Pandas umgekehrter Datenrahmen
-
Verwenden Sie die
loc-Methode, um den Datenrahmen ohne Fehler in Pandas umzukehren - Der falsche Weg, Pandas-Datenrahmen in Python umzukehren
-
Workflow von Data Fame in der Funktion
reversed()
Wir werden lernen, wie man die Zeilen und Spalten umkehrt und wie man auch den Index zurücksetzen kann. Wir werden auch erfahren, warum einige Anfänger scheitern, wenn sie versuchen, Datenrahmen in Pandas umzukehren.
Verwenden Sie die loc-Methode, um den Datenrahmen ohne Fehler in Pandas umzukehren
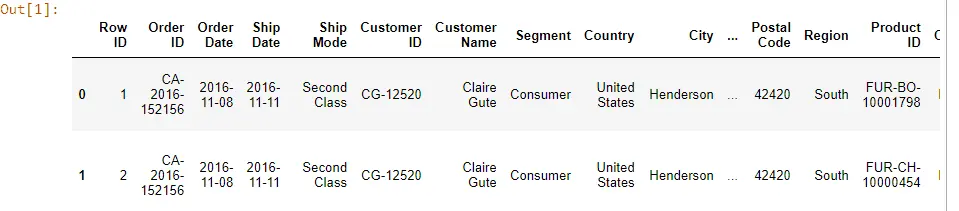
Jetzt beginnen wir mit dem Springen in den Code und importieren die Bibliothek und den Datensatz pandas, ein Beispiel für Superstore-Daten, die aus einer Excel-Datei stammen, die sich im selben Ordner befindet. Wenn wir den Beispiel-Superstore überprüfen, sehen wir eine riesige Datenmenge mit mehreren Spalten.
import pandas as pd
Data = pd.read_excel("demo_Data.xls")
Data.head()
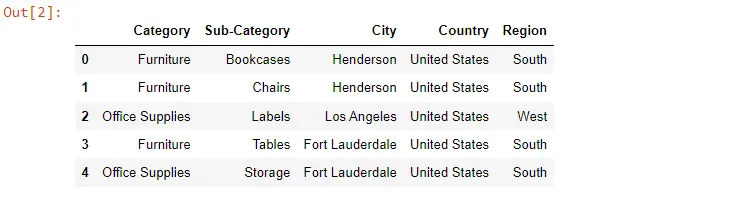
Jetzt nehmen wir ein paar Spalten, damit es für uns leicht verständlich ist und auch mehr Sinn ergibt. Also werden wir zunächst einige Spalten auswählen, die für die Datenmanipulation in Betracht gezogen werden.
data = Data[["Category", "Sub-Category", "City", "Country", "Region"]]
data.head()
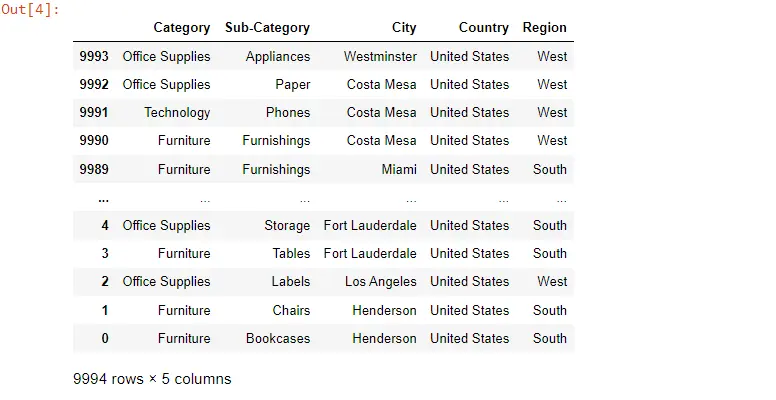
Unsere Aufgabe ist es, die Zeilen und Spalten umzukehren, und zuerst überprüfen wir unsere Gesamtzahl der Datensätze und die Gesamtzahl der Spalten.
len(data), len(data.columns)
Ausgang:
(9994, 5)
Es ist Zeit für uns, die umgekehrten Daten zu machen, also werden wir den folgenden Code verwenden, um den Datenrahmen umzukehren.
data.loc[::-1]
Wir können sehen, dass die Daten jetzt mit der Methode loc umgekehrt werden.
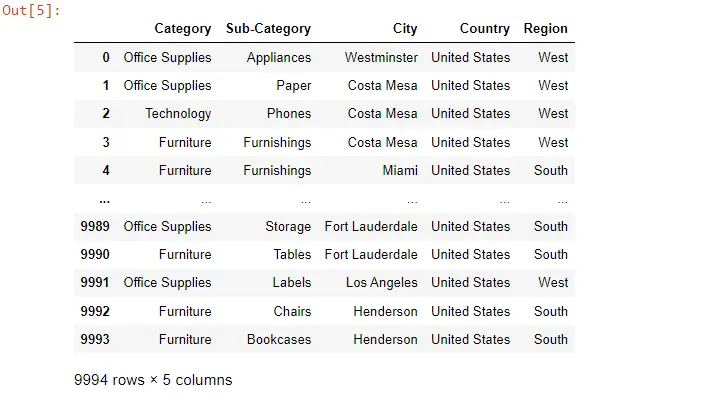
Wir wissen, wie man den Datenrahmen umkehrt, aber unser Datenrahmenindex beginnt bei 999, also müssen wir den Index zurücksetzen. Dazu verwenden wir die Methode reset_index() und das Argument drop ist True.
data.loc[::-1].reset_index(drop=True)
Wenn wir es jetzt ausführen, können wir sehen, dass der Index zurückgesetzt und 9993 mit 0 geändert wird, der erste Datensatz früher, und alle Datensätze sind gleich.
Wenn wir fortfahren und die Spalten in absteigender Reihenfolge ändern, sollte die erste Spalte Region sein, dann Land und so weiter. Dazu verwenden wir denselben Code wie oben, jedoch mit einer geringfügigen Änderung.
data.loc[:, ::-1]
So können wir die Spalte mit der Methode loc umkehren und nach dem Komma, was bedeutet, dass wir die Spalte umkehren, und vor dem Komma, was bedeutet, dass alle Zeilen ausgewählt werden.
Der falsche Weg, Pandas-Datenrahmen in Python umzukehren
Einige Anfänger kehren Datenrahmen falsch um und erhalten eine Fehlermeldung, weil sie weniger wissen, wie man die Funktion reversed() mit einem Datenrahmen verwendet.
Betrachten Sie den folgenden Code.
data = Data[["Category", "Sub-Category", "City", "Country", "Region"]]
for i in reversed(data):
print(data["Category"], data["Country"])
Ausgang:
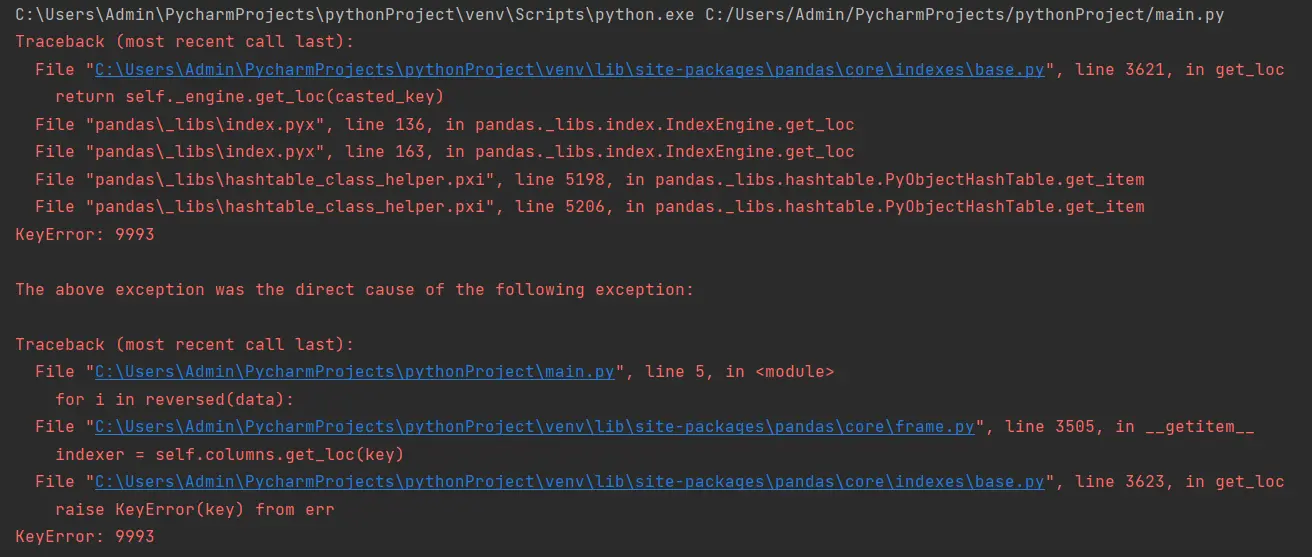
Warum verwenden Anfänger den obigen Codeausschnitt, um den Datenrahmen umzukehren? Nun, da die Funktion reversed() die von uns eingegebenen Datentypen umkehrt, versuchen sie, Daten auf diese Weise umzukehren.
Betrachten Sie den folgenden Code.
data = ["Category", "Sub-Category", "City", "Country", "Region"]
for i in reversed(data):
print(i)
Wir können sehen, dass sich der obige Code perfekt umkehrt, da der Datentyp eine Liste ist und der Datenrahmen anders funktioniert.
Region
Country
City
Sub-Category
Category
Workflow von Data Fame in der Funktion reversed()
Hinter den Kulissen finden einige Implementierungen statt, wenn wir einen Datenrahmen in der Funktion reversed() bereitstellen.
reversed()ruft die Funktionlen()auf und fügt einen Datenrahmen ein, um seine Länge zu erhalten.- Rufen Sie die Funktion
range()auf und geben Sie ihre Länge ein. - Iteration in umgekehrter Reihenfolge starten.
Mit der Funktion reversed() erhält die Steuerung zuerst die Länge des Datenrahmens, fügt sie dann in die Funktion range() ein und beginnt mit der Iteration in umgekehrter Reihenfolge.
Danach erhält das Steuerelement das erste Element und wird in eine eckige Klammer eingeschlossen, z. B. data[9993]; hier bekommen wir den Fehler.
Und 9993 existiert nicht im Datenrahmen, da 9993 ein Index und kein Spaltenname ist. Sie können den im obigen Abschnitt erwähnten korrekten Ansatz verwenden.

Hello! I am Salman Bin Mehmood(Baum), a software developer and I help organizations, address complex problems. My expertise lies within back-end, data science and machine learning. I am a lifelong learner, currently working on metaverse, and enrolled in a course building an AI application with python. I love solving problems and developing bug-free software for people. I write content related to python and hot Technologies.
LinkedIn