How to Decode UTF-8 in Python
-
Decoding UTF-8 in Python Using
decode() - Reading From a File With UTF-8 Encoding
-
Decoding UTF-8 in Python Using the
codecsModule - Conclusion

In the realm of software development, the handling of textual data is an indispensable aspect, often involving complex encoding standards like UTF-8.
This article delves into the intricacies of decoding UTF-8 in Python, a foundational task that can be fraught with challenges.
Python’s rich set of tools, including the built-in decode() method, error handling mechanisms during decoding, and the codecs module, offers versatile solutions for these challenges. Understanding these tools is crucial for developers as they navigate the common scenarios of reading and processing textual data from various sources such as files, networks, and APIs.
Each section of this article is crafted to enhance your proficiency in managing UTF-8 encoded data, whether you are a beginner grappling with the basics or an experienced developer seeking deeper insights into Python’s capabilities.
Decoding UTF-8 in Python Using decode()
The decode() method in Python is a built-in method used for converting bytes objects into strings. This method is essential for interpreting binary data (encoded in a specific encoding format) as human-readable text.
The decode() method is particularly useful when dealing with data that comes from external sources like files, networks, or APIs, which often use byte-oriented formats.
Example:
# Example bytes object containing UTF-8 encoded data
byte_data = b"\xe4\xb8\xad\xe6\x96\x87"
# Decoding the bytes object to a string
decoded_string = byte_data.decode("utf-8")
# Display the result
print("Decoded String:", decoded_string)
In our example, we start by defining byte_data, a bytes object that contains UTF-8 encoded text. The sequence b'\xe4\xb8\xad\xe6\x96\x87' represents a set of bytes in hexadecimal notation.
Next, we use the decode method to convert this byte data into a human-readable string. We specify the encoding parameter as 'utf-8', which instructs Python to decode the bytes using the UTF-8 encoding standard.
Finally, we print the decoded string using the print function. The print statement provides a simple and effective way to display the output for verification.
Output:

Handling Errors During UTF-8 Decoding in Python
When working with data from diverse sources, there’s always a possibility of encountering incorrectly encoded characters. Python provides robust mechanisms to deal with such scenarios during UTF-8 decoding, ensuring that your programs can handle unexpected or malformed data gracefully.
The primary goal of error handling in UTF-8 decoding is to prevent the program from crashing or yielding incorrect results when it encounters invalid byte sequences.
Syntax and Parameters
The decode() method in Python, used for converting bytes objects to strings, provides a way to handle errors. Its syntax with error handling is as follows:
string = bytes_object.decode("utf-8", errors="error_handling_strategy")
bytes_object: The bytes-like object to be decoded.errors: This parameter determines how to handle errors. Some common strategies are:'strict': Raises aUnicodeDecodeErroron failure (default behavior).'ignore': Ignores the malformed data and continues decoding the rest.'replace': Replaces the malformed data with a replacement character (like�).
Example
# Example bytes object with a potential encoding error
byte_data = b"Hello, world!\xf0\x28\x8c\x28"
# Decoding with different error handling strategies
decoded_strict = None
try:
decoded_strict = byte_data.decode("utf-8", errors="strict")
except UnicodeDecodeError:
print("Decoding failed with 'strict' error handling.")
decoded_ignore = byte_data.decode("utf-8", errors="ignore")
decoded_replace = byte_data.decode("utf-8", errors="replace")
# Display the results
print("Decoded with 'ignore':", decoded_ignore)
print("Decoded with 'replace':", decoded_replace)
In this example, byte_data contains a mixture of valid UTF-8 encoded text and an invalid byte sequence (\xf0\x28\x8c\x28). When attempting to decode it with errors='strict', a UnicodeDecodeError is raised, and we handle it in a try-except block, printing a message to indicate the failure.
We then decode the same bytes with errors='ignore' and errors='replace'. With 'ignore', the invalid sequence is simply skipped, and with 'replace', it’s replaced with the Unicode replacement character �.
Output:

Reading From a File With UTF-8 Encoding
In Python, handling files with UTF-8 encoded text is a frequent requirement, and correctly doing it is crucial for applications that process text data, such as data analysis, web development, and automation scripts.
The primary objective of reading a file with UTF-8 encoding in Python is to ensure that the text data is correctly interpreted as per its encoding standard. This is particularly important when dealing with text files created in different locales or containing characters beyond the basic ASCII set.
Syntax and Parameters
When opening a file in Python for reading, the open() function is used. To handle UTF-8 encoded files, you need to specify the encoding parameter:
file = open(file_path, mode="r", encoding="utf-8")
file_path: The path to the file you want to read.mode: The mode in which the file is opened,'r'for reading.encoding: The encoding used for decoding the file. Set this to'utf-8'for UTF-8 encoded files.
Example:
# Define the file path
file_path = "example.txt"
# Open the file with UTF-8 encoding
with open(file_path, mode="r", encoding="utf-8") as file:
# Read the content
content = file.read()
# Display the content
print(content)
In this example, replace 'example.txt' with the path to your UTF-8 encoded text file.
In our code, we begin by defining the path to the text file we want to read, example.txt. The with statement is used to open the file, which is a recommended practice as it ensures proper handling of the file (like automatic closing of the file) even if an error occurs.
The open() function is called with three arguments: file_path, mode='r' (indicating read mode), and encoding='utf-8'. This setup ensures that Python will read and decode the file content as UTF-8 encoded text.
Output:
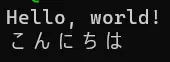
This output demonstrates the successful reading and decoding of a UTF-8 encoded file, which includes both English and Japanese characters.
Decoding UTF-8 in Python Using the codecs Module
In Python, the codecs module provides a more extensive set of tools for encoding and decoding data than the built-in functions. While the built-in str and bytes methods are sufficient for many tasks, the codecs module is particularly useful for dealing with different encoding schemes more comprehensively and handling errors in more sophisticated ways.
Syntax and Parameters
In order to decode UTF-8 using the codecs module, the codecs.decode() function is used. The syntax is:
import codecs
decoded_string = codecs.decode(byte_data, "utf-8", errors="error_handling_strategy")
byte_data: The byte sequence to decode.utf-8: The encoding format.errors: The error handling strategy (optional). Similar to thedecode()method of a bytes object, it includes options like'strict','ignore','replace', etc.
Example:
import codecs
# Example bytes object containing UTF-8 encoded text
byte_data = b"Hello, \xf0\x9f\x98\x81"
# Decoding using codecs module
decoded_string = codecs.decode(byte_data, "utf-8", errors="replace")
# Display the result
print(decoded_string)
In this code snippet, we start by importing the codecs module. We define a bytes object byte_data that contains UTF-8 encoded text, including a non-ASCII character.
We then use codecs.decode(), specifying the encoding format ('utf-8') and an error handling strategy ('replace'). This method is particularly useful when the standard decode() method of bytes doesn’t offer the control or functionality needed.
The errors='replace' argument is crucial for handling any decoding errors that occur due to malformed byte sequences. It ensures that such errors are handled gracefully by replacing problematic portions with a replacement character, maintaining the integrity of the rest of the data.
Output:
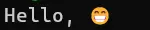
Conclusion
As we conclude this comprehensive exploration of UTF-8 decoding in Python, it becomes evident that Python’s versatility in handling textual data is one of its strongest suits. From utilizing the straightforward decode() method for basic decoding tasks to adopting sophisticated error handling strategies and leveraging the extensive functionality of the codecs module, Python equips developers with the tools needed to address a broad spectrum of challenges associated with text processing.
This article has guided you through these methods, providing insights into their applications, syntax, and practical use cases. By mastering these techniques, you enhance your ability to develop robust applications capable of handling text in various encoding formats, particularly UTF-8, with grace and efficiency.

Vaibhav is an artificial intelligence and cloud computing stan. He likes to build end-to-end full-stack web and mobile applications. Besides computer science and technology, he loves playing cricket and badminton, going on bike rides, and doodling.