SciPy scipy.stats.norm
-
二項分布を計算するための
scipy.stats.norm()の構文: -
コード例:
scipy.stats.normを使用した特定の値の確率分布関数(PDF)値の計算 -
サンプルコード:
scipy.stats.norm()を使用した分布の累積分布関数(CDF)の計算 -
コード例:
scipy.stats.norm()を使用した分布のランダム変量(rvs)の計算
Python Scipy scipy.stats.norm オブジェクトは、正規分布を分析し、使用可能なさまざまな方法を使用してさまざまな分布関数値を計算するために使用されます。
二項分布を計算するための scipy.stats.norm() の構文:
使用されるさまざまな方法に基づいて、いくつかの一般的な最適パラメータを以下に示します。
scipy.stats.norm.method(x, loc, scale, size, moments)
scipy.stats.norm() オブジェクトで使用可能なメソッド
norm.pdf() |
n 次元配列を返します。これは、x で計算された確率密度関数です。 |
norm.cdf() |
x のすべての値の累積確率を返します。 |
norm.rvs() |
ランダムな変量を返します。 |
norm.stats() |
定義された mvsk に従って、平均、分散、標準偏差、または尖度を返します。 |
norm.logpdf() |
確率分布関数の対数を返します。 |
norm.median() |
正規分布の中央値を返します。 |
パラメーター
x |
配列のような。これは、均等なサイズのサンプルを表す値のセットです。 |
loc |
位置パラメータ。loc は平均値を表します。デフォルト値は 0 です。 |
scale |
スケールパラメータ。scale は標準偏差を表します。デフォルト値は 1 です。 |
moments |
これは、統計、つまり平均、分散、標準偏差、および尖度を計算するために使用されます。デフォルト値は mv です。 |
戻り値
使用したメソッドに従って値を返します。
コード例:scipy.stats.norm を使用した特定の値の確率分布関数(PDF)値の計算
scipy.stats.norm.pdf() メソッドを使用して、指定された観測値の確率分布関数(PDF)値を生成できます。
import numpy as np
import matplotlib.pyplot as plt
import scipy
from scipy import stats
x = np.linspace(-3, 3, 100)
pdf_result = stats.norm.pdf(x, loc=0, scale=1)
plt.plot(x, pdf_result)
plt.xlabel("x-data")
plt.ylabel("pdf_value")
plt.title("PDF of a Normal Distribution with mean=0 and sigma=1")
plt.show()
出力:
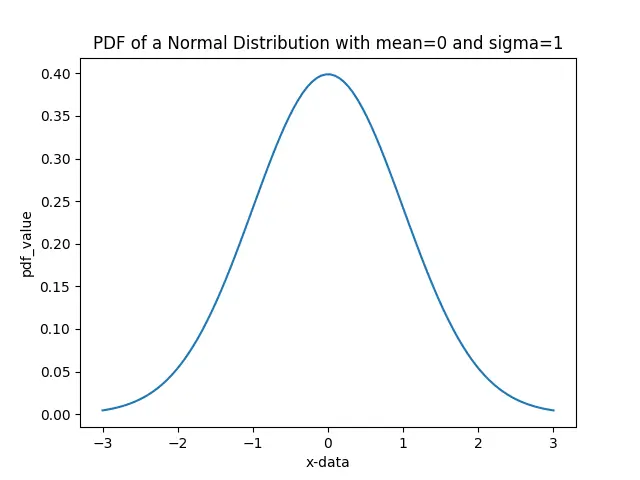
x が PDF が決定される観測値を表すと仮定します。次に、x の各値の確率分布関数(PDF)を計算し、Matplotlib を使用して分布関数をプロットします。
確率密度関数の値を計算するには、基礎となる正規分布の平均と標準偏差を知る必要があります。平均と標準偏差の値は、pdf メソッドでそれぞれ loc と scale パラメーターとして渡されます。
上記の例では、基礎となる分布の平均値が 0 で標準偏差値が 1 であると仮定して、pdf 値を計算します。平均に近い観測値は、より高い確率を持っています。一方、上のプロットに見られるように、平均から離れた値は確率が低くなります。
コード例: 平均値と標準偏差値を scipy.stats.norm に設定する
import numpy as np
import matplotlib.pyplot as plt
import scipy
from scipy import stats
x = np.linspace(-10, 10, 100)
pdf_result = stats.norm.pdf(x, loc=3, scale=2)
plt.plot(x, pdf_result)
plt.xlabel("x-data")
plt.ylabel("pdf_value")
plt.title("PDF of a Normal Distribution with mean=3 and sigma=2")
plt.show()
出力:
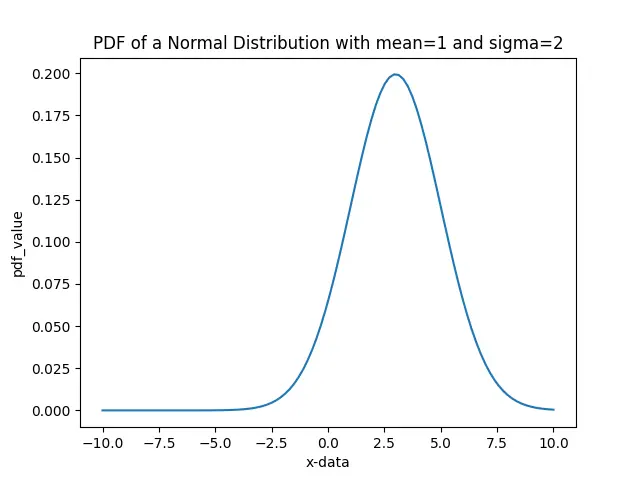
これは、平均値 3 とシグマ値 2 の正規分布の PDF プロットです。したがって、3 に近い観測は確率が高く、3 から離れた観測は確率が低くなります。
サンプルコード:scipy.stats.norm() を使用した分布の累積分布関数(CDF)の計算
import numpy as np
import matplotlib.pyplot as plt
import scipy
from scipy import stats
x = np.linspace(-3, 3, 100)
cdf_values = stats.norm.cdf(x, loc=0, scale=1)
plt.plot(x, cdf_values)
plt.xlabel("x-data")
plt.ylabel("pdf_value")
plt.title("CDF of a Normal Distribution with mean=0 and sigma=1")
plt.show()
出力:
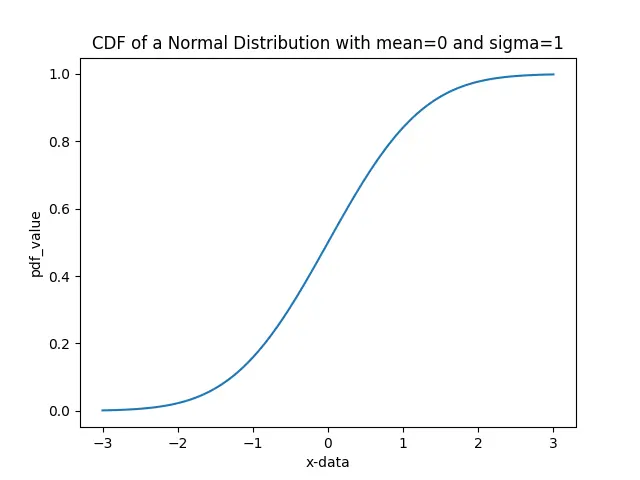
これは pdf の積分です。与えられた分布の CDF が増加していることがわかります。CDF は、母集団から取得された値が、ある値以下の確率値を持つことを示しています。
コード例:scipy.stats.norm() を使用したポイントでの累積分布関数(CDF)値の計算
import numpy as np
import matplotlib.pyplot as plt
import scipy
from scipy import stats
x = 2
cdf_value = stats.norm.cdf(x, loc=0, scale=1)
print(
"CDF Value of x=2 in normal distribution with mean 0 and standard deviation 1 is :"
+ str(cdf_value)
)
出力:
CDF Value of x=2 in normal distribution with mean 0 and standard deviation 1 is :0.9772498680518208.
これは、平均= 0、標準偏差 1 が 0.977 の正規分布からサンプリングしているときに、2 以下の値が発生する確率を意味します。
コード例:scipy.stats.norm() を使用した分布のランダム変量(rvs)の計算
import numpy as np
import matplotlib.pyplot as plt
import scipy
from scipy.stats import norm
rvs_values = stats.norm.rvs(loc=5, scale=10, size=(5, 2))
print("The random generated value are\n", rvs_values)
出力:
The random generated value are
[[ -8.38511257 16.81403567]
[ 15.78217954 -8.92401338]
[ 14.55202276 -0.6388562 ]
[ 2.19024898 3.75648045]
[-10.95451165 -3.98232268]]
ここで、rvs 値は、平均 5 および標準偏差 10 の正規分布からサンプリングされたランダムに生成された変量です。size は、配列出力のサイズを指定します。