Python 中的線性迴歸
在本文中,我們將討論線性迴歸,並瞭解如何使用線性迴歸來預測結果。我們還將在 Python 中實現簡單的線性迴歸和多元迴歸。
什麼是迴歸
迴歸是識別自變數和因變數之間關係的過程。它用於預測房價、員工工資和其他預測應用。
如果我們要預測房價,自變數可能包括房屋的年齡、臥室數量、與中心城市位置(如機場、市場等)的距離。這裡,房屋的價格將取決於這些自變數。因此,房子的價格是一個因變數。
同樣,如果我們要預測員工的工資,自變數可能是他們的工作年限、教育水平、居住地的生活成本等。這裡,因變數是員工的工資。
通過迴歸,我們嘗試建立一個數學模型來描述自變數如何影響因變數。當提供自變數的值時,數學模型應該以最小的誤差預測因變數。
什麼是線性迴歸
線上性迴歸中,假設自變數和因變數是線性相關的。
假設給定 N 個自變數,如下所示。
$$
X=( X_1, X_2, X_3, X_4, X_5, X_6, X_7……, X_N)
$$
現在,我們需要找到如下等式的線性關係。
$$
F(X)= A_0+A_1X_1+A_2X_2+ A_3X_3+ A_4X_4+ A_5X_5+ A_6X_6+ A_7X_7+………..+A_NX_N
$$
這裡,
- 我們必須使用線性迴歸來識別常數
Ai,以便在給定自變數時以最小誤差預測因變數F(X)。 - 常數 Ai 稱為迴歸係數的預測權重或估計量。
- F(X) 稱為迴歸的預測響應或估計響應。對於給定的
X=( X1, X2, X3, X4, X5, X6, X7……, XN),F(X)應評估為儘可能接近實際因變數 Y 的值對於給定的自變數 X。 - 為了計算函式 F(X) 的計算結果為 Y,我們通常最小化給定 X 值的 F(X) 和 Y 之差的均方根。
Python 中簡單線性迴歸的實現
簡單迴歸中只有一個自變數和一個因變數。因此,預測的響應可以寫成如下。
$$
F(X)= A_0+ A_{1X}
$$
為了在 Python 中實現簡單的線性迴歸,我們需要一些 X 的實際值及其對應的 Y 值。使用這些值,我們可以通過數學方式或使用 Python 中提供的函式計算預測的權重 A0 和 A1。
假設我們以陣列的形式給出了十個 X 值,如下所示。
X = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
此外,相應的 Y 值如下給出。
Y = [2, 4, 3, 6, 8, 9, 9, 10, 11, 13]
為了找到迴歸方程 F(X),我們可以使用 scikit-learn 機器學習庫中的 linear_model 模組。你可以通過在機器的命令提示符下執行以下命令來安裝 scikit-learn 庫。
pip3 install scikit-learn
scikit-learn 庫的 linear_model 模組為我們提供了 LinearRegression() 方法,我們可以使用它來查詢預測的響應。LinearRegression() 方法在執行時返回一個線性模型。我們可以訓練這個線性模型來找到 F(X)。為此,我們使用 fit() 方法。
fit() 方法線上性模型上呼叫時,接受自變數陣列 X 作為其第一個引數,將因變數陣列 Y 作為其第二個輸入引數。執行後,線性模型的引數被調整為模型代表 F(X)。你可以分別使用 intercept_ 和 coef_ 屬性找到 A0 和 A1 的值,如下所示。
from sklearn import linear_model
import numpy as np
X = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]).reshape(-1, 1)
Y = [2, 4, 3, 6, 8, 9, 9, 10, 11, 13]
lm = linear_model.LinearRegression()
lm.fit(X, Y) # fitting the model
print("The coefficient is:", lm.coef_)
print("The intercept is:", lm.intercept_)
輸出:
The coefficient is: [1.16969697]
The intercept is: 1.0666666666666664
在這裡,可以看到係數值 A1 為 1.16969697,截距值 A0 為 1.0666666666666664。
實現線性迴歸模型後,你可以使用 predict() 方法預測任何 X 的 Y 值。在模型上呼叫時,predict() 方法將自變數 X 作為輸入引數並返回因變數 Y 的預測值,如下例所示。
from sklearn import linear_model
import numpy as np
X = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]).reshape(-1, 1)
Y = [2, 4, 3, 6, 8, 9, 9, 10, 11, 13]
lm = linear_model.LinearRegression()
lm.fit(X, Y) # fitting the model
Z = np.array([1, 5, 15, 56, 27]).reshape(-1, 1)
print("The input values are:", Z)
output = lm.predict(Z)
print("The predicted values are:", output)
輸出:
The input values are: [[ 1]
[ 5]
[15]
[56]
[27]]
The predicted values are: [ 2.23636364 6.91515152 18.61212121 66.56969697 32.64848485]
在這裡,你可以看到我們為 predict() 方法提供了不同的 X 值,並且它為每個輸入值返回了相應的預測值。
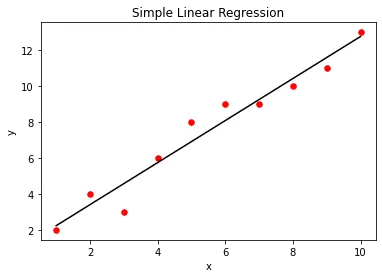
我們可以使用 matplotlib 庫函式視覺化簡單的線性迴歸模型。為此,我們首先建立作為輸入提供的實際 X 和 Y 值的散點圖。建立線性迴歸模型後,我們將使用 predict() 方法繪製迴歸模型的輸出與 X 的關係。這將為我們提供一條表示迴歸模型的直線,如下所示。
from sklearn import linear_model
import numpy as np
import matplotlib.pyplot as plt
X = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]).reshape(-1, 1)
Y = [2, 4, 3, 6, 8, 9, 9, 10, 11, 13]
lm = linear_model.LinearRegression()
lm.fit(X, Y)
plt.scatter(X, Y, color="r", marker="o", s=30)
y_pred = lm.predict(X)
plt.plot(X, y_pred, color="k")
plt.xlabel("x")
plt.ylabel("y")
plt.title("Simple Linear Regression")
plt.show()
輸出:
Python 中多重回歸的實現
在多元迴歸中,我們有不止一個自變數。例如,假設有兩個自變數 X1 和 X2,它們的因變數 Y 給出如下。
X1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
X2 = [5, 7, 7, 8, 9, 9, 10, 11, 12, 13]
Y = [5, 7, 6, 9, 11, 12, 12, 13, 14, 16]
這裡 X1、X2 和 Y 中的每個第 i 個值形成一個三元組,其中陣列 Y 的第 i 個元素由陣列 X1 的第 i 個元素和陣列 X2 的第 i 個元素確定。
為了在 Python 中實現多元迴歸,我們將從 X1 和 X2 建立一個陣列 X,如下所示。
X1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
X2 = [5, 7, 7, 8, 9, 9, 10, 11, 12, 13]
X = [
(1, 5),
(2, 7),
(3, 7),
(4, 8),
(5, 9),
(6, 9),
(7, 10),
(8, 11),
(9, 12),
(10, 13),
]
要從 X1 和 X2 建立 X,我們將使用 zip() 方法。zip() 方法將不同的可迭代物件作為輸入,並返回一個包含成對元素的迭代器。如下所示,我們可以使用 list() 建構函式將迭代器轉換為列表。
X1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
X2 = [5, 7, 7, 8, 9, 9, 10, 11, 12, 13]
print("X1:", X1)
print("X2:", X2)
X = list(zip(X1, X2))
print("X:", X)
輸出:
X1: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
X2: [5, 7, 7, 8, 9, 9, 10, 11, 12, 13]
X: [(1, 5), (2, 7), (3, 7), (4, 8), (5, 9), (6, 9), (7, 10), (8, 11), (9, 12), (10, 13)]
得到 X 後,我們需要找到 F(X)= A0+A1X1+A2X2。
為此,我們可以將特徵矩陣 X 和因變數陣列 Y 傳遞給 fit() 方法。執行時,fit() 方法會調整常數 A0、A1 和 A2,使模型代表多元迴歸模型 F(X)。你可以使用 coef_ 屬性找到值 A1 和 A2,使用 intercept_ 屬性找到值 A0,如下所示。
from sklearn import linear_model
import numpy as np
X1 = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
X2 = np.array([5, 7, 7, 8, 9, 9, 10, 11, 12, 13])
Y = [5, 7, 6, 9, 11, 12, 12, 13, 14, 16]
X = list(zip(X1, X2))
lm = linear_model.LinearRegression()
lm.fit(X, Y) # fitting the model
print("The coefficient is:", lm.coef_)
print("The intercept is:", lm.intercept_)
輸出:
The coefficient is: [0.72523364 0.55140187]
The intercept is: 1.4934579439252396
在這裡,你可以看到係數是一個陣列。陣列的第一個元素代表 A1,而陣列的第二個元素代表 A2。截距代表 A0
訓練模型後,你可以預測 X1、X2 的任何值的 Y 值,如下所示。
from sklearn import linear_model
import numpy as np
X1 = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
X2 = np.array([5, 7, 7, 8, 9, 9, 10, 11, 12, 13])
Y = [5, 7, 6, 9, 11, 12, 12, 13, 14, 16]
X = list(zip(X1, X2))
lm = linear_model.LinearRegression()
lm.fit(X, Y) # fitting the model
Z = [(1, 3), (1, 5), (4, 9), (4, 8)]
print("The input values are:", Z)
output = lm.predict(Z)
print("The predicted values are:", output)
輸出:
The input values are: [(1, 3), (1, 5), (4, 9), (4, 8)]
The predicted values are: [3.8728972 4.97570093 9.35700935 8.80560748]

Aditya Raj is a highly skilled technical professional with a background in IT and business, holding an Integrated B.Tech (IT) and MBA (IT) from the Indian Institute of Information Technology Allahabad. With a solid foundation in data analytics, programming languages (C, Java, Python), and software environments, Aditya has excelled in various roles. He has significant experience as a Technical Content Writer for Python on multiple platforms and has interned in data analytics at Apollo Clinics. His projects demonstrate a keen interest in cutting-edge technology and problem-solving, showcasing his proficiency in areas like data mining and software development. Aditya's achievements include securing a top position in a project demonstration competition and gaining certifications in Python, SQL, and digital marketing fundamentals.
GitHub