Pandas에서 DataFrame 피벗
이 짧은 기사에서는 Pandas에서 DataFrame을 피벗하는 방법에 대해 설명합니다.
pivot() 함수를 사용하여 Pandas에서 DataFrame 피벗
주어진 DataFrame은 지정된 인덱스 및 열 값을 사용하는 pivot() 메서드를 사용하여 재구성할 수 있습니다. pivot() 함수는 데이터 집계를 지원하지 않습니다. 여러 값은 열에서 MultiIndex를 생성합니다.
열을 사용하여 새 프레임의 인덱스를 만듭니다. 피벗 함수는 주어진 테이블에서 새로운 파생 테이블을 생성합니다. None이면 기존 색인을 사용합니다.
피벗이 허용하는 세 가지 인수는 index, columns 및 values입니다. 각 매개변수의 값으로 원래 테이블의 열 이름을 지정해야 합니다.
pivot() 함수는 지정된 매개변수에 대한 고유 값을 행 및 열 인덱스로 사용하여 새 테이블을 생성합니다. 새 테이블의 셀 값은 values 매개변수로 지정된 열에서 가져옵니다.
예제 코드:
from collections import OrderedDict
from pandas import DataFrame
import pandas as pd
import numpy as np
table = OrderedDict(
(
("ID", ["ID1", "ID2", "ID3", "ID4"]),
("Std", ["Harry", "Ron", "Daniel", "Kelvin"]),
("Subject", ["Maths", "English", "Maths", "English"]),
("Marks", ["70", "50", "70", "50"]),
)
)
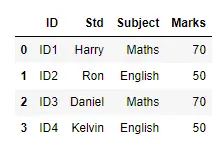
d = DataFrame(table)
display(d)
출력:
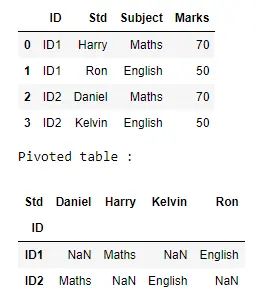
아래 예는 새 테이블로 이동된 원래 테이블의 각 행에 대한 주제 값을 보여줍니다. 여기서 해당 행과 열은 원래 행의 ID 및 Std에 해당합니다. NaN 값은 기존 테이블의 항목과 일치하지 않는 새 테이블의 셀에 입력됩니다.
예제 코드:
from collections import OrderedDict
from pandas import DataFrame
import pandas as pd
import numpy as np
table = OrderedDict(
(
("ID", ["ID1", "ID1", "ID2", "ID2"]),
("Std", ["Harry", "Ron", "Daniel", "Kelvin"]),
("Subject", ["Maths", "English", "Maths", "English"]),
("Marks", ["70", "50", "70", "50"]),
)
)
d = DataFrame(table)
display(d)
print("Pivoted table : ")
p = d.pivot(index="ID", columns="Std", values="Subject")
display(p)
출력:

I am Fariba Laiq from Pakistan. An android app developer, technical content writer, and coding instructor. Writing has always been one of my passions. I love to learn, implement and convey my knowledge to others.
LinkedIn