팬더 리버스 데이터 프레임
-
loc메서드를 사용하여 Pandas에서 오류 없이 데이터 프레임 반전 - Python에서 Pandas 데이터 프레임을 뒤집는 잘못된 방법
-
reversed()함수의 Data Fame 워크플로우
행과 열을 뒤집는 방법과 인덱스를 재설정하는 방법도 알아봅니다. 또한 일부 초보자가 Pandas에서 데이터 프레임을 반전하려고 할 때 실패하는 이유도 알아봅니다.
loc 메서드를 사용하여 Pandas에서 오류 없이 데이터 프레임 반전
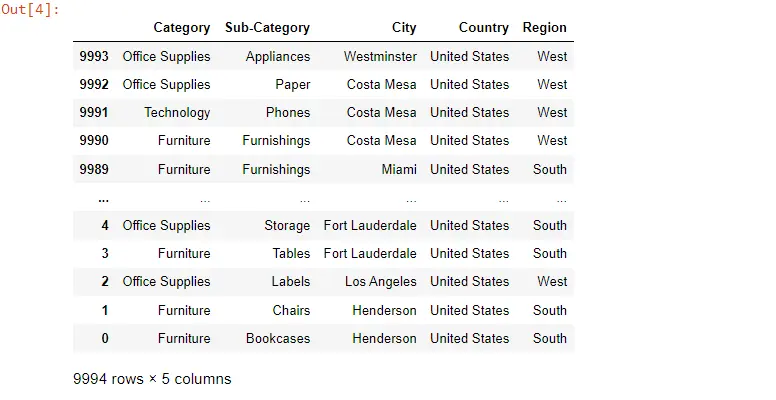
이제 코드로 이동하여 pandas 라이브러리와 데이터 세트, 동일한 폴더에 있는 Excel 파일에서 가져온 샘플 슈퍼마켓 데이터를 가져옵니다. 샘플 슈퍼마켓을 확인하면 여러 열이 있는 엄청난 양의 데이터를 볼 수 있습니다.
import pandas as pd
Data = pd.read_excel("demo_Data.xls")
Data.head()
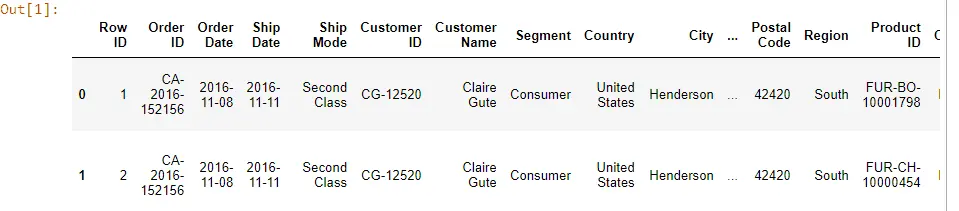
이제 이해하기 쉽고 이해하기 쉽게 몇 개의 열을 살펴보겠습니다. 따라서 먼저 데이터 조작을 위해 고려되는 몇 가지 열을 선택합니다.
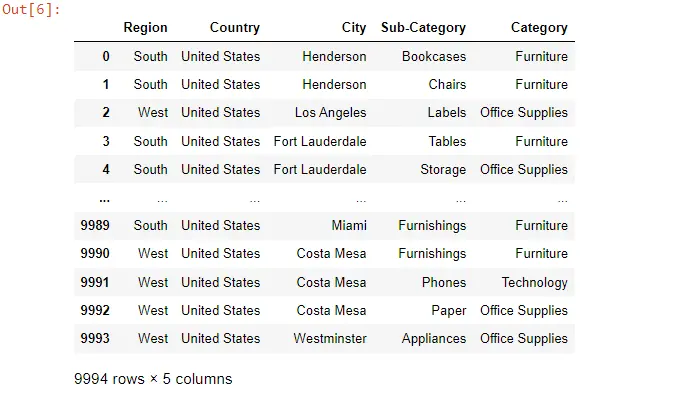
data = Data[["Category", "Sub-Category", "City", "Country", "Region"]]
data.head()
우리의 임무는 행과 열을 뒤집는 것입니다. 먼저 총 레코드 수와 총 열 수를 확인합니다.
len(data), len(data.columns)
출력:
(9994, 5)
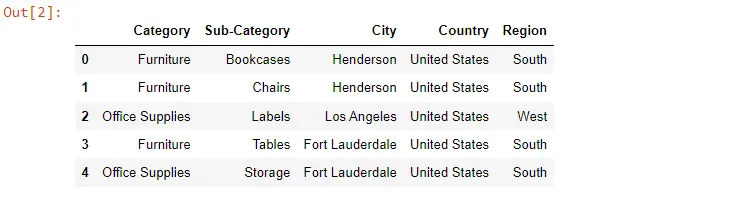
이제 역방향 데이터를 수행할 시간이므로 다음 코드를 사용하여 데이터 프레임을 역방향으로 만들 것입니다.
data.loc[::-1]
이제 loc 메서드를 사용하여 데이터가 반전된 것을 볼 수 있습니다.
우리는 데이터 프레임을 뒤집는 방법을 알고 있지만 데이터 프레임 인덱스가 999부터 시작하므로 인덱스를 재설정해야 합니다. 이를 위해 reset_index() 메서드를 사용하고 drop 인수는 True입니다.
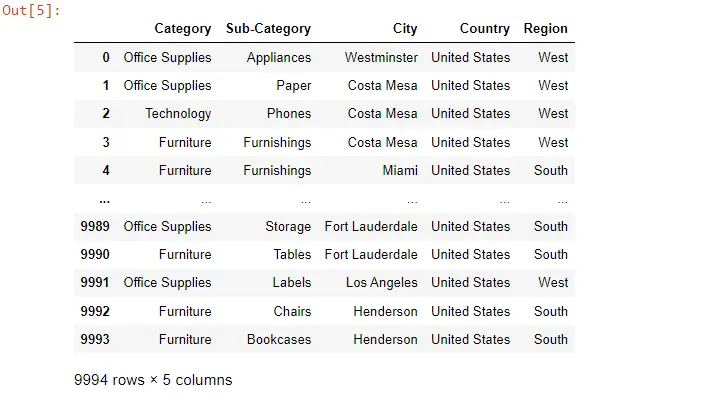
data.loc[::-1].reset_index(drop=True)
이제 실행해보면 인덱스가 리셋되어 9993이 0으로 변경된 것을 볼 수 있으며, 첫 번째 레코드는 이전 레코드이며 모든 레코드는 동일합니다.
열을 내림차순으로 변경하면 첫 번째 열은 지역, 국가 등이어야 합니다. 이를 위해 위와 동일한 코드를 약간만 변경하여 사용합니다.
data.loc[:, ::-1]
이것은 loc 메서드를 사용하여 열을 뒤집을 수 있는 방법과 쉼표 뒤(열을 뒤집는다는 의미)와 쉼표 앞(모든 행 선택을 의미함)을 의미합니다.
Python에서 Pandas 데이터 프레임을 뒤집는 잘못된 방법
일부 초보자는 데이터 프레임에 reversed() 함수를 사용하는 방법에 대한 지식이 부족하여 데이터 프레임을 잘못 반전하고 오류가 발생합니다.
다음 코드를 고려하십시오.
data = Data[["Category", "Sub-Category", "City", "Country", "Region"]]
for i in reversed(data):
print(data["Category"], data["Country"])
출력:
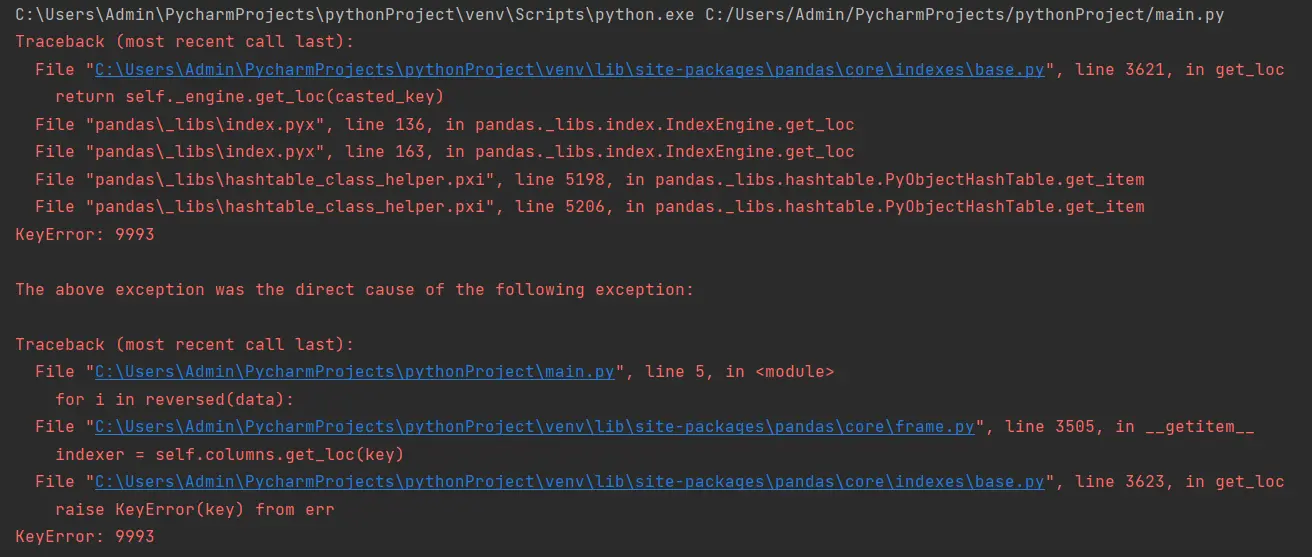
초보자가 위의 코드 조각을 사용하여 데이터 프레임을 뒤집는 이유는 무엇입니까? 음, reversed() 함수는 우리가 입력한 데이터 유형을 뒤집기 때문에 이러한 방식으로 데이터를 뒤집으려고 합니다.
다음 코드를 고려하십시오.
data = ["Category", "Sub-Category", "City", "Country", "Region"]
for i in reversed(data):
print(i)
데이터 유형이 목록이고 데이터 프레임이 다르게 작동하기 때문에 위의 코드가 완벽하게 반전되는 것을 볼 수 있습니다.
Region
Country
City
Sub-Category
Category
reversed() 함수의 Data Fame 워크플로우
장면 뒤에서 reversed() 함수에서 데이터 프레임을 제공할 때 일부 구현이 발생합니다.
reversed()는len()함수를 호출하고 그 안에 데이터 프레임을 넣어 길이를 얻습니다.range()함수를 호출하고 길이를 입력합니다.- 역순으로 반복을 시작합니다.
reversed() 기능을 사용하여 컨트롤은 먼저 데이터 프레임의 길이를 가져온 다음 range() 기능에 넣고 역순으로 반복을 시작합니다.
그런 다음 컨트롤은 첫 번째 요소를 가져오고 data[9993]와 같이 대괄호로 묶습니다. 여기서 오류가 발생합니다.
그리고 9993은 컬럼 이름이 아니라 인덱스이기 때문에 데이터 프레임에 9993이 존재하지 않습니다. 위 섹션에서 언급한 올바른 접근 방식을 사용할 수 있습니다.

Hello! I am Salman Bin Mehmood(Baum), a software developer and I help organizations, address complex problems. My expertise lies within back-end, data science and machine learning. I am a lifelong learner, currently working on metaverse, and enrolled in a course building an AI application with python. I love solving problems and developing bug-free software for people. I write content related to python and hot Technologies.
LinkedIn