決定境界のプロット Python

写真、グラフ、およびプロットを使用して結果を視覚的に要約すると、人間の心は、与えられたデータのパターンを処理、理解、および認識する時間をよりゆっくりと得ることができます。 この記事では、Matplotlib の pyplot を使用して決定境界をプロットする手順を段階的に説明します。
このために、Sklearn ライブラリが提供する組み込みの前処理済みデータ (欠損データや異常値なし) データセット パッケージを使用して、データの決定境界をプロットします。 次に、Matplotlib のライブラリを使用して決定境界をプロットします。
前提ライブラリのインストール
Matplotlib の pyplot のプロット機能を使用するには、まず Matplotlib のライブラリをインストールする必要があります。 これは、次のコマンドを実行することで実現できます。
pip install matplotlib
また、正しい Python バージョンで作業することも不可欠です。 この記事では、バージョン 3.10.4 を使用しています。
次のコマンドを実行して、現在インストールされている Python のバージョンを確認できます。
python --version
決定境界
分類機械学習アルゴリズムは、入力例 (観察) にラベルを割り当てることを学習します。 分類の目的は、ラベルが特徴空間内のポイントにできるだけ正しく割り当てられるように、特徴空間を分離することです。
この方法は決定面または境界と呼ばれ、分類予測モデルの結果を視覚化するための実証ツールとして機能します。 少なくとも 2つの入力フィーチャに対して線形決定境界を作成できます。
ただし、入力フィーチャが 3つ以上ある場合は、多重線形決定境界を作成できます。 この記事では、2つの入力フィーチャの決定境界のプロットに焦点を当てます。
Matplotlib の pyplot を使用して、2つのクラスを分離する決定境界をプロットする
必要なライブラリをインポートする
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.model_selection import train_test_split
データセットを生成する
データセット クラス内の Sklearn ライブラリ make_blobs() 関数を使用して、カスタム データセットを生成します。 前述のように、使用する生成されたデータセットは、Sklearn ライブラリによって提供される組み込みの前処理済みデータ (欠損データや異常値なし) データセット パッケージです。
カスタム生成されたデータセット変数は次のとおりです。
samples features standard deviation
1000 2 3
XFeature, yFeature = datasets.make_blobs(
n_samples=1000, centers=2, n_features=2, random_state=1, cluster_std=3
)
データ生成が完了したら、データの散布図を作成して、大幅に改善された光でデータの変動性を確認できます。
for c_value in range(2):
row = np.where(yFeature == c_value)
plt.scatter(XFeature[row, 0], XFeature[row, 1])
plt.show()
次のステップでは、未知のデータを予測する分類モデルを構築します。 カスタム データセットには特徴が 2つしかないため、ロジスティック回帰を使用できます。
ロジスティック回帰モデル
sklearn ライブラリの Logistic Regression クラスが提供するロジスティック回帰モデル関数を使用し、サンプル データでトレーニングします。
regressor = LogisticRegression()
regressor.fit(XFeature, yFeature)
y_pred = regressor.predict(XFeature)
次に、sklearn ライブラリの accuracy_score クラスで精度を評価します。
accuracy = accuracy_score(y, y_pred)
print("Model Accuracy: %.3f" % accuracy)
決定境界の生成
Matplotlib は、contour() と呼ばれる貴重な関数を提供します。これは、異なるポイント間をプロットする際に色を追加するのに役立ちます。 これを実現するには、最初に特徴空間内のポイント Xfeature または YFeature のグリッドを初期化する必要があります。
それに続いて、各特徴の最大値と最小値を見つけ、これを 1 ずつ増やして空間全体がカバーされるようにする必要があります。
min1, max1 = XFeature[:, 0].min() - 1, XFeature[:, 0].max() + 1
min2, max2 = XFeature[:, 1].min() - 1, XFeature[:, 1].max() + 1
numpy ライブラリは、座標を 0.1 の解像度でスケーリングする arrange() 関数を提供します。
x1_scale = np.arange(min1, max1, 0.1)
x2_scale = np.arange(min2, max2, 0.1)
次のステップでは、numpy ライブラリは、スケーリングされた座標をグリッドに変換する meshgrid() 関数を提供します。
x_grid, y_grid = np.meshgrid(x1_scale, x2_scale)
それに続いて、numpy ライブラリによって提供される flatten() 関数を使用して、2 次元配列グリッドを 1 次元配列に縮小します。
x_g, y_g = x_grid.flatten(), y_grid.flatten()
x_g, y_g = x_g.reshape((len(x_g), 1)), y_g.reshape((len(y_g), 1))
最後に、1 次元配列を入力データセットの列として並べてスタックしますが、解像度ははるかに高くなります。
grid = np.hstack((x_g, y_g))
その後、これを上で作成した回帰モデルに当てはめて値を予測できます。
y_pred_2 = regressor.predict(grid) # predict the probability
# keep just the probabilities for class 0
p_pred = regressor.predict_proba(grid)
p_pred = p_pred[:, 0] # reshaping the results
p_pred.shape
pp_grid = p_pred.reshape(x_grid.shape)
次に、contourf() を使用して、さまざまな色を使用して、予測されたグリッドを等高線図としてプロットします。
surface = plt.contourf(x_grid, y_grid, pp_grid, cmap="Pastel1")
plt.colorbar(surface) # create scatter plot for samples from each class
for class_value in range(2):
row_ix = np.where(y == class_value)
plt.scatter(X[row_ix, 0], X[row_ix, 1], cmap="Pastel1")
plt.show()
したがって、最終的には、2つのクラスを分離する決定境界をプロットする次のスクリプトになります。
完全なコード:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.model_selection import train_test_split
XFeature, yFeature = datasets.make_blobs(
n_samples=1000, centers=2, n_features=2, random_state=1, cluster_std=3
)
for c_val in range(2):
row = np.where(yFeature == c_val)
plt.scatter(XFeature[row, 0], XFeature[row, 1])
plt.show()
reg = LogisticRegression()
reg.fit(XFeature, yFeature)
y_pred = reg.predict(XFeature)
acc = accuracy_score(yFeature, y_pred)
print("Accuracy: %.3f" % acc)
min1, max1 = XFeature[:, 0].min() - 1, XFeature[:, 0].max() + 1
min2, max2 = XFeature[:, 1].min() - 1, XFeature[:, 1].max() + 1
x1_scale = np.arange(min1, max1, 0.1)
x2_scale = np.arange(min2, max2, 0.1)
x_grid, y_grid = np.meshgrid(x1_scale, x2_scale)
x_g, y_g = x_grid.flatten(), y_grid.flatten()
x_g, y_g = x_g.reshape((len(x_g), 1)), y_g.reshape((len(y_g), 1))
grid = np.hstack((x_g, y_g))
y_pred_2 = reg.predict(grid)
p_pred = reg.predict_proba(grid)
p_pred = p_pred[:, 0]
pp_grid = p_pred.reshape(x_grid.shape)
surface = plt.contourf(x_grid, y_grid, pp_grid, cmap="Pastel1")
plt.colorbar(surface)
for class_value in range(2):
row_ix = np.where(yFeature == class_value)
plt.scatter(XFeature[row_ix, 0], XFeature[row_ix, 1], cmap="Pastel1")
plt.show()
出力:
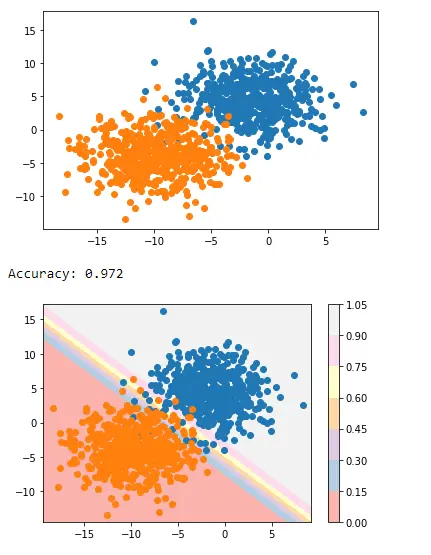
これは、Matplotlib の pyplot を使用して 2つのクラスを分離する決定境界を適用する方法です。

I am Fariba Laiq from Pakistan. An android app developer, technical content writer, and coding instructor. Writing has always been one of my passions. I love to learn, implement and convey my knowledge to others.
LinkedIn