Función Python Pandas pandas.pivot_table()
-
La sintaxis de
pandas.pivot_table() -
Códigos de ejemplo:
pandas.pivot_table() -
Códigos de ejemplo:
pandas.pivot_table()para especificar la función de agregación múltiple -
Códigos de ejemplo:
pandas.pivot_table()para usar el parámetromargins
La función Python Pandas pandas.pivot_table() evita la repetición de datos del DataFrame. Resume los datos y aplica diferentes funciones de agregación a los datos.
La sintaxis de pandas.pivot_table()
pandas.pivot_table(
data,
values=None,
index=None,
columns=None,
aggfunc="mean",
fill_value=None,
margins=False,
dropna=True,
margins_name="All",
observed=False,
)
Parámetros
Esta función tiene varios parámetros. Los valores por defecto de todos los parámetros se mencionan más arriba.
data |
Es el DataFrame del que queremos eliminar los datos repetidos. |
values |
Representa la columna para agregar. |
index |
Es una column, grouper, matriz, o una lista. Representa la columna de datos que queremos como índice, es decir, como filas. |
columns |
Es una column, grouper, matriz, o una lista. Representa la columna de datos que queremos como columnas en nuestra tabla pivote de salida. |
aggfunc |
Es una función, una lista de funciones o un diccionario. Representa la función agregada que se aplicará a los datos. Si se pasa una lista de funciones agregadas, habrá una columna para cada función agregada en el cuadro resultante con el nombre de la columna en la parte superior. |
fill_value |
Es un escalar. Representa el valor que sustituirá a los valores que faltan en la tabla de salida |
margins |
Es un valor booleano. Representa la fila y la columna generadas después de tomar la suma de la respectiva fila y columna. |
dropna |
Es un valor booleano. Elimina las columnas cuyos valores son NaN de la tabla de salida. |
margins_name |
Es una cuerda. Representa el nombre de la fila y la columna generada si el valor de los margins es True. |
observed |
Es un valor booleano. Si algún mero es categórico, entonces este parámetro se aplica. Si es True, muestra los valores observados para los meros categóricos. Si es False, muestra todos los valores de los meros categóricos. |
Retorna
Devuelve el resumen de DataFrame.
Códigos de ejemplo: pandas.pivot_table()
Profundicemos en esta función implementándola.
import pandas as pd
dataframe = pd.DataFrame({
"Name":
["Olivia",
"Olivia",
"Olivia",
"Olivia",
"Meghan",
"Meghan",
"Meghan",
"Meghan"],
"Date":
["03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019"],
"Science Marks":
[10,
2,
4,
6,
8,
9,
1,
10]
})
print(dataframe)
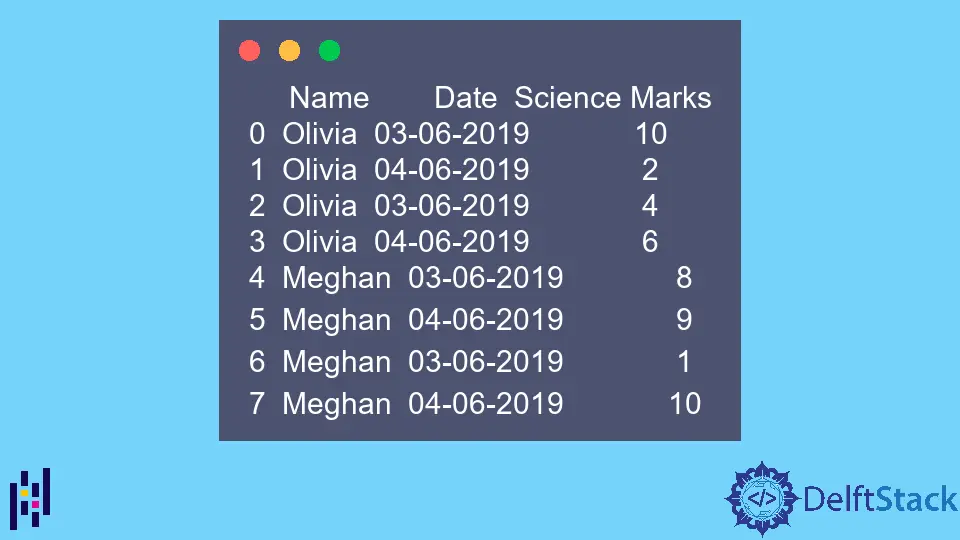
El ejemplo DataFrame es,
Name Date Science Marks
0 Olivia 03-06-2019 10
1 Olivia 04-06-2019 2
2 Olivia 03-06-2019 4
3 Olivia 04-06-2019 6
4 Meghan 03-06-2019 8
5 Meghan 04-06-2019 9
6 Meghan 03-06-2019 1
7 Meghan 04-06-2019 10
Obsérvese que los datos anteriores contienen el mismo valor en una columna varias veces. Esta función pivot_table resumirá estos datos.
import pandas as pd
dataframe = pd.DataFrame(
{
"Name": [
"Olivia",
"Olivia",
"Olivia",
"Olivia",
"Meghan",
"Meghan",
"Meghan",
"Meghan",
],
"Date": [
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
],
"Science Marks": [10, 2, 4, 6, 8, 9, 1, 10],
}
)
pivotTable = pd.pivot_table(dataframe, index="Name", columns="Date")
print(pivotTable)
Producción:
Science Marks
Date 03-06-2019 04-06-2019
Name
Meghan 4.5 9.5
Olivia 7.0 4.0
Aquí, hemos elegido la columna Name como el índice y la Date como la columna. La función ha generado el resultado basado en los parámetros por defecto. La función agregada por defecto mean() ha calculado la media de los valores.
Códigos de ejemplo: pandas.pivot_table() para especificar la función de agregación múltiple
import pandas as pd
dataframe = pd.DataFrame(
{
"Name": [
"Olivia",
"Olivia",
"Olivia",
"Olivia",
"Meghan",
"Meghan",
"Meghan",
"Meghan",
],
"Date": [
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
],
"Science Marks": [10, 2, 4, 6, 8, 9, 1, 10],
}
)
pivotTable = pd.pivot_table(
dataframe, index="Name", columns="Date", aggfunc=["sum", "count"]
)
print(pivotTable)
Producción:
sum count
Science Marks Science Marks
Date 03-06-2019 04-06-2019 03-06-2019 04-06-2019
Name
Meghan 9 19 2 2
Olivia 14 8 2 2
Hemos utilizado dos funciones agregadas. Las columnas de estas funciones se generan por separado.
Códigos de ejemplo: pandas.pivot_table() para usar el parámetro margins
import pandas as pd
dataframe = pd.DataFrame(
{
"Name": [
"Olivia",
"Olivia",
"Olivia",
"Olivia",
"Meghan",
"Meghan",
"Meghan",
"Meghan",
],
"Date": [
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
],
"Science Marks": [10, 2, 4, 6, 8, 9, 1, 10],
}
)
pivotTable = pd.pivot_table(
dataframe, index="Name", columns="Date", aggfunc=["sum", "count"], margins=True
)
print(pivotTable)
Producción:
sum count
Science Marks Science Marks
Date 03-06-2019 04-06-2019 All 03-06-2019 04-06-2019 All
Name
Meghan 9 19 28 2 2 4
Olivia 14 8 22 2 2 4
All 23 27 50 4 4 8
El parámetro margins ha generado una nueva fila llamada All y una nueva columna llamada también como All que muestran la suma de la fila y la columna respectivamente.