Pandas で DataFrame をピボットする
この短い記事では、Pandas で DataFrame をピボットする方法について説明します。
pivot() 関数を使用して Pandas で DataFrame をピボットする
特定の DataFrame は、指定されたインデックスと列の値を使用して pivot() メソッドを使用して再形成できます。 pivot() 関数はデータ集計をサポートしていません。 複数の値は、列に MultiIndex を生成します。
列を使用して、新しいフレームのインデックスを作成しました。 ピボット関数は、指定されたテーブルから新しい派生テーブルを生成します。 None の場合、既存のインデックスが使用されます。
ピボットが受け入れる 3つの引数は、index、columns、および values です。 各パラメータの値として、元のテーブルの列名を指定する必要があります。
pivot() 関数は、行と列のインデックスとして指定されたパラメーターの一意の値を持つ新しいテーブルを生成します。 新しいテーブルのセル値は、値パラメーターとして指定された列から取得されます。
コード例:
from collections import OrderedDict
from pandas import DataFrame
import pandas as pd
import numpy as np
table = OrderedDict(
(
("ID", ["ID1", "ID2", "ID3", "ID4"]),
("Std", ["Harry", "Ron", "Daniel", "Kelvin"]),
("Subject", ["Maths", "English", "Maths", "English"]),
("Marks", ["70", "50", "70", "50"]),
)
)
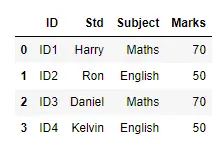
d = DataFrame(table)
display(d)
出力:
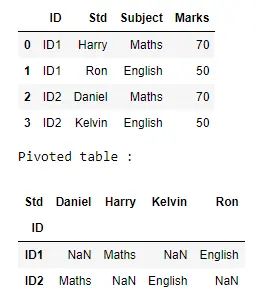
以下の例は、新しいテーブルに移動された元のテーブルの各行のサブジェクト値を示しています。ここで、その行と列は元の行の ID と Std に対応しています。 NaN 値は、既存のエントリと一致しない新しいテーブルのセルに配置されます。
コード例:
from collections import OrderedDict
from pandas import DataFrame
import pandas as pd
import numpy as np
table = OrderedDict(
(
("ID", ["ID1", "ID1", "ID2", "ID2"]),
("Std", ["Harry", "Ron", "Daniel", "Kelvin"]),
("Subject", ["Maths", "English", "Maths", "English"]),
("Marks", ["70", "50", "70", "50"]),
)
)
d = DataFrame(table)
display(d)
print("Pivoted table : ")
p = d.pivot(index="ID", columns="Std", values="Subject")
display(p)
出力:

I am Fariba Laiq from Pakistan. An android app developer, technical content writer, and coding instructor. Writing has always been one of my passions. I love to learn, implement and convey my knowledge to others.
LinkedIn