SciPy scipy.stats.norm
-
Syntax von
scipy.stats.norm()zur Berechnung der Binomialverteilung: -
Beispielcodes:
Berechnung der Werte der Wahrscheinlichkeitsverteilungsfunktion (PDF)von gegebenen Werten unter Verwendung vonscipy.stats.norm -
Beispielcode: Berechnung der kumulativen Verteilungsfunktion (CDF) der Verteilung mit
scipy.stats.norm() -
Beispielcodes: Berechnung von Zufallsvariablen (rvs) der Verteilung mit
scipy.stats.norm()
Das Python-Scipy-Objekt scipy.stats.norm wird verwendet, um die Normalverteilung zu analysieren und ihre verschiedenen Verteilungsfunktionswerte mit den verschiedenen verfügbaren Methoden zu berechnen.
Syntax von scipy.stats.norm() zur Berechnung der Binomialverteilung:
Basierend auf den verschiedenen verwendeten Methoden sind einige allgemeine optimale Parameter unten aufgeführt:
scipy.stats.norm.method(x, loc, scale, size, moments)
Verfügbare Methoden im Objekt scipy.stats.norm()
norm.pdf() |
Gibt ein n-dimensionales Array zurück. Es ist die bei x berechnete Wahrscheinlichkeitsdichtefunktion. |
norm.cdf() |
Gibt die kumulative Wahrscheinlichkeit für jeden Wert von x zurück. |
norm.rvs() |
Gibt Zufallsvariablen zurück. |
norm.stats() |
Gibt Mittelwert, Varianz, Standardabweichung oder Kurtosis gemäß mvsk-Definition zurück. |
norm.logpdf() |
Gibt das Protokoll der Wahrscheinlichkeitsverteilungsfunktion zurück. |
norm.median() |
Gibt den Median der Normalverteilung zurück. |
Parameter
x |
Array-artig. Es ist der Satz von Werten, der die Stichprobe mit gleicher Größe darstellt. |
loc |
Standortparameter. loc repräsentiert den Mittelwert. Sein Standardwert ist 0. |
scale |
Skalierungsparameter. scale repräsentiert die Standardabweichung. Sein Standardwert ist 1. |
moments |
Es wird verwendet, um Statistiken zu berechnen, d. h. Mittelwert, Varianz, Standardabweichung und Kurtosis. Sein Standardwert ist mv. |
Zurückkehren
Es gibt Werte gemäß den verwendeten Methoden zurück.
Beispielcodes: Berechnung der Werte der Wahrscheinlichkeitsverteilungsfunktion (PDF) von gegebenen Werten unter Verwendung von scipy.stats.norm
Wir können die Methode scipy.stats.norm.pdf() verwenden, um den Wert der Wahrscheinlichkeitsverteilungsfunktion (PDF) der gegebenen Beobachtungen zu generieren.
import numpy as np
import matplotlib.pyplot as plt
import scipy
from scipy import stats
x = np.linspace(-3, 3, 100)
pdf_result = stats.norm.pdf(x, loc=0, scale=1)
plt.plot(x, pdf_result)
plt.xlabel("x-data")
plt.ylabel("pdf_value")
plt.title("PDF of a Normal Distribution with mean=0 and sigma=1")
plt.show()
Ausgabe:
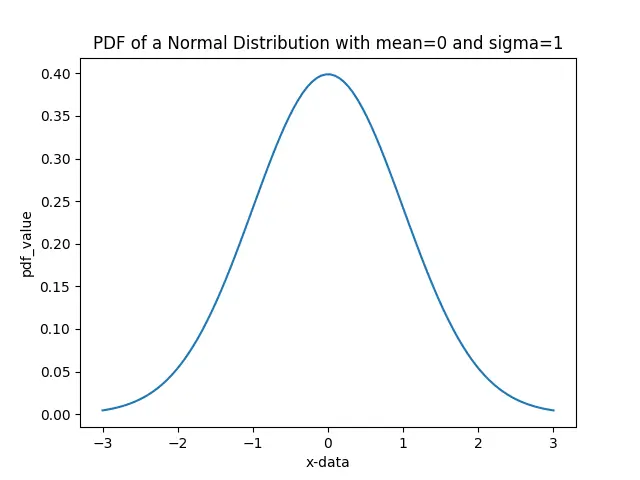
Angenommen, x stellt die Beobachtungswerte dar, deren PDF bestimmt werden soll. Jetzt berechnen wir die Wahrscheinlichkeitsverteilungsfunktion (PDF) jedes Werts im x und zeichnen die Verteilungsfunktion mit Matplotlib.
Um den Wert der Wahrscheinlichkeitsdichtefunktion zu berechnen, müssen wir den Mittelwert und die Standardabweichung der zugrunde liegenden Normalverteilung kennen. Die Werte von Mittelwert und Standardabweichung werden als Parameter loc und scale in der pdf-Methode übergeben.
Im obigen Beispiel berechnen wir PDF-Werte unter der Annahme, dass die zugrunde liegende Verteilung einen Mittelwert von 0 und einen Standardabweichungswert von 1 hat. Die Beobachtungen nahe dem Mittelwert haben eine höhere Wahrscheinlichkeit. Andererseits haben die Werte abseits des Mittelwerts eine geringere Wahrscheinlichkeit, wie im Diagramm oben zu sehen ist.
Beispielcodes: Mittelwert und Standardabweichungswerte in scipy.stats.norm festlegen
import numpy as np
import matplotlib.pyplot as plt
import scipy
from scipy import stats
x = np.linspace(-10, 10, 100)
pdf_result = stats.norm.pdf(x, loc=3, scale=2)
plt.plot(x, pdf_result)
plt.xlabel("x-data")
plt.ylabel("pdf_value")
plt.title("PDF of a Normal Distribution with mean=3 and sigma=2")
plt.show()
Ausgabe:
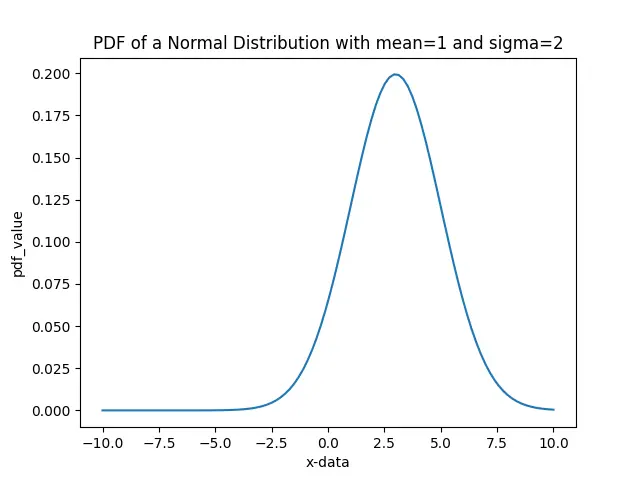
Es ist der PDF-Plot einer Normalverteilung mit Mittelwert 3 und Sigma-Wert 2. Daher haben Beobachtungen in der Nähe von 3 eine höhere Wahrscheinlichkeit, während solche, die von 3 entfernt sind, eine geringere Wahrscheinlichkeit haben.
Beispielcode: Berechnung der kumulativen Verteilungsfunktion (CDF) der Verteilung mit scipy.stats.norm()
import numpy as np
import matplotlib.pyplot as plt
import scipy
from scipy import stats
x = np.linspace(-3, 3, 100)
cdf_values = stats.norm.cdf(x, loc=0, scale=1)
plt.plot(x, cdf_values)
plt.xlabel("x-data")
plt.ylabel("pdf_value")
plt.title("CDF of a Normal Distribution with mean=0 and sigma=1")
plt.show()
Ausgabe:
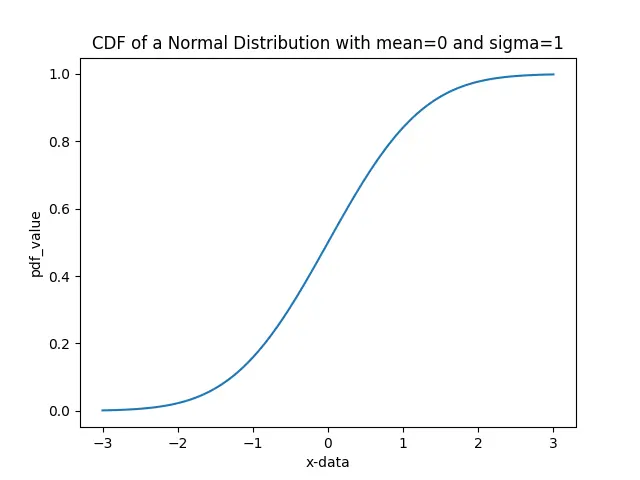
Es ist das Integral von pdf. Wir können sehen, dass der CDF der gegebenen Verteilung zunimmt. CDF zeigt uns, dass jeder aus der Population entnommene Wert einen Wahrscheinlichkeitswert kleiner oder gleich einem bestimmten Wert haben wird.
Beispielcode: Berechnung des Werts der kumulativen Verteilungsfunktion (CDF) an einem Punkt mit scipy.stats.norm()
import numpy as np
import matplotlib.pyplot as plt
import scipy
from scipy import stats
x = 2
cdf_value = stats.norm.cdf(x, loc=0, scale=1)
print(
"CDF Value of x=2 in normal distribution with mean 0 and standard deviation 1 is :"
+ str(cdf_value)
)
Ausgabe:
CDF Value of x=2 in normal distribution with mean 0 and standard deviation 1 is :0.9772498680518208.
Es impliziert die Wahrscheinlichkeit des Auftretens eines Wertes kleiner oder gleich 2, während die Stichprobe aus einer Normalverteilung mit Mittelwert = 0 und Standardabweichung 1: 0,977 beträgt.
Beispielcodes: Berechnung von Zufallsvariablen (rvs) der Verteilung mit scipy.stats.norm()
import numpy as np
import matplotlib.pyplot as plt
import scipy
from scipy.stats import norm
rvs_values = stats.norm.rvs(loc=5, scale=10, size=(5, 2))
print("The random generated value are\n", rvs_values)
Ausgabe:
The random generated value are
[[ -8.38511257 16.81403567]
[ 15.78217954 -8.92401338]
[ 14.55202276 -0.6388562 ]
[ 2.19024898 3.75648045]
[-10.95451165 -3.98232268]]
Hier sind die rvs-Werte die zufällig generierten Variablen, die aus der Normalverteilung mit dem Mittelwert 5 und der Standardabweichung 10 entnommen wurden. Die Größe gibt die Größe der Array-Ausgabe an.