Python Pandas pandas.pivot_table() Fonction
-
Syntaxe de
pandas.pivot_table() -
Exemples de codes :
pandas.pivot_table() -
Exemple de codes :
pandas.pivot_table()pour spécifier une fonction agrégée multiple -
Exemple de codes :
pandas.pivot_table()pour utiliser le paramètremargins
La fonction Python Pandas pandas.pivot_table() évite la répétition des données de la DataFrame. Elle résume les données et applique différentes fonctions d’agrégation sur les données.
Syntaxe de pandas.pivot_table()
pandas.pivot_table(
data,
values=None,
index=None,
columns=None,
aggfunc="mean",
fill_value=None,
margins=False,
dropna=True,
margins_name="All",
observed=False,
)
Paramètres
Cette fonction a plusieurs paramètres. Les valeurs par défaut de tous les paramètres sont mentionnées ci-dessus.
data |
Il s’agit de la DataFrame dont nous voulons supprimer les données répétées. |
values |
Il représente la colonne à agréger. |
index |
C’est une colonne, un grouper, un tableau ou une liste. Elle représente la colonne de données que nous voulons comme index, c’est-à-dire comme lignes. |
columns |
C’est une colonne, un grouper, un tableau ou une liste. Il représente la colonne de données que nous voulons comme colonnes dans notre tableau croisé dynamique de sortie. |
aggfunc |
C’est une fonction, une liste de fonctions, ou un dictionnaire. Il représente la fonction agrégée qui sera appliquée aux données. Si une liste de fonctions agrégées est passée, il y aura une colonne pour chaque fonction agrégée dans le tableau résultant avec le nom de la colonne en haut. |
fill_value |
C’est un scalaire. Il représente la valeur qui remplacera les valeurs manquantes dans le tableau de sortie |
margins |
Il s’agit d’une valeur booléenne. Elle représente la ligne et la colonne générées après avoir pris la somme de la ligne et de la colonne respectives. |
dropna |
Il s’agit d’une valeur booléenne. Elle élimine les colonnes dont les valeurs sont NaN de la table de sortie. |
margins_name |
Il s’agit d’une chaîne de caractères. Elle représente le nom de la ligne et de la colonne générées si la valeur des margins est True. |
observed |
Il s’agit d’une valeur booléenne. Si un mérou est catégorique, alors ce paramètre s’applique. S’il est True, il indique les valeurs observées pour les groupeurs catégoriels. S’il est False, il indique toutes les valeurs pour les groupes catégoriels |
Renvoie
Il retourne le DataFrame résumé.
Exemples de codes : pandas.pivot_table()
Creusons un peu plus cette fonction en l’implémentant.
import pandas as pd
dataframe = pd.DataFrame({
"Name":
["Olivia",
"Olivia",
"Olivia",
"Olivia",
"Meghan",
"Meghan",
"Meghan",
"Meghan"],
"Date":
["03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019"],
"Science Marks":
[10,
2,
4,
6,
8,
9,
1,
10]
})
print(dataframe)
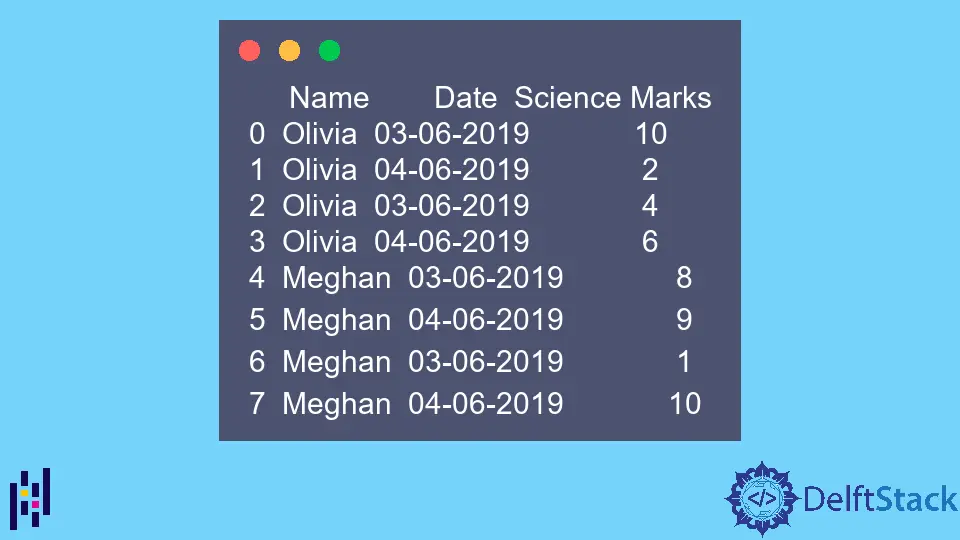
L’exemple DataFrame est,
Name Date Science Marks
0 Olivia 03-06-2019 10
1 Olivia 04-06-2019 2
2 Olivia 03-06-2019 4
3 Olivia 04-06-2019 6
4 Meghan 03-06-2019 8
5 Meghan 04-06-2019 9
6 Meghan 03-06-2019 1
7 Meghan 04-06-2019 10
Notez que les données ci-dessus contiennent plusieurs fois la même valeur dans une colonne. Cette fonction pivot_table résumera ces données.
import pandas as pd
dataframe = pd.DataFrame(
{
"Name": [
"Olivia",
"Olivia",
"Olivia",
"Olivia",
"Meghan",
"Meghan",
"Meghan",
"Meghan",
],
"Date": [
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
],
"Science Marks": [10, 2, 4, 6, 8, 9, 1, 10],
}
)
pivotTable = pd.pivot_table(dataframe, index="Name", columns="Date")
print(pivotTable)
Production:
Science Marks
Date 03-06-2019 04-06-2019
Name
Meghan 4.5 9.5
Olivia 7.0 4.0
Ici, nous avons choisi la colonne Name comme index et la colonne Date comme colonne. La fonction a généré le résultat en se basant sur les paramètres par défaut. La fonction agrégée par défaut mean() a calculé la moyenne des valeurs.
Exemple de codes : pandas.pivot_table() pour spécifier une fonction agrégée multiple
import pandas as pd
dataframe = pd.DataFrame(
{
"Name": [
"Olivia",
"Olivia",
"Olivia",
"Olivia",
"Meghan",
"Meghan",
"Meghan",
"Meghan",
],
"Date": [
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
],
"Science Marks": [10, 2, 4, 6, 8, 9, 1, 10],
}
)
pivotTable = pd.pivot_table(
dataframe, index="Name", columns="Date", aggfunc=["sum", "count"]
)
print(pivotTable)
Production:
sum count
Science Marks Science Marks
Date 03-06-2019 04-06-2019 03-06-2019 04-06-2019
Name
Meghan 9 19 2 2
Olivia 14 8 2 2
Nous avons utilisé deux fonctions agrégées. Les colonnes de ces fonctions sont générées séparément.
Exemple de codes : pandas.pivot_table() pour utiliser le paramètre margins
import pandas as pd
dataframe = pd.DataFrame(
{
"Name": [
"Olivia",
"Olivia",
"Olivia",
"Olivia",
"Meghan",
"Meghan",
"Meghan",
"Meghan",
],
"Date": [
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
],
"Science Marks": [10, 2, 4, 6, 8, 9, 1, 10],
}
)
pivotTable = pd.pivot_table(
dataframe, index="Name", columns="Date", aggfunc=["sum", "count"], margins=True
)
print(pivotTable)
Production:
sum count
Science Marks Science Marks
Date 03-06-2019 04-06-2019 All 03-06-2019 04-06-2019 All
Name
Meghan 9 19 28 2 2 4
Olivia 14 8 22 2 2 4
All 23 27 50 4 4 8
Le paramètre margins a généré une nouvelle ligne nommée All et une nouvelle colonne nommée également All qui montrent la somme de la ligne et de la colonne respectivement.