Crear regresión lineal en Seaborn
Este artículo tiene como objetivo aprender sobre la regresión lineal en detalle y ver cómo podemos crear una regresión lineal con la ayuda del método regplot() en Seaborn.
Crear regresión lineal utilizando el método regplot() en Seaborn
Todo el propósito de la función regplot() es construir y visualizar un modelo de regresión lineal para sus datos. El regplot() significa gráfico de regresión.
Sumerjámonos directamente en el código para ver cómo construir un diagrama de regresión usando Seaborn. Ahora, importaremos la biblioteca Seaborn y el módulo pyplot, y también importaremos algunos datos de la biblioteca Seaborn.
Estos datos son todos acerca de los diamantes. Entonces, cada fila en este marco de datos se trata de un diamante en particular y sus diferentes propiedades.
import matplotlib.pyplot as plot
import seaborn as sb
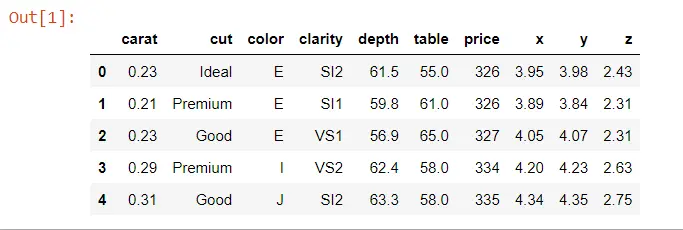
DATA = sb.load_dataset("diamonds").dropna()
DATA.head()
Producción:
Ahora, recolectaremos 190 muestras aleatorias de este conjunto de datos porque representaremos cada diamante como un punto.
DATA = DATA.sample(n=190, random_state=38)
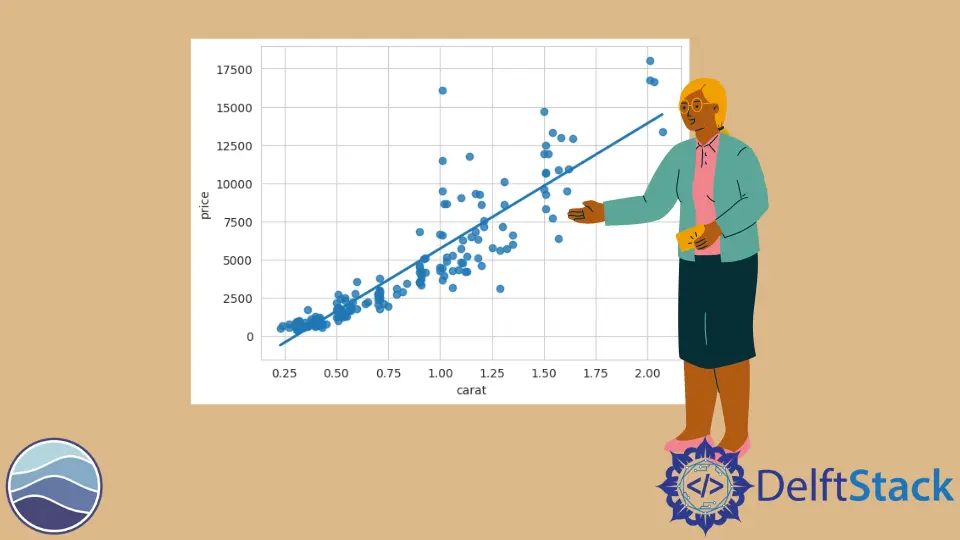
Ahora, estamos listos para comenzar con el gráfico de regresión. Para construir un gráfico de regresión marino, necesitamos usar la referencia mediante el método regplot().
Aquí, pasamos dos series en este método, quilate y precio.
sb.regplot(DATA.carat, DATA.price)
Aquí está el código fuente completo del ejemplo proporcionado arriba.
import matplotlib.pyplot as plot
import seaborn as sb
DATA = sb.load_dataset("diamonds").dropna()
DATA.head()
DATA = DATA.sample(n=190, random_state=38)
sb.set_style("whitegrid")
sb.regplot(DATA.carat, DATA.price)
plot.show()
Ahora, podemos ver lo que Seaborn ha hecho por nosotros. La primera serie se traza a lo largo del eje x y la segunda serie a lo largo del eje y.
Tenemos un modelo lineal que se ajusta a estos datos. Esta línea pasa por todos nuestros puntos de dispersión.
Producción:
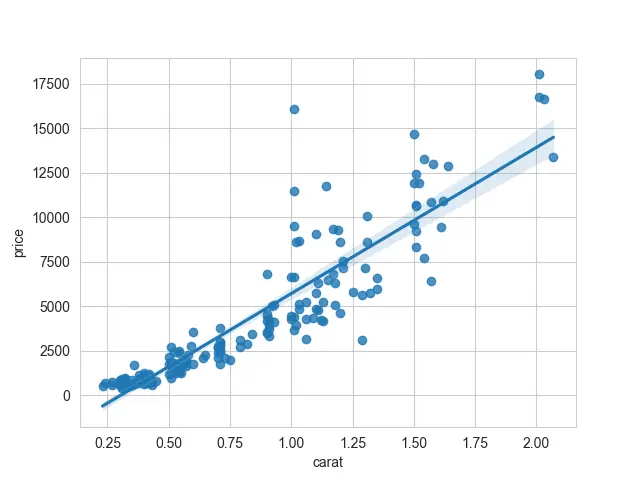
Así que ahora sabemos cómo sería un modelo lineal.
Otra cosa acerca de su sintaxis es que otra forma de crear un regplot() de Seaborn es haciendo referencia al marco de datos completo con el argumento datos.
sb.regplot(x="carat", y="price", data=DATA)
Damos referencias como nombres de columna para los argumentos x e y. Eso producirá la misma trama.
Producción:
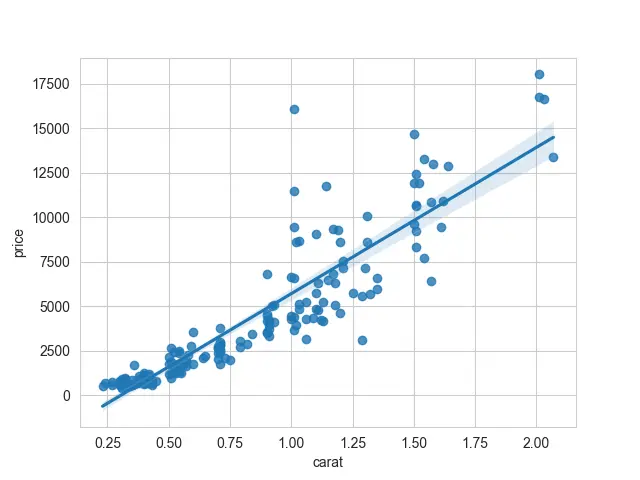
Como podemos notar, hay dos componentes en esta gráfica: la porción de dispersión y la línea de regresión lineal. Podemos pasar fit_reg=False si no queremos ajustar un modelo de regresión a estos datos.
import matplotlib.pyplot as plot
import seaborn as sb
DATA = sb.load_dataset("diamonds").dropna()
DATA.head()
DATA = DATA.sample(n=190, random_state=38)
sb.set_style("whitegrid")
sb.regplot(x="carat", y="price", data=DATA, fit_reg=False)
plot.show()
Producción:
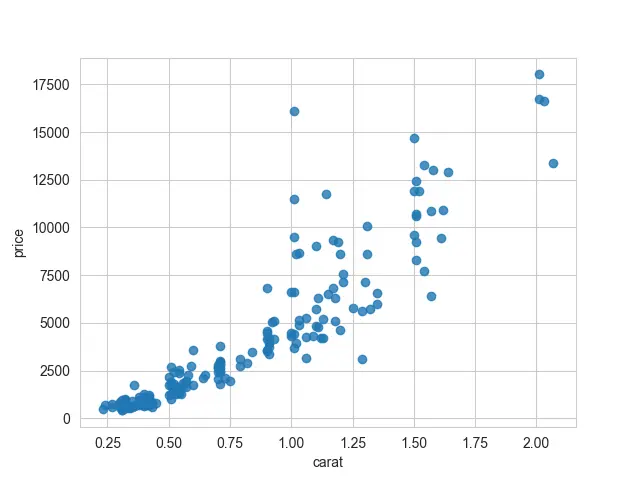
Si prefiere tener una gráfica con solo una línea de regresión, la otra opción que tenemos es solo trazar la línea de la regresión lineal. Tendremos que desactivar los puntos de dispersión utilizando el argumento dispersión, que debe ser igual a False.
import matplotlib.pyplot as plot
import seaborn as sb
DATA = sb.load_dataset("diamonds").dropna()
DATA.head()
DATA = DATA.sample(n=190, random_state=38)
sb.set_style("whitegrid")
sb.regplot(x="carat", y="price", data=DATA, scatter=False)
plot.show()
Producción:
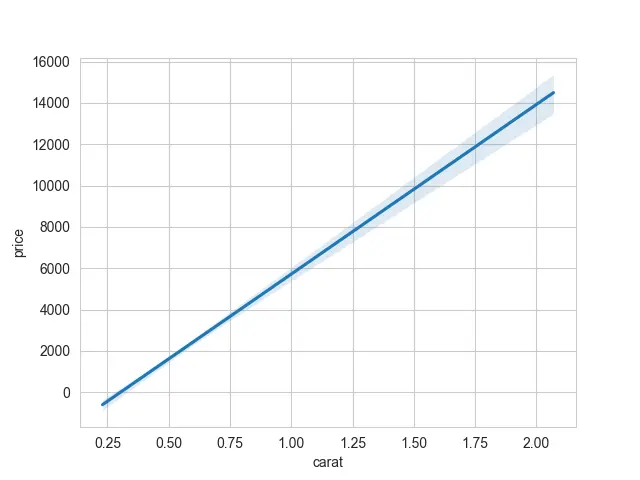
Verá la región con bandas con el área sombreada alrededor de su línea si traza el gráfico de regresión normal. Estos se denominan intervalos de confianza.
Si desea desactivarlo, puede usar el argumento ci y configurarlo como igual a Ninguno.
import matplotlib.pyplot as plot
import seaborn as sb
DATA = sb.load_dataset("diamonds").dropna()
DATA.head()
DATA = DATA.sample(n=190, random_state=38)
sb.set_style("whitegrid")
sb.regplot(x="carat", y="price", data=DATA, ci=None)
plot.show()
Producción:
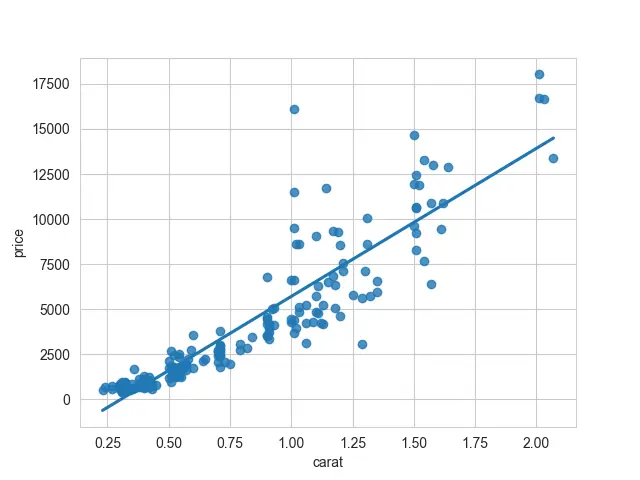
Desactivará por completo esos intervalos de confianza y le dará solo una línea en lugar de esa banda sombreada.
También queremos mostrarte lo que sucede si tienes una variable discreta que estás tratando de usar para uno de estos ejes. Entonces, convertiremos parte de la información en valores numéricos.
CUT_MAP = {"Fair": 1, "Good": 2, "Very Good": 3, "Premium": 4, "Ideal": 5}
Tenemos el “corte” de cada diamante, y solo lo estamos asignando a uno para el peor tipo de corte y configurando la categoría en orden ascendente.
DATA["CUT_VALUE"] = DATA.cut.map(CUT_MAP).cat.as_ordered()
Hemos creado una columna CUT_VALUE, y si la imprimes, verás que tenemos valores que van del 1 al 5.
import matplotlib.pyplot as plot
import seaborn as sb
DATA = sb.load_dataset("diamonds").dropna()
DATA.head()
DATA = DATA.sample(n=190, random_state=38)
sb.set_style("whitegrid")
CUT_MAP = {"Fair": 1, "Good": 2, "Very Good": 3, "Premium": 4, "Ideal": 5}
DATA["CUT_VALUE"] = DATA.cut.map(CUT_MAP).cat.as_ordered()
sb.regplot(x="CUT_VALUE", y="price", data=DATA)
plot.show()
Producción:
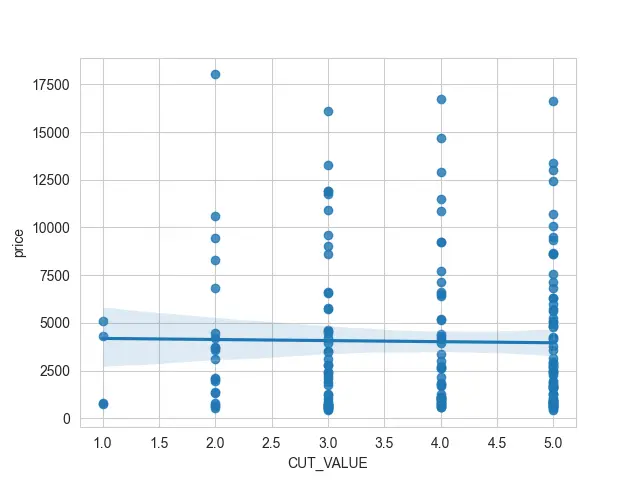
Si tratamos de usar esta columna CUT_VALUE como nuestro valor x, veremos muchos puntos de dispersión apilados uno encima del otro. Puede ser realmente difícil verlos debajo de esa regresión lineal.
Entonces, podemos agregar un poco de jitter, que controla la propiedad x_jitter. Tomará cada uno de mis puntos de dispersión y los moverá hacia la izquierda o hacia la derecha.
import numpy as np
import matplotlib.pyplot as plot
import seaborn as sb
DATA = sb.load_dataset("diamonds").dropna()
DATA.head()
DATA = DATA.sample(n=190, random_state=38)
sb.set_style("whitegrid")
CUT_MAP = {"Fair": 1, "Good": 2, "Very Good": 3, "Premium": 4, "Ideal": 5}
DATA["CUT_VALUE"] = DATA.cut.map(CUT_MAP).cat.as_ordered().astype(np.int8)
sb.regplot(x="CUT_VALUE", y="price", data=DATA, x_jitter=0.1)
plot.show()
Producción:
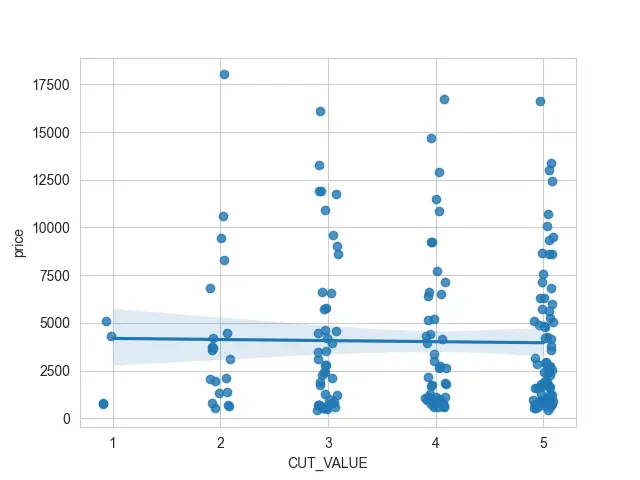
De esta manera, podemos ver dónde se agrupan los grupos de puntos de dispersión.
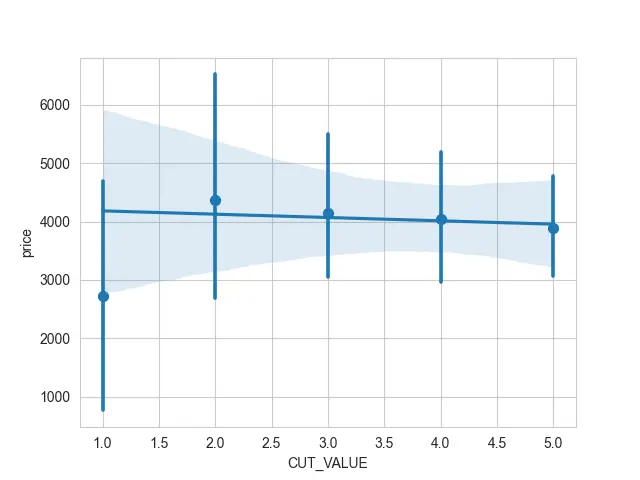
La otra cosa que podríamos hacer es si tenemos una variable discreta. Podemos usar un estimador para esos puntos usando el argumento x_estimator en lugar de graficar cada punto de dispersión individual.
import numpy as np
import matplotlib.pyplot as plot
import seaborn as sb
DATA = sb.load_dataset("diamonds").dropna()
DATA.head()
DATA = DATA.sample(n=190, random_state=38)
sb.set_style("whitegrid")
CUT_MAP = {"Fair": 1, "Good": 2, "Very Good": 3, "Premium": 4, "Ideal": 5}
DATA["CUT_VALUE"] = DATA.cut.map(CUT_MAP).cat.as_ordered().astype(np.int8)
sb.regplot(x="CUT_VALUE", y="price", data=DATA, x_estimator=np.mean)
plot.show()
Hemos agrupado esos puntos discretos y calculado la media y algunos intervalos de confianza para esos valores. Ahora, es fácil de leer a pesar de que tenemos muchos puntos apilados uno encima del otro.
Producción:

Hello! I am Salman Bin Mehmood(Baum), a software developer and I help organizations, address complex problems. My expertise lies within back-end, data science and machine learning. I am a lifelong learner, currently working on metaverse, and enrolled in a course building an AI application with python. I love solving problems and developing bug-free software for people. I write content related to python and hot Technologies.
LinkedIn