Seaborn で線形回帰を作成する
この記事の目的は、線形回帰について詳しく学び、Seaborn の regplot() メソッドを使用して線形回帰を作成する方法を確認することです。
Seaborn で regplot() メソッドを使用して線形回帰を作成する
regplot() 関数の全体的な目的は、データの線形回帰モデルを構築して視覚化することです。 regplot() は回帰プロットを表します。
コードに直接飛び込んで、Seaborn を使用して回帰プロットを作成する方法を見てみましょう。 ここで、Seaborn ライブラリと pyplot モジュールをインポートし、seaborn ライブラリからいくつかのデータもインポートします。
これらのデータはすべてダイヤモンドに関するものです。 したがって、このデータ フレームの各行は、1つの特定のダイヤモンドとそのさまざまな特性に関するものです。
import matplotlib.pyplot as plot
import seaborn as sb
DATA = sb.load_dataset("diamonds").dropna()
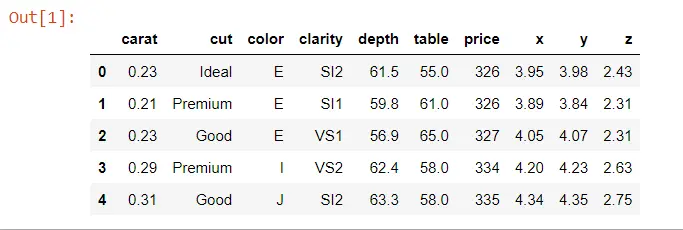
DATA.head()
出力:
ここで、各ダイヤモンドをドットとして表すため、このデータ セットから 190 のランダム サンプルを収集します。
DATA = DATA.sample(n=190, random_state=38)
これで、回帰プロットを開始する準備が整いました。 seaborn 回帰プロットを作成するには、regplot() メソッドによる参照を使用する必要があります。
ここでは、このメソッドで carat と price の 2つのシリーズを渡します。
sb.regplot(DATA.carat, DATA.price)
上記の例の完全なソース コードを次に示します。
import matplotlib.pyplot as plot
import seaborn as sb
DATA = sb.load_dataset("diamonds").dropna()
DATA.head()
DATA = DATA.sample(n=190, random_state=38)
sb.set_style("whitegrid")
sb.regplot(DATA.carat, DATA.price)
plot.show()
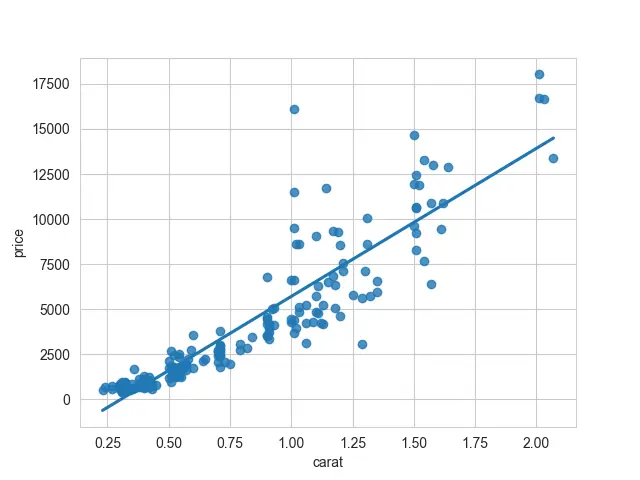
これで、seaborn が私たちのために何をしてくれたのかがわかります。 最初のシリーズは x 軸に沿ってプロットされ、2 番目のシリーズは y 軸に沿ってプロットされます。
これらのデータに適合する線形モデルがあります。 この線はすべての散布点を通過します。
出力:
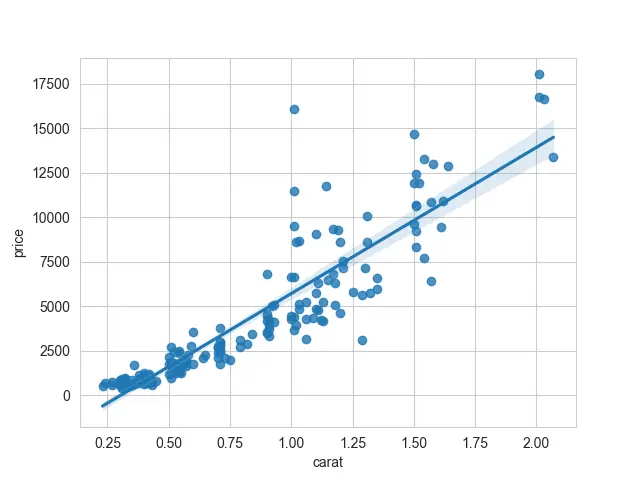
これで、線形モデルがどのようになるかがわかります。
その構文のもう 1つの点は、Seaborn regplot() を作成する別の方法は、data 引数で完全なデータ フレームを参照することです。
sb.regplot(x="carat", y="price", data=DATA)
x および y 引数の列名として参照を与えます。 それは同じプロットを生成します。
出力:
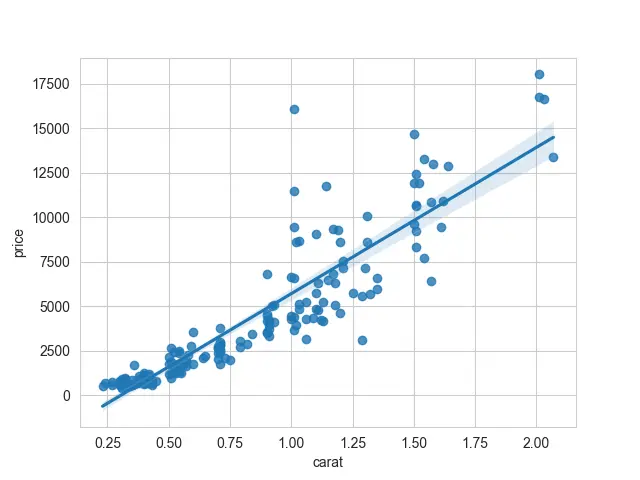
お気づきのように、このプロットには、散布部分と線形回帰直線の 2つのコンポーネントがあります。 これらのデータに回帰モデルを当てはめたくない場合は、fit_reg=False を渡すことができます。
import matplotlib.pyplot as plot
import seaborn as sb
DATA = sb.load_dataset("diamonds").dropna()
DATA.head()
DATA = DATA.sample(n=190, random_state=38)
sb.set_style("whitegrid")
sb.regplot(x="carat", y="price", data=DATA, fit_reg=False)
plot.show()
出力:
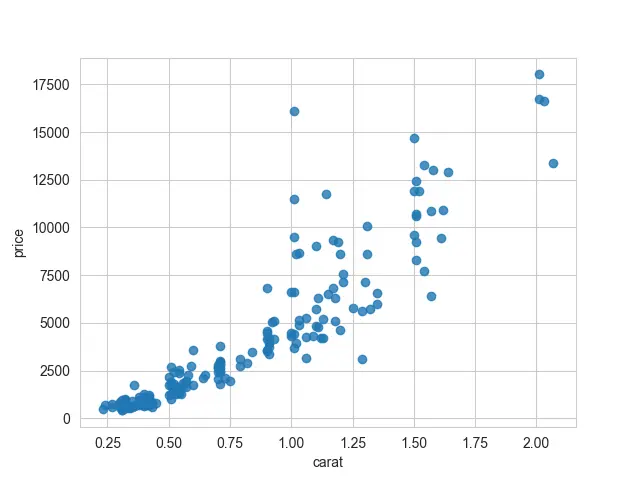
回帰直線のみでプロットしたい場合、もう 1つのオプションは、線形回帰からの直線のみをプロットすることです。 scatter 引数を使用して散布ポイントをオフにする必要があります。これは False に等しくなければなりません。
import matplotlib.pyplot as plot
import seaborn as sb
DATA = sb.load_dataset("diamonds").dropna()
DATA.head()
DATA = DATA.sample(n=190, random_state=38)
sb.set_style("whitegrid")
sb.regplot(x="carat", y="price", data=DATA, scatter=False)
plot.show()
出力:
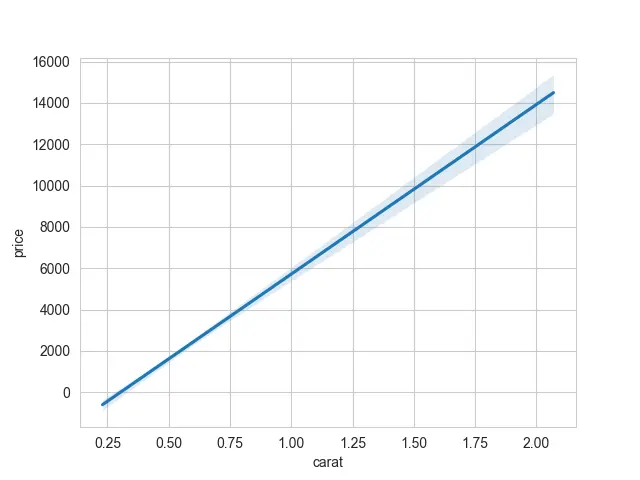
通常の回帰プロットをプロットすると、線の周りに影付きの領域がある縞模様の領域が表示されます。 これらは信頼区間と呼ばれます。
これをオフにしたい場合は、ci 引数を使用して、None に設定します。
import matplotlib.pyplot as plot
import seaborn as sb
DATA = sb.load_dataset("diamonds").dropna()
DATA.head()
DATA = DATA.sample(n=190, random_state=38)
sb.set_style("whitegrid")
sb.regplot(x="carat", y="price", data=DATA, ci=None)
plot.show()
出力:
これらの信頼区間が完全にオフになり、影付きのバンドではなく線だけが表示されます。
また、これらの軸の 1つに使用しようとしている discrete 変数がある場合に何が起こるかを示したいと思います。 そのため、一部の情報を数値に変換します。
CUT_MAP = {"Fair": 1, "Good": 2, "Very Good": 3, "Premium": 4, "Ideal": 5}
各ダイヤモンドの カット があり、それを最悪の種類のカットの 1つにマッピングし、昇順でカテゴリを設定しています。
DATA["CUT_VALUE"] = DATA.cut.map(CUT_MAP).cat.as_ordered()
CUT_VALUE 列を作成しました。これを印刷すると、1 から 5 の範囲の値があることがわかります。
import matplotlib.pyplot as plot
import seaborn as sb
DATA = sb.load_dataset("diamonds").dropna()
DATA.head()
DATA = DATA.sample(n=190, random_state=38)
sb.set_style("whitegrid")
CUT_MAP = {"Fair": 1, "Good": 2, "Very Good": 3, "Premium": 4, "Ideal": 5}
DATA["CUT_VALUE"] = DATA.cut.map(CUT_MAP).cat.as_ordered()
sb.regplot(x="CUT_VALUE", y="price", data=DATA)
plot.show()
出力:
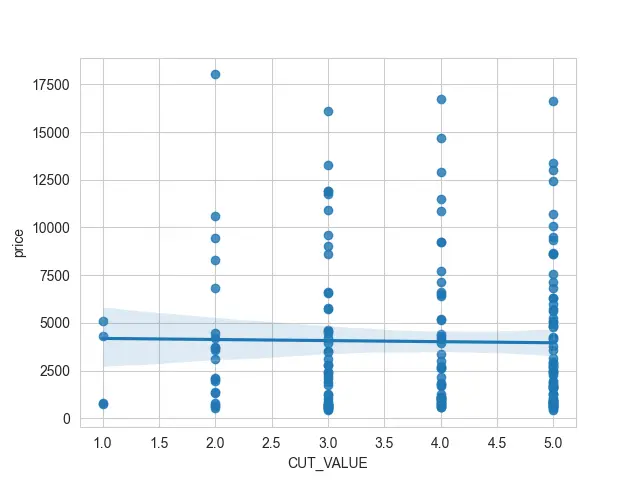
この CUT_VALUE 列を x 値として使用しようとすると、多くの散布点が重なり合っていることがわかります。 その線形回帰の下でそれらを確認するのは非常に難しい場合があります.
したがって、x_jitter プロパティが制御するジッターを少し追加できます。 それは私の散布点のそれぞれを取り、それらを左または右に移動します.
import numpy as np
import matplotlib.pyplot as plot
import seaborn as sb
DATA = sb.load_dataset("diamonds").dropna()
DATA.head()
DATA = DATA.sample(n=190, random_state=38)
sb.set_style("whitegrid")
CUT_MAP = {"Fair": 1, "Good": 2, "Very Good": 3, "Premium": 4, "Ideal": 5}
DATA["CUT_VALUE"] = DATA.cut.map(CUT_MAP).cat.as_ordered().astype(np.int8)
sb.regplot(x="CUT_VALUE", y="price", data=DATA, x_jitter=0.1)
plot.show()
出力:
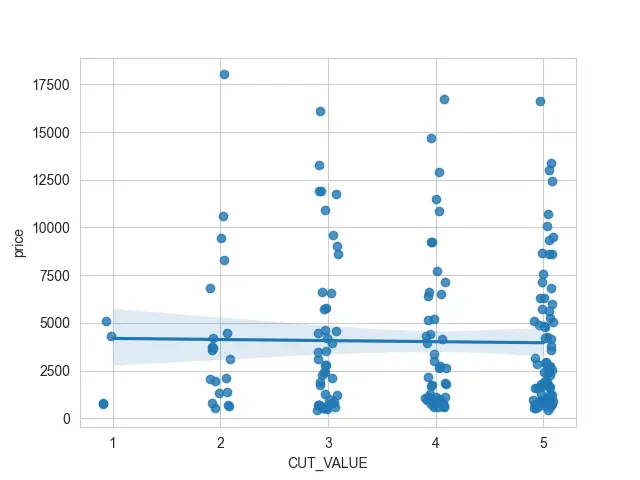
このようにして、散乱ポイントの塊がどこに集まっているかを確認できます。
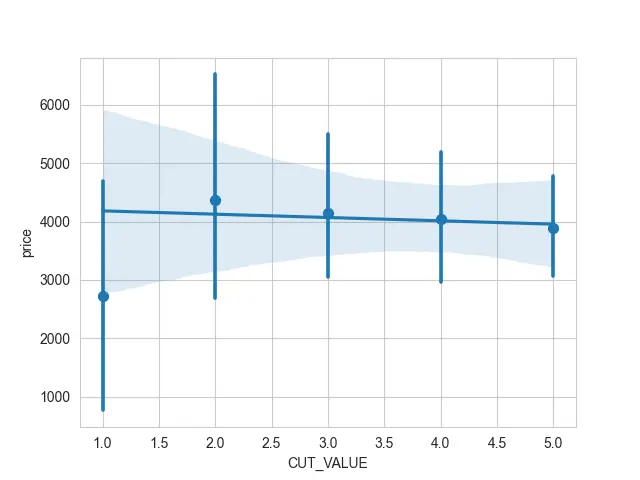
他にできることは、離散変数がある場合です。 個々の散布点をプロットする代わりに、x_estimator 引数を使用してこれらの点の推定器を使用できます。
import numpy as np
import matplotlib.pyplot as plot
import seaborn as sb
DATA = sb.load_dataset("diamonds").dropna()
DATA.head()
DATA = DATA.sample(n=190, random_state=38)
sb.set_style("whitegrid")
CUT_MAP = {"Fair": 1, "Good": 2, "Very Good": 3, "Premium": 4, "Ideal": 5}
DATA["CUT_VALUE"] = DATA.cut.map(CUT_MAP).cat.as_ordered().astype(np.int8)
sb.regplot(x="CUT_VALUE", y="price", data=DATA, x_estimator=np.mean)
plot.show()
これらの離散点をグループ化し、それらの値の平均と信頼区間を計算しました。 これで、多くの点が積み重なっていても読みやすくなりました。
出力:

Hello! I am Salman Bin Mehmood(Baum), a software developer and I help organizations, address complex problems. My expertise lies within back-end, data science and machine learning. I am a lifelong learner, currently working on metaverse, and enrolled in a course building an AI application with python. I love solving problems and developing bug-free software for people. I write content related to python and hot Technologies.
LinkedIn