TensorFlow 勾配テープ
TensorFlow は、一貫したフレームワークであり、動的な機械学習と深層学習の分野で互換性のあるワークゾーンとして重要な役割を果たしてきました。
最も注目されているドメインの 1つはニューラル ネットワークであり、その動作原理は勾配降下アルゴリズムを使用して簡単に実証できます。 TensorFlow は、このエクスペリエンスを強化するために必要なほとんどすべてのライブラリを保証します。
基本的な概念によれば、ニューラル ネットワークは、人間の脳細胞がどのように動作し、決定し、認識し、機能するかです。 私たちの処理装置は、一度に与えられた情報しか記憶できません。
むしろ、学習率に従い、状況に対処することに基づいて背中合わせに修正します。 このプロセスには、コスト関数または損失関数または偏導関数または基本用語勾配と呼ばれる重要な用語があります。
概念を視覚化するために、共通の概念である線形回帰モデルを実証しようとしました。 機械学習の初心者でない場合は、既に機械学習に精通していることを前提としています。
このモデルが行うことは、回帰直線を利用して独立変数と従属変数の間の関係を抽出することです。
回帰直線を確立する際には、この特定のケースの 勾配 である 二乗誤差の合計 (SSE) を知る必要があります。 モデルをトレーニングするときは、SSE が最小であることが期待されます。
絶え間ないプロセスは、これをトレーニングに利用するだけです。 ここでは、指定した式から出力を計算し、ドライバの値を gradient x learning rate で再初期化します。
学習率 は安定性を保証するので、私たちの 損失関数 は突然の結果を示しません。
ベース値を開始した後、勾配に応じてベース値を更新します。 この後方パスは、モデルが適切にトレーニングされたかどうかを確認するために必要です。
そして、勾配テープは、更新された inputs と outputs と共に cost function を連続して保存するコンポーネントです。 したがって、値の詳細を使用して手順全体の全体像を把握できます。
例でメソッドを視覚化しましょう。
TensorFlow でのグラデーション テープの使用
このセクションでは、理論的な概要については説明しません。 むしろ、実用的なコードをフォローアップし、勾配テープにどのように依存しているかを実証しようとします.
それでは、コードベースにジャンプしましょう。 インスタンスには Google Colab を使用しています。
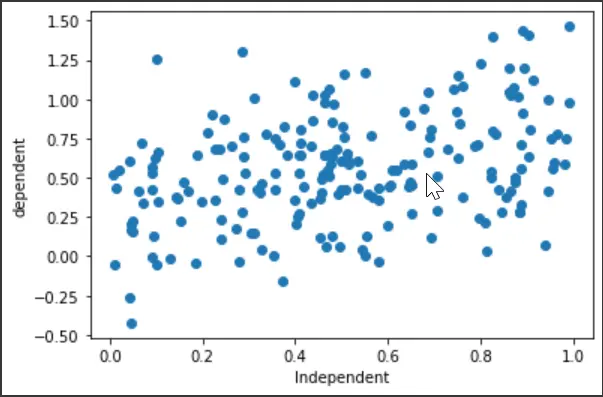
最初に、ライブラリのインポートを設定し、ドライブのランダム データセットを生成します。 また、散布図をプロットして、変数の動作を確認します。
# Necessary Imports
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
import os
# Generating random data
x = np.random.uniform(0.0, 1.0, (200))
y = 0.3 + 0.5 * x + np.random.normal(0.0, 0.3, len(x))
# x
# y
plt.scatter(x, y)
plt.xlabel("Independent")
plt.ylabel("dependent")
plt.show()
出力:
次のコード フェンスには、回帰モデルと損失関数の宣言が含まれます。 注目すべき重要な部分は、回帰モデルが従属変数 y の予測値を出力することです。式は次のようになります。
ここで、x はモデルの入力とも呼ばれる独立変数です。 主に、与えられた y と予測された y^ の間に最小誤差があるかどうかを確認しようとします。
損失関数には、二乗誤差 (SSE) の合計が含まれます。
# The following equation for the model is ----> y" = a + b * x
# Linear Regression
class regression:
def __init__(self):
self.a = tf.Variable(initial_value=0, dtype=tf.float32)
self.b = tf.Variable(initial_value=0, dtype=tf.float32)
def __call__(self, x):
x = tf.convert_to_tensor(x, dtype=tf.float32)
y_est = tf.add(self.a, tf.multiply(self.b, x))
return y_est
model = regression()
# The loss function/ Cost function/ Optimization function (sum of square error)
def loss_func(y_true, y_pred):
# both y_true and y_pred are tensors
sse = tf.reduce_sum(tf.square(tf.subtract(y_true, y_pred)))
return sse
次に、勾配テープを含むトレーニング セクションを定義します。 変数 a と b を更新する方程式は次のとおりです。
# Gradient Descent ----> a = ai - sse * lr (learning rate)
# b = bi - sse * lr
def train(model, inputs, outputs, lr):
# convert outputs to tensor
y_true = tf.convert_to_tensor(outputs, dtype=tf.float32)
# Gradient Tape
with tf.GradientTape() as g:
y_pred = model(inputs)
current_loss = loss_func(y_true, y_pred)
# slopes/ partal_differentiation/ gradients
da, db = g.gradient(current_loss, [model.a, model.b])
# update values
model.a.assign_sub(da * lr)
model.b.assign_sub(db * lr)
次のセグメントは、回帰直線を設定することです。 より良い学習のためにいくつかのエポックを設定します。
損失関数が最小になる飽和点と必要なエポック値を調べました。 エポックとコストの値をプロットして、トレーニング セクション全体から出力がどのように発生したかを確認しましょう。
# Fitting
def plotting(x, y):
plt.scatter(x, y) # scatter
plt.plot(x, model(x), "r--")
model = regression()
a_val = []
b_val = []
cost_val = []
# epochs
epochs = 70
# learning rate
lr = 0.001
for e in range(epochs):
a_val.append(model.a)
b_val.append(model.b)
# prediction values and errors
y_pred = model(x)
cost_value = loss_func(y, y_pred)
cost_val.append(cost_value)
# Train
train(model, x, y, lr)
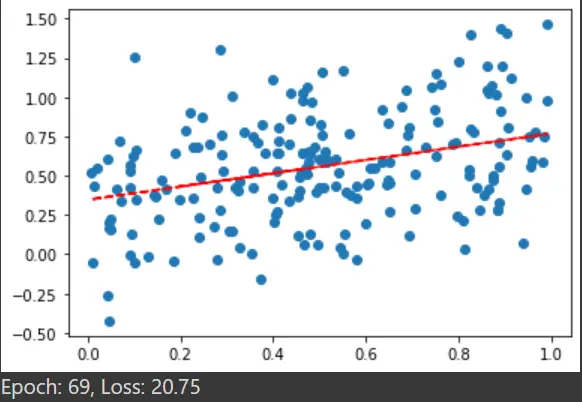
plotting(x, y)
plt.show()
print("Epoch: %d, Loss: %0.2f" % (e, cost_value))
最後のエポックからの出力散布図:
plt.plot(cost_val)
plt.xlabel("epochs")
plt.ylabel("cost values")
出力:
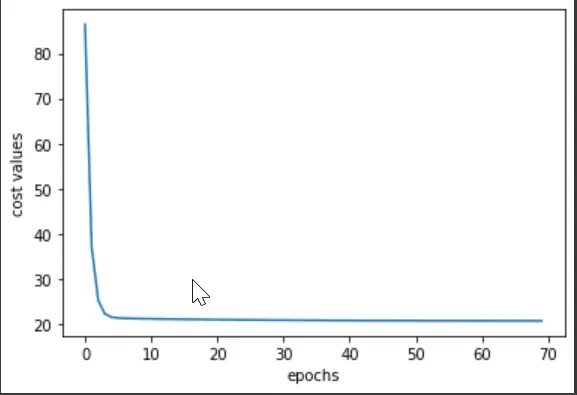
つまり、エポック範囲≪0~10≫でコスト値が大幅に減少したと言えます。 すべてのエポックを実行すると、飽和点が 64-65 エポックの近くにあることがわかります。
技術的には、グラデーション テープは対応するすべての値を収集するのに役立ち、視覚化がより直感的になりました。 this リンクでコード全体をプレビューすることもできます。
