TensorFlow-Farbband
TensorFlow hat eine entscheidende Rolle dabei gespielt, ein konsistentes Framework und eine kompatible Arbeitszone für den Bereich des dynamischen maschinellen Lernens und des Deep Learning zu sein.
Eine der am meisten gehypten Domänen ist das neuronale Netzwerk, und sein Funktionsprinzip lässt sich leicht mit Hilfe des Gradientenabstiegsalgorithmus demonstrieren. Und TensorFlow stellt fast alle Bibliotheken sicher, die erforderlich sind, um diese Erfahrung zu verbessern.
Gemäß dem Grundkonzept ist das neuronale Netzwerk, wie die menschliche Gehirnzelle arbeitet, entscheidet, erkennt und funktioniert. Unsere Verarbeitungseinheit kann nur die jeweils zugeführten Informationen speichern.
Vielmehr folgt es einer Lernrate und überarbeitet sich nacheinander, basierend auf dem Umgang mit Situationen. In diesem Prozess gibt es einen wichtigen Begriff namens Kostenfunktion oder Verlustfunktion oder partielle Ableitung oder den Grundbegriff gradient.
Um das Konzept zu visualisieren, haben wir versucht, ein gemeinsames Konzept zu demonstrieren, das “Lineare Regression”-Modell. Wenn Sie kein Neuling im maschinellen Lernen sind, gehen wir davon aus, dass Sie bereits damit vertraut sind.
Was dieses Modell tut, ist eine Beziehung zwischen den unabhängigen und abhängigen Variablen mit Hilfe einer Regressionslinie zu extrahieren.
Bei der Erstellung der Regressionsgerade muss die Summe der quadratischen Fehler (SSE) bekannt sein, die für diesen speziellen Fall der gradient ist. Wir erwarten, dass die SSE das Minimum ist, wenn wir unser Modell trainieren.
Der ständige Prozess dient nur diesem Training. Hier berechnen wir die Ausgabe aus unserer angegebenen Gleichung und initialisieren die Treiberwerte mit dem Gradient x Lernrate neu.
Die Lernrate sorgt für Stabilität, damit unsere Verlustfunktion keine abrupten Folgen zeigt.
Wir werden die Basiswerte in Abhängigkeit von den Gradienten aktualisieren, nachdem wir einen Basiswert initiiert haben. Dieser Rückwärtsgang ist notwendig, um zu überprüfen, ob das Modell richtig trainiert wurde.
Und das Gradientenband ist genau die Komponente, die nacheinander die Kostenfunktion zusammen mit den aktualisierten inputs und outputs speichert. So erhalten wir ein vollständiges Bild des gesamten Vorgangs mit den Details der Werte.
Lassen Sie uns die Methode anhand eines Beispiels visualisieren.
Verwendung von Verlaufsband in TensorFlow
In diesem Abschnitt geben wir keinen theoretischen Überblick. Vielmehr werden wir den praktischen Codes nachgehen und versuchen zu demonstrieren, wie wir uns auf das Verlaufsband verlassen.
Kommen wir also zu den Codebasen. Wir verwenden Google Colab für unsere Instanz.
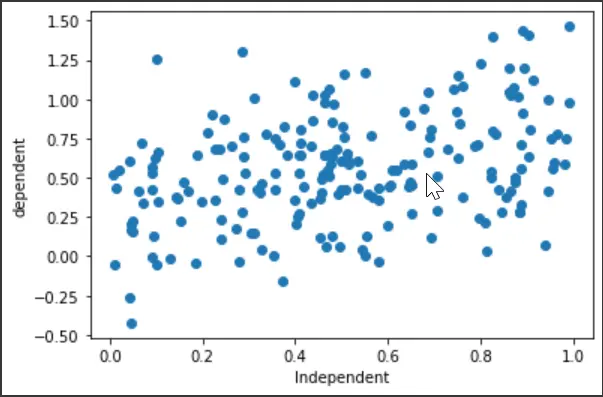
Zunächst werden wir die Bibliotheksimporte festlegen und einen zufälligen Datensatz für das Laufwerk generieren. Wir werden auch ein Streudiagramm zeichnen, um zu sehen, wie sich die Variablen verhalten.
# Necessary Imports
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
import os
# Generating random data
x = np.random.uniform(0.0, 1.0, (200))
y = 0.3 + 0.5 * x + np.random.normal(0.0, 0.3, len(x))
# x
# y
plt.scatter(x, y)
plt.xlabel("Independent")
plt.ylabel("dependent")
plt.show()
Ausgang:
Die nächsten Code-Fences beinhalten das Regressionsmodell und die Deklaration der Verlustfunktionen. Der wichtige Teil, auf den Sie sich konzentrieren sollten, ist, dass das Regressionsmodell den vorhergesagten Wert für die abhängige Variable y ausgibt, und die Gleichung lautet wie folgt:
Hier ist x die unabhängige Variable, auch bekannt als die Eingabe des Modells. Hauptsächlich werden wir versuchen zu sehen, ob wir den minimalen Fehler zwischen dem gegebenen y und dem vorhergesagten y^ haben.
Die Verlustfunktion enthält die Summe der quadratischen Fehler (SSE):
# The following equation for the model is ----> y" = a + b * x
# Linear Regression
class regression:
def __init__(self):
self.a = tf.Variable(initial_value=0, dtype=tf.float32)
self.b = tf.Variable(initial_value=0, dtype=tf.float32)
def __call__(self, x):
x = tf.convert_to_tensor(x, dtype=tf.float32)
y_est = tf.add(self.a, tf.multiply(self.b, x))
return y_est
model = regression()
# The loss function/ Cost function/ Optimization function (sum of square error)
def loss_func(y_true, y_pred):
# both y_true and y_pred are tensors
sse = tf.reduce_sum(tf.square(tf.subtract(y_true, y_pred)))
return sse
Als nächstes definieren wir den Trainingsabschnitt, einschließlich des Verlaufsbands. Die Gleichung zur Aktualisierung der Variablen a und b lautet:
# Gradient Descent ----> a = ai - sse * lr (learning rate)
# b = bi - sse * lr
def train(model, inputs, outputs, lr):
# convert outputs to tensor
y_true = tf.convert_to_tensor(outputs, dtype=tf.float32)
# Gradient Tape
with tf.GradientTape() as g:
y_pred = model(inputs)
current_loss = loss_func(y_true, y_pred)
# slopes/ partal_differentiation/ gradients
da, db = g.gradient(current_loss, [model.a, model.b])
# update values
model.a.assign_sub(da * lr)
model.b.assign_sub(db * lr)
Das nächste Segment dient zum Festlegen der Regressionslinie. Wir werden einige Epochen für besseres Lernen festlegen.
Wir haben den Sättigungspunkt und den notwendigen Epochenwert untersucht, für den die Verlustfunktion das Minimum ist. Lassen Sie uns die Epochen- und Kostenwerte grafisch darstellen, um zu sehen, wie die Ausgabe des gesamten Trainingsabschnitts erfolgt ist.
# Fitting
def plotting(x, y):
plt.scatter(x, y) # scatter
plt.plot(x, model(x), "r--")
model = regression()
a_val = []
b_val = []
cost_val = []
# epochs
epochs = 70
# learning rate
lr = 0.001
for e in range(epochs):
a_val.append(model.a)
b_val.append(model.b)
# prediction values and errors
y_pred = model(x)
cost_value = loss_func(y, y_pred)
cost_val.append(cost_value)
# Train
train(model, x, y, lr)
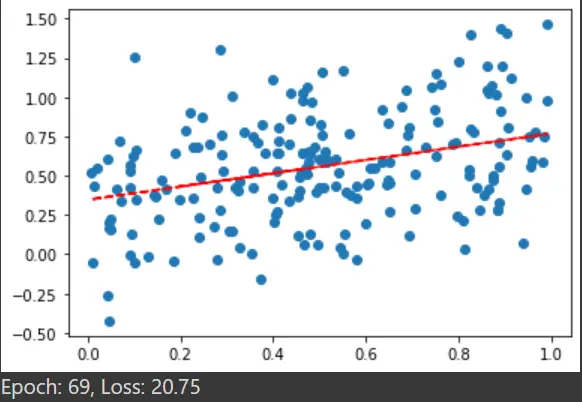
plotting(x, y)
plt.show()
print("Epoch: %d, Loss: %0.2f" % (e, cost_value))
Das Ausgabe-Streudiagramm der letzten Epoche:
plt.plot(cost_val)
plt.xlabel("epochs")
plt.ylabel("cost values")
Ausgang:
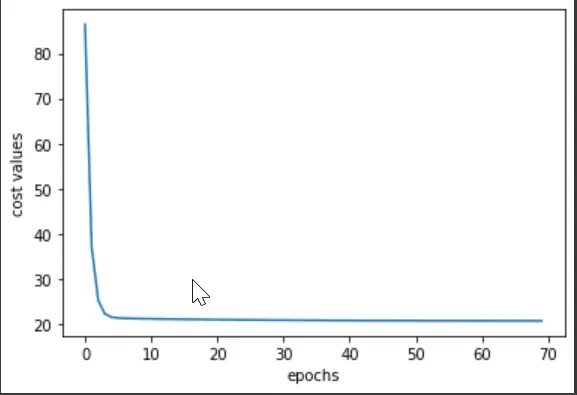
Man kann also sagen, dass die Kostenwerte im Epochenbereich von 0-10 drastisch gesunken sind. Und wenn Sie alle Epochen durchlaufen, werden Sie bei den Werten feststellen, dass der Sättigungspunkt in der Nähe der Epoche 64-65 liegt.
Technisch gesehen hat das Verlaufsband geholfen, alle entsprechenden Werte zu sammeln, und somit ist die Visualisierung intuitiver. Sie können den gesamten Code auch unter diesem Link in der Vorschau anzeigen.
