Lineare Regression in Python
- Was ist Regression?
- Was ist lineare Regression?
- Implementierung der einfachen linearen Regression in Python
- Implementierung der multiplen Regression in Python
In diesem Artikel werden wir die lineare Regression diskutieren und sehen, wie die lineare Regression verwendet wird, um Ergebnisse vorherzusagen. Wir werden auch einfache lineare Regression und multiple Regression in Python implementieren.
Was ist Regression?
Regression ist der Prozess der Identifizierung von Beziehungen zwischen unabhängigen Variablen und abhängigen Variablen. Es wird zur Vorhersage von Immobilienpreisen, Gehältern von Mitarbeitern und anderen Prognoseanwendungen verwendet.
Wenn wir die Hauspreise vorhersagen wollen, können die unabhängigen Variablen das Alter des Hauses, die Anzahl der Schlafzimmer, die Entfernung von zentralen Stadtstandorten wie Flughäfen, Märkten usw. umfassen. Hier hängt der Preis des Hauses von diesen unabhängigen Variablen ab. Daher ist der Hauspreis eine abhängige Variable.
Wenn wir das Gehalt von Angestellten vorhersagen wollen, könnten die unabhängigen Variablen ihre Erfahrung in Jahren, ihr Bildungsniveau, ihre Lebenshaltungskosten am Wohnort usw. sein. Hier ist die abhängige Variable das Gehalt der Angestellten.
Mit der Regression versuchen wir, ein mathematisches Modell zu erstellen, das beschreibt, wie die unabhängigen Variablen die abhängigen Variablen beeinflussen. Das mathematische Modell sollte die abhängige Variable mit dem geringsten Fehler vorhersagen, wenn Werte für unabhängige Variablen bereitgestellt werden.
Was ist lineare Regression?
Bei der linearen Regression wird angenommen, dass die unabhängigen und abhängigen Variablen linear zusammenhängen.
Angenommen, wir erhalten N unabhängige Variablen wie folgt.
Jetzt müssen wir eine lineare Beziehung wie die folgende Gleichung finden.
Hier,
- Wir müssen die Konstanten
Aidurch lineare Regression identifizieren, um die abhängige VariableF(X)mit minimalen Fehlern vorherzusagen, wenn die unabhängigen Variablen gegeben sind. - Die Konstanten Ai werden als vorhergesagte Gewichte oder Schätzer der Regressionskoeffizienten bezeichnet.
- F(X) wird die vorhergesagte Antwort oder die geschätzte Antwort der Regression genannt. Für ein gegebenes
X=( X1, X2, X3, X4, X5, X6, X7……, XN)sollteF(X)einen Wert ergeben, der möglichst nahe an der eigentlichen abhängigen Variablen Y liegt für die gegebene unabhängige Variable X. - Um die Funktion F(X) zu berechnen, die zum Schluss von Y ausgewertet wird, minimieren wir normalerweise den quadratischen Mittelwert der Differenz zwischen F(X) und Y für gegebene Werte von X.
Implementierung der einfachen linearen Regression in Python
Bei der einfachen Regression gibt es nur eine unabhängige Variable und eine abhängige Variable. Die vorhergesagte Antwort kann also wie folgt geschrieben werden.
Um die einfache lineare Regression in Python zu implementieren, benötigen wir einige tatsächliche Werte für X und ihre entsprechenden Y-Werte. Mit diesen Werten können wir die vorhergesagten Gewichte A0 und A1 mathematisch oder mithilfe der in Python bereitgestellten Funktionen berechnen.
Angenommen, wir erhalten zehn Werte für X in Form eines Arrays wie folgt.
X = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
Außerdem werden die entsprechenden Y-Werte wie folgt angegeben.
Y = [2, 4, 3, 6, 8, 9, 9, 10, 11, 13]
Um die Regressionsgleichung F(X) zu finden, können wir das Modul linear_model aus der Machine-Learning-Bibliothek scikit-learn verwenden. Sie können die Bibliothek scikit-learn installieren, indem Sie den folgenden Befehl in der Eingabeaufforderung Ihres Computers ausführen.
pip3 install scikit-learn
Das Modul linear_model der Bibliothek scikit-learn stellt uns die Methode LinearRegression() zur Verfügung, mit der wir die vorhergesagte Antwort finden können. Die Methode LinearRegression() gibt bei Ausführung ein lineares Modell zurück. Wir können dieses lineare Modell trainieren, um F(X) zu finden. Dazu verwenden wir die Methode fit().
Die fit()-Methode akzeptiert, wenn sie auf einem linearen Modell aufgerufen wird, das Array von unabhängigen Variablen X als ihr erstes Argument und das Array von abhängigen Variablen Y als ihr zweites Eingabeargument. Nach der Ausführung werden die Parameter des linearen Modells so angepasst, dass das Modell F(X) repräsentiert. Sie finden die Werte für A0 und A1 mit den Attributen intercept_ bzw. coef_, wie unten gezeigt.
from sklearn import linear_model
import numpy as np
X = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]).reshape(-1, 1)
Y = [2, 4, 3, 6, 8, 9, 9, 10, 11, 13]
lm = linear_model.LinearRegression()
lm.fit(X, Y) # fitting the model
print("The coefficient is:", lm.coef_)
print("The intercept is:", lm.intercept_)
Ausgabe:
The coefficient is: [1.16969697]
The intercept is: 1.0666666666666664
Hier sehen Sie, dass der Koeffizientenwert A1 1,16969697 und der Schnittpunktwert A0 1,0666666666666664 ist.
Nach der Implementierung des linearen Regressionsmodells können Sie den Wert von Y für jedes X mit der Methode predict() vorhersagen. Wenn sie für ein Modell aufgerufen wird, nimmt die Methode predict() die unabhängige Variable X als Eingabeargument und gibt den vorhergesagten Wert für die abhängige Variable Y zurück, wie im folgenden Beispiel gezeigt.
from sklearn import linear_model
import numpy as np
X = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]).reshape(-1, 1)
Y = [2, 4, 3, 6, 8, 9, 9, 10, 11, 13]
lm = linear_model.LinearRegression()
lm.fit(X, Y) # fitting the model
Z = np.array([1, 5, 15, 56, 27]).reshape(-1, 1)
print("The input values are:", Z)
output = lm.predict(Z)
print("The predicted values are:", output)
Ausgabe:
The input values are: [[ 1]
[ 5]
[15]
[56]
[27]]
The predicted values are: [ 2.23636364 6.91515152 18.61212121 66.56969697 32.64848485]
Hier können Sie sehen, dass wir der Methode predict() unterschiedliche Werte von X bereitgestellt haben und sie den entsprechenden vorhergesagten Wert für jeden Eingabewert zurückgegeben hat.
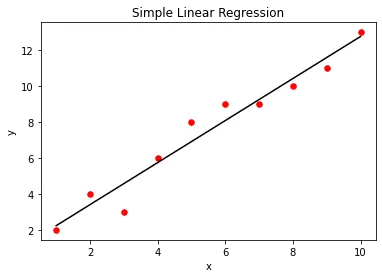
Wir können das einfache lineare Regressionsmodell mit der Bibliotheksfunktion matplotlib visualisieren. Dazu erstellen wir zunächst ein Streudiagramm der tatsächlichen X- und Y-Werte, die als Eingabe bereitgestellt werden. Nachdem wir das lineare Regressionsmodell erstellt haben, werden wir die Ausgabe des Regressionsmodells mit der Methode predict() gegen X darstellen. Dadurch erhalten wir eine gerade Linie, die das Regressionsmodell darstellt, wie unten gezeigt.
from sklearn import linear_model
import numpy as np
import matplotlib.pyplot as plt
X = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]).reshape(-1, 1)
Y = [2, 4, 3, 6, 8, 9, 9, 10, 11, 13]
lm = linear_model.LinearRegression()
lm.fit(X, Y)
plt.scatter(X, Y, color="r", marker="o", s=30)
y_pred = lm.predict(X)
plt.plot(X, y_pred, color="k")
plt.xlabel("x")
plt.ylabel("y")
plt.title("Simple Linear Regression")
plt.show()
Ausgabe:
Implementierung der multiplen Regression in Python
Bei der multiplen Regression haben wir mehr als eine unabhängige Variable. Angenommen, es gebe zwei unabhängige Variablen X1 und X2 und ihre abhängige Variable Y sei wie folgt gegeben.
X1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
X2 = [5, 7, 7, 8, 9, 9, 10, 11, 12, 13]
Y = [5, 7, 6, 9, 11, 12, 12, 13, 14, 16]
Hier bildet jeder i-te Wert in X1, X2 und Y ein Triplett, wobei das i-te Element des Arrays Y unter Verwendung des i-ten Elements des Arrays X1 und des i-ten Elements des Arrays X2 bestimmt wird.
Um die multiple Regression in Python zu implementieren, erstellen wir wie folgt ein Array X aus X1 und X2.
X1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
X2 = [5, 7, 7, 8, 9, 9, 10, 11, 12, 13]
X = [
(1, 5),
(2, 7),
(3, 7),
(4, 8),
(5, 9),
(6, 9),
(7, 10),
(8, 11),
(9, 12),
(10, 13),
]
Um X aus X1 und X2 zu erstellen, verwenden wir die Methode zip(). Die Methode zip() nimmt verschiedene iterierbare Objekte als Eingabe und gibt einen Iterator zurück, der die gepaarten Elemente enthält. Wie unten gezeigt, können wir den Iterator mit dem Konstruktor list() in eine Liste umwandeln.
X1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
X2 = [5, 7, 7, 8, 9, 9, 10, 11, 12, 13]
print("X1:", X1)
print("X2:", X2)
X = list(zip(X1, X2))
print("X:", X)
Ausgabe:
X1: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
X2: [5, 7, 7, 8, 9, 9, 10, 11, 12, 13]
X: [(1, 5), (2, 7), (3, 7), (4, 8), (5, 9), (6, 9), (7, 10), (8, 11), (9, 12), (10, 13)]
Nachdem wir X erhalten haben, müssen wir F(X)= A0+A1X1+A2X2 finden.
Dazu können wir die Merkmalsmatrix X und das abhängige Variablenarray Y an die fit()-Methode übergeben. Bei der Ausführung passt die Methode fit() die Konstanten A0, A1 und A2 so an, dass das Modell das multiple Regressionsmodell F(X) darstellt. Sie finden die Werte A1 und A2 mit dem Attribut coef_ und den Wert A0 mit dem Attribut intercept_ wie unten gezeigt.
from sklearn import linear_model
import numpy as np
X1 = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
X2 = np.array([5, 7, 7, 8, 9, 9, 10, 11, 12, 13])
Y = [5, 7, 6, 9, 11, 12, 12, 13, 14, 16]
X = list(zip(X1, X2))
lm = linear_model.LinearRegression()
lm.fit(X, Y) # fitting the model
print("The coefficient is:", lm.coef_)
print("The intercept is:", lm.intercept_)
Ausgabe:
The coefficient is: [0.72523364 0.55140187]
The intercept is: 1.4934579439252396
Hier sehen Sie, dass der Koeffizient ein Array ist. Das erste Element des Arrays repräsentiert A1, während das zweite Element des Arrays A2 repräsentiert. Der Schnittpunkt repräsentiert A0
Nach dem Trainieren des Modells können Sie den Wert für Y für jeden Wert von X1, X2 wie folgt vorhersagen.
from sklearn import linear_model
import numpy as np
X1 = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
X2 = np.array([5, 7, 7, 8, 9, 9, 10, 11, 12, 13])
Y = [5, 7, 6, 9, 11, 12, 12, 13, 14, 16]
X = list(zip(X1, X2))
lm = linear_model.LinearRegression()
lm.fit(X, Y) # fitting the model
Z = [(1, 3), (1, 5), (4, 9), (4, 8)]
print("The input values are:", Z)
output = lm.predict(Z)
print("The predicted values are:", output)
Ausgabe:
The input values are: [(1, 3), (1, 5), (4, 9), (4, 8)]
The predicted values are: [3.8728972 4.97570093 9.35700935 8.80560748]

Aditya Raj is a highly skilled technical professional with a background in IT and business, holding an Integrated B.Tech (IT) and MBA (IT) from the Indian Institute of Information Technology Allahabad. With a solid foundation in data analytics, programming languages (C, Java, Python), and software environments, Aditya has excelled in various roles. He has significant experience as a Technical Content Writer for Python on multiple platforms and has interned in data analytics at Apollo Clinics. His projects demonstrate a keen interest in cutting-edge technology and problem-solving, showcasing his proficiency in areas like data mining and software development. Aditya's achievements include securing a top position in a project demonstration competition and gaining certifications in Python, SQL, and digital marketing fundamentals.
GitHub