Pandas で複数列の GroupBy と Aggregate を行う

Pandas ライブラリは、Python の強力なデータ分析ライブラリです。Python の Pandas を使用して、データフレームに対してさまざまな種類の操作を実行できます。
groupby() は、特定の基準に基づいてデータを複数のグループに分割するメソッドです。その後、グループ化されたデータに対して特定の操作を実行できます。
Pandas Python の複数の列に groupby() および aggregate() 関数を適用する
複数の列のデータをグループ化し、いくつかの aggregate() メソッドを適用する必要がある場合があります。aggregate() メソッドは、複数の行の値を組み合わせて単一の値を返すメソッドです。たとえば、count()、size()、mean()、sum()、mean() など
次のコードには、いくつかの列の冗長な値を含む学生のデータがあります。生徒の名前とセクションに基づいてデータをグループ化して合計点数を取得する場合は、名前とセクションに従ってデータをグループ化し、aggregate() メソッドを使用して合計点数を計算します。
返された結果を保存して表示しました。
サンプルコード:
# Python 3.x
import pandas as pd
student = {
"Name": ["Jhon", "Alia", "Jhon", "Alia", "Sam", "Smith", "Sam", "Smith"],
"Section": ["A", "A", "A", "A", "B", "B", "B", "B"],
"Course": ["Java", "Java", "Dart", "Dart", "Java", "Java", "Dart", "Dart"],
"Marks": [70, 80, 90, 60, 80, 90, 50, 80],
}
df = pd.DataFrame(student)
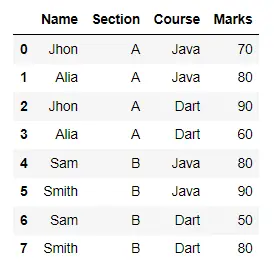
display(df)
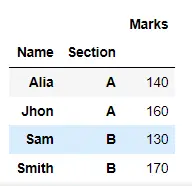
result = df.groupby(["Name", "Section"]).aggregate("sum")
display(result)
出力:
一度に複数の集計操作を実行することもできます。操作名のリストを aggregate() メソッドに渡します。
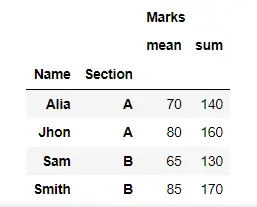
ここでは、操作名のリストを渡すことにより、aggregate() メソッドを使用して、学生の平均点と合計点を一度に計算しました。
サンプルコード:
# Python 3.x
import pandas as pd
student = {
"Name": ["Jhon", "Alia", "Jhon", "Alia", "Sam", "Smith", "Sam", "Smith"],
"Section": ["A", "A", "A", "A", "B", "B", "B", "B"],
"Course": ["Java", "Java", "Dart", "Dart", "Java", "Java", "Dart", "Dart"],
"Marks": [70, 80, 90, 60, 80, 90, 50, 80],
}
df = pd.DataFrame(student)
display(df)
result = df.groupby(["Name", "Section"]).aggregate(["mean", "sum"])
display(result)
出力:

I am Fariba Laiq from Pakistan. An android app developer, technical content writer, and coding instructor. Writing has always been one of my passions. I love to learn, implement and convey my knowledge to others.
LinkedIn