Python Pandas pandas.pivot_table() 関数
Minahil Noor
2023年1月30日
Pandas
Pandas Core
-
pandas.pivot_table()の構文 -
コード例:
pandas.pivot_table() -
コード例:複数の集約関数を指定するには
pandas.pivot_table()を用いる -
コード例:
marginsパラメーターを使用するためのpandas.pivot_table()
Python Pandas pandas.pivot_table() 関数は DataFrame のデータの繰り返しを回避します。この関数はデータを要約し、データに対して異なる集計関数を適用します。
pandas.pivot_table() の構文
pandas.pivot_table(
data,
values=None,
index=None,
columns=None,
aggfunc="mean",
fill_value=None,
margins=False,
dropna=True,
margins_name="All",
observed=False,
)
パラメータ
この関数はいくつかのパラメータを持っています。すべてのパラメータのデフォルト値は上記の通りです。
data |
これは繰り返しデータを削除したい DataFrame です。 |
values |
これは集約するカラムを表します。 |
index |
これは column、grouper, 配列, リストのいずれかです。インデックスにしたいデータ列、つまり行を表します。 |
columns |
これは column、grouper, 配列, リストのいずれかです。これは出力ピボットテーブルのカラムとして利用したいデータカラムを表します。 |
aggfunc |
これは関数、関数のリスト、または dictionary です。これはデータに適用される集約関数を表します。集約関数のリストが渡された場合は、結果のテーブルに各集約関数のカラムが作成され、カラム名が先頭に表示されます。 |
fill_value |
これはスカラです。出力テーブルの欠落している値を置き換える値を表します。 |
margins |
ブール値です。これは、それぞれの行と列の合計を取った後に生成される行と列を表します。 |
dropna |
これはブール値です。値が NaN であるカラムを出力テーブルから削除します。 |
margins_name |
これは文字列です。margins の値が True の場合に生成される行と列の名前を表します。 |
observed |
これはブール値です。いずれかのハタがカテゴリカルなものであれば、このパラメータが適用されます。True の場合は、分類されたハタの観測値を表示します。False の場合は、カテゴリカルハタの全ての値を表示します。 |
リターン
要約した DataFrame を返します。
コード例:pandas.pivot_table()
この関数を実装して掘り下げてみましょう。
import pandas as pd
dataframe = pd.DataFrame({
"Name":
["Olivia",
"Olivia",
"Olivia",
"Olivia",
"Meghan",
"Meghan",
"Meghan",
"Meghan"],
"Date":
["03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019"],
"Science Marks":
[10,
2,
4,
6,
8,
9,
1,
10]
})
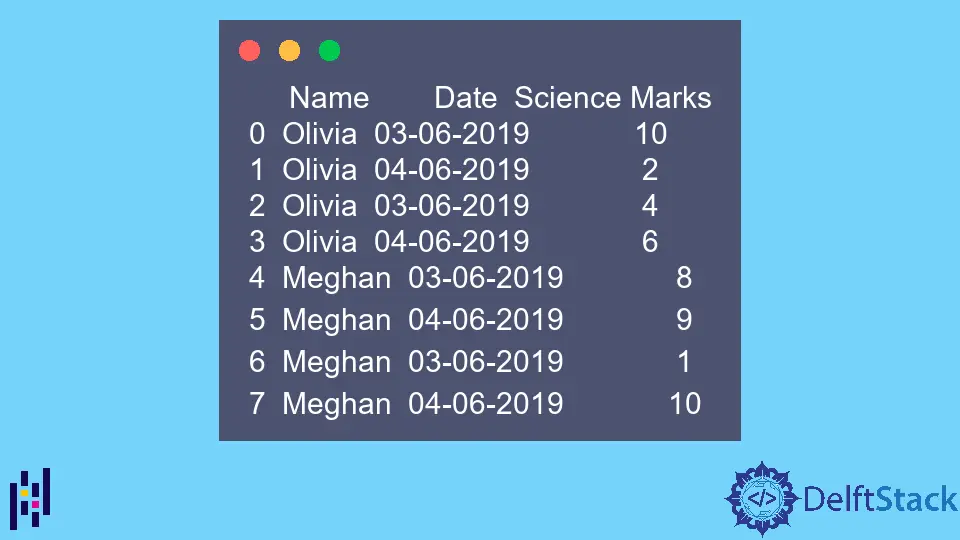
print(dataframe)
DataFrame の例は、
Name Date Science Marks
0 Olivia 03-06-2019 10
1 Olivia 04-06-2019 2
2 Olivia 03-06-2019 4
3 Olivia 04-06-2019 6
4 Meghan 03-06-2019 8
5 Meghan 04-06-2019 9
6 Meghan 03-06-2019 1
7 Meghan 04-06-2019 10
上記のデータは、同じ値が複数回列に含まれていることに注意してください。この pivot_table 関数はこのデータをまとめます。
import pandas as pd
dataframe = pd.DataFrame(
{
"Name": [
"Olivia",
"Olivia",
"Olivia",
"Olivia",
"Meghan",
"Meghan",
"Meghan",
"Meghan",
],
"Date": [
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
],
"Science Marks": [10, 2, 4, 6, 8, 9, 1, 10],
}
)
pivotTable = pd.pivot_table(dataframe, index="Name", columns="Date")
print(pivotTable)
出力:
Science Marks
Date 03-06-2019 04-06-2019
Name
Meghan 4.5 9.5
Olivia 7.0 4.0
ここでは、インデックスに Name カラムを、カラムに Date を選択しています。この関数はデフォルトのパラメータに基づいて結果を生成しています。デフォルトの集約関数 mean は値の平均を計算します。
コード例:複数の集約関数を指定するには pandas.pivot_table() を用いる
import pandas as pd
dataframe = pd.DataFrame(
{
"Name": [
"Olivia",
"Olivia",
"Olivia",
"Olivia",
"Meghan",
"Meghan",
"Meghan",
"Meghan",
],
"Date": [
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
],
"Science Marks": [10, 2, 4, 6, 8, 9, 1, 10],
}
)
pivotTable = pd.pivot_table(
dataframe, index="Name", columns="Date", aggfunc=["sum", "count"]
)
print(pivotTable)
出力:
sum count
Science Marks Science Marks
Date 03-06-2019 04-06-2019 03-06-2019 04-06-2019
Name
Meghan 9 19 2 2
Olivia 14 8 2 2
2つの集約関数を使用しました。これらの関数のカラムは別々に生成されます。
コード例:margins パラメーターを使用するための pandas.pivot_table()
import pandas as pd
dataframe = pd.DataFrame(
{
"Name": [
"Olivia",
"Olivia",
"Olivia",
"Olivia",
"Meghan",
"Meghan",
"Meghan",
"Meghan",
],
"Date": [
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
],
"Science Marks": [10, 2, 4, 6, 8, 9, 1, 10],
}
)
pivotTable = pd.pivot_table(
dataframe, index="Name", columns="Date", aggfunc=["sum", "count"], margins=True
)
print(pivotTable)
出力:
sum count
Science Marks Science Marks
Date 03-06-2019 04-06-2019 All 03-06-2019 04-06-2019 All
Name
Meghan 9 19 28 2 2 4
Olivia 14 8 22 2 2 4
All 23 27 50 4 4 8
パラメータ margins は All という名前の新しい行と All という名前の新しい列を生成し、それぞれ行と列の合計を示します。
チュートリアルを楽しんでいますか? <a href="https://www.youtube.com/@delftstack/?sub_confirmation=1" style="color: #a94442; font-weight: bold; text-decoration: underline;">DelftStackをチャンネル登録</a> して、高品質な動画ガイドをさらに制作するためのサポートをお願いします。 Subscribe