a different name.
Example:
A collection named scores has the given documents.
{ "_id" : 1, "subject" : "English", "score" : 88 }
{ "_id" : 2, "subject" : "English", "score" : 92 }
{ "_id" : 3, "subject" : "English", "score" : 97 }
{ "_id" : 4, "subject" : "English", "score" : 71 }
{ "_id" : 5, "subject" : "English", "score" : 79 }
{ "_id" : 6, "subject" : "English", "score" : 83 }
The following aggregation operation has two stages.
- The
$matchstage filters out documents having ascorevalue of less than or equal to80, allowing documents with ascoregreater than80to go to the next stage. - The
$countstep calculates the number of documents left in the aggregate pipeline and stores the result in a variable namedpassing_scores.
db.scores.aggregate(
[
{
$match: {
score: {
$gt: 80
}
}
},
{
$count: "passing_scores"
}
]
)
The operation returns the following results.
{ "passing_scores" : 4 }
For getting 1000 records, this takes on average 2 ms and is the fastest way.
db.collection.count() in MongoDB
Returns the number of records in the collection or view that would match a find() query. The db.collection.count() function counts and provides the number of results matching a query rather than the find() procedure.
Behavior:
In transactions, you can’t use count or the shell tools count() and db.collection.count().
Sharded Clusters
If orphaned documents exist or a chunk migration is in process, using db.collection.count() without a query predicate on a sharded cluster might result in an erroneous count.
Use the db.collection.aggregate() function on a sharded cluster to prevent these situations.
To count the documents, use the $count step. The following procedure, for example, counts the documents in a collection.
db.collection.aggregate( [
{ $count: "myCount" }
])
The $count stage is equal to the following $group + $project sequence.
db.collection.aggregate( [
{ $group: { _id: null, count: { $sum: 1 } } }
{ $project: { _id: 0 } }
] )
Index Use
Consider a collection with the following index.
{ a: 1, b: 1 }
When conducting a count, MongoDB can only use the index to return the count if the query:
- can use an index,
- only contains conditions on the keys of the index, and
- predicates access to a single continuous range of index keys
For example, given only the index, the following procedures can return the count.
db.collection.find( { a: 5, b: 5 } ).count()
db.collection.find( { a: { $gt: 5 } } ).count()
db.collection.find( { a: 5, b: { $gt: 10 } } ).count()
Suppose the query may utilize an index, but the predicates do not reach a single continuous range of index keys. The query also has conditions on fields outside the index.
In that case, MongoDB must read the documents in addition to utilizing the index to provide the count.
db.collection.find( { a: 6, b: { $in: [ 1, 2, 3 ] } } ).count()
db.collection.find( { a: { $gt: 6 }, b: 5 } ).count()
db.collection.find( { a: 5, b: 5, c: 8 } ).count()
In such circumstances, MongoDB pages the documents into memory during the initial read, improving the speed of subsequent calls to the same count operation.
Accuracy in the Event of an Unexpected Shutdown
Count statistics supplied by count() may be erroneous after an unclean shutdown of a mongod utilizing the Wired Tiger storage engine.
Between the last checkpoint and the unclean shutdown, the number of inserts, update, or delete operations executed determines the amount of drift.
Checkpoints happen every 60 seconds on average. mongod instances with non-default -syncdelay options, on the other hand, may have more or fewer checkpoints.
To restore statistics after an unclean shutdown, run validate on each collection on the mongod.
After an unclean shutdown:
validateupdates the count statistic in thecollStatsoutput with the latest value.- Other statistics like the number of documents inserted or removed in the
collStatsoutput are estimates.
Disconnection of Client
Starting in MongoDB 4.2, if the client who issued db.collection.count() disconnects before the operation completes, MongoDB marks db.collection.count() for termination using killOp.
Count All Documents in a Collection
To count the number of all records in the orders collection, use the following operation.
db.orders.count()
This operation is equivalent to the following.
db.orders.find().count()
Count All Documents that Match a Query
Count how many documents in the orders collection have the field ord_dt that is larger than new Date('01/01/2012').
db.orders.count( { ord_dt: { $gt: new Date('01/01/2012') } } )
The query is equivalent to the following.
db.orders.find( { ord_dt: { $gt: new Date('01/01/2012') } } ).count()
MongoDB Group by Count
The _id column of each document in MongoDB has been allocated a unique group by value. The aggregate technique then processes the data, which produces computed outcomes.
The following is an example. The database setup may be viewed here.
This setting will be utilized in all of the code samples presented in this article.
db={
"data": [
{
"_id": ObjectId("611a99100a3322fc1bd8c38b"),
"fname": "Tom",
"city": "United States of America",
"courses": [
"c#",
"asp",
"node"
]
},
{
"_id": ObjectId("611a99340a3322fc1bd8c38c"),
"fname": "Harry",
"city": "Canada",
"courses": [
"python",
"asp",
"node"
]
},
{
"_id": ObjectId("611a99510a3322fc1bd8c38d"),
"fname": "Mikky",
"city": "New Zealand",
"courses": [
"python",
"asp",
"c++"
]
},
{
"_id": ObjectId("611b3e88a60b5002406571c3"),
"fname": "Ron",
"city": "United Kingdom",
"courses": [
"python",
"django",
"node"
]
}
]
}
Query for above database used is:
db.data.aggregate([
{
$group: {
_id: "ObjectId",
count: {
$count: {}
}
}
}
])
The link for the above execution is given to see the working of this code segment.
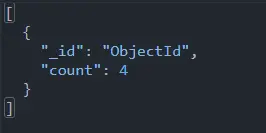
MongoDB Group by Count Sort
In this section, $sortByCount is used, which is the same as $group + $sort. It can sort and count a group of people in ascending and descending order.
An example query is given below. Some documents have been added to the data collection in this example, and the find() method is used to determine how many entries it contains.
The following will be the query for find().
db.data.find()
You can access the execution of this query from this link.
The next step is to undo the array of courses and use the $sortByCount function to count the number of records added to each course.
db.data.aggregate([
{
$unwind: "$courses"
},
{
$sortByCount: "$courses"
}
])
The link is given here to see the working of this query with the above database configuration. This is the most straightforward approach to the MongoDB group by counting the array and sorting it.
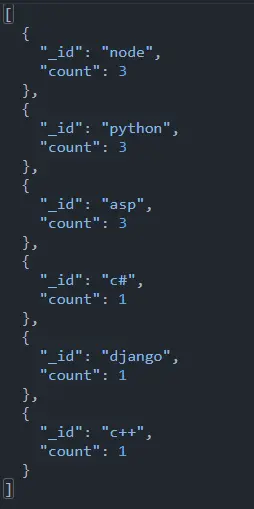
MongoDB Group by Counting Multiple Fields
MongoDB’s aggregate() function may count several fields. As a result, the fields are counted using $count.
Below is an example where a timestamp is utilized for only one entry. Some documents can be saved in the student collection in this example, and you can use the find() method to see how many documents you have.
db.student.aggregate([ {$group: {_id: {name:"$name",
timestamp:"$timestamp" }}},
{$count:"timestamp"}
])
The execution of this query can be accessed in this link.
MongoDB Group by Date and Count
When you need to count a specific date document, you may utilize count aggregation and count a specific date document.
Here’s an illustration. In this example, you’ll learn to calculate the overall selling amount and sale count for each day in 2021.
You may include product id, item name, price, quantity, and date fields in the sales collection. The documents may be obtained using the find() method.
db=
{
"_id" : 1,
"item" : "abc",
"price" : NumberDecimal("10"),
"quantity" : 2,
"date" : ISODate("2021-03-01T08:00:00Z")
}
{
"_id" : 2,
"item" : "jkl",
"price" : NumberDecimal("20"),
"quantity" : 1,
"date" : ISODate("2021-03-01T09:00:00Z")
}
{
"_id" : 3,
"item" : "xyz",
"price" : NumberDecimal("5"),
"quantity" : 10,
"date" : ISODate("2021-03-15T09:00:00Z")
}
{
"_id" : 4,
"item" : "xyz",
"price" : NumberDecimal("5"),
"quantity" : 20,
"date" : ISODate("2021-04-04T11:21:39.736Z")
}
{
"_id" : 5,
"item" : "abc",
"price" : NumberDecimal("10"),
"quantity" : 10,
"date" : ISODate("2021-04-04T21:23:13.331Z")
}
Query for above configuration will be:
db.date.aggregate([
{
$match : { "date": { $gte: new ISODate("2021-01-01"), $lt: new ISODate("2015-01-01") } }
},
{
$group : {
_id : { $dateToString: { format: "%Y-%m-%d", date: "$date" } },
totalSaleAmount: { $sum: { $multiply: [ "$price", "$quantity" ] } },
count: { $sum: 1 }
}
},
{
$sort : { totalSaleAmount: -1 }
}
])
Now queries for a single field and multiple field groups are given below using count and field commands.
-
Single field group by and count
db.Request.aggregate([{'$group': {_id: '$source', count: {$sum: 1}}}])
-
Multiple fields group by and count
db.Request.aggregate([ {'$group': {_id: {source: '$source', status: '$status'}, count: {$sum: 1}}} ]) -
Multiple fields group by and count with sort using field
db.Request.aggregate([ {'$group': {_id: {source: '$source', status: '$status'}, count: {$sum: 1}}}, {$sort: {'_id.source': 1}} ]) -
Multiple fields group by and count with sort using count
db.Request.aggregate([ {'$group': {_id: {source: '$source', status: '$status'}, count: {$sum: 1}}}, {$sort: {'count': -1}} ])
.toArray() Method in MongoDB
The toArray() function returns an array containing all the documents in a cursor. The procedure loops through the cursor many times, loading all the documents into RAM and depleting the pointer.
Consider the following example, which uses the toArray() function to transform the cursor returned by the find() method.
var allProductsArray = db.products.find().toArray();
if (allProductsArray.length > 0) {
printjson(allProductsArray[0]);
}
The variable allProductsArray holds the array of documents returned by toArray(). For getting 1000 records, this takes, on average, 18 ms.
.itcount() in MongoDB
Counts how many documents are left in a cursor.
itcount() is similar to the cursor.count(), but instead of running the query on a new iterator, it executes it on an existing one, exhausting its contents.
The prototype form of the itcount() method is as follows.
db.collection.find(<query>).itcount()
For getting 1000 records, this takes, on average, 14 ms.
This article discussed operations in detail, and the aggregate operation was also discussed. First, different types of aggregate functions were discussed briefly with code segments.
Then group by and the count was discussed in which sorting, finding, and multiple fields were discussed. Then different ways to count the records in MongoDB are discussed.