How to Create Processes With Fork in C++
-
fork()System Call -
Common Methods to Create Processes Using
fork()in C++ - Automatic Children Cleanup
- Conclusion

In this article, we delve into the fundamental concepts of process creation in C++ using the fork() system call, exploring various methods and techniques to effectively manage processes and their lifecycle.
fork() System Call
fork() is a system call in Unix-like operating systems used to create a new process. It duplicates the current process, resulting in two identical processes running concurrently.
The original process is the parent, and the newly created one is the child. fork() is vital for tasks like parallel processing, where multiple tasks can be executed simultaneously.
It allows programs to create independent processes for various tasks, improving efficiency. The child inherits copies of the parent’s resources, like memory and file descriptors, but has its own address space.
Child processes typically perform different operations from the parent, facilitating multitasking and concurrent execution in Unix-based systems.
Common Methods to Create Processes Using fork() in C++
Basic fork()
Using the fork() system call in C++ is important for creating processes because it allows a parent process to spawn child processes, enabling concurrent execution of tasks. This capability is essential for building scalable and efficient applications that can perform multiple tasks simultaneously.
By leveraging fork(), developers can take advantage of the inherent parallelism of modern systems, improving performance and resource utilization. Additionally, fork() facilitates process isolation, ensuring that each process operates independently without interfering with others.
This versatility makes fork() a fundamental feature in C++ programming for tasks ranging from parallel processing to implementing server architectures and beyond.
Example Code:
#include <unistd.h>
#include <iostream>
int main() {
pid_t pid = fork();
if (pid == 0) {
// Child process
std::cout << "Child process\n";
} else if (pid > 0) {
// Parent process
std::cout << "Parent process\n";
} else {
// Error handling
std::cerr << "Fork failed\n";
return 1;
}
return 0;
}
Our code begins by including the necessary header files. We have <iostream> for standard input/output operations and <unistd.h> for the fork() system call.
Within the main() function, we declare a variable pid_t pid to store the process ID returned by fork(). This ID helps us distinguish between the parent and child processes.
Next, we call fork() and after this call, two processes run concurrently: the parent and the newly created child process. The pid variable helps us determine which process we’re currently in.
Inside the if (pid == 0) block, we have the child process’s code. Here, we print Child process to the console.
In the else if (pid > 0) block, we handle the parent process. Here, we print Parent process to the console.
If fork() fails, it returns -1, leading to the else block, where we print an error message.
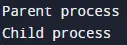
Executing this code demonstrates the basic usage of the fork() system call in C++. It showcases how a process can create a child process, enabling concurrent execution of tasks.
Understanding fork() lays the foundation for more advanced process management and multitasking techniques in C++ programming.
Multiple forks
Using multiple fork() calls in C++ allows for the creation of hierarchical process structures, enhancing the flexibility and scalability of applications. Each fork() call spawns a new child process, enabling complex workflows and parallel execution of tasks.
This approach is valuable for tasks such as parallel computing, where dividing workloads among multiple processes can significantly improve performance. Additionally, hierarchical process structures support the creation of multi-tiered server architectures, facilitating concurrent handling of client requests.
By leveraging multiple fork() calls, developers can design robust and efficient systems capable of handling diverse workloads and maximizing resource utilization in C++ applications.
Example Code:
#include <unistd.h>
#include <iostream>
int main() {
for (int i = 0; i < 3; ++i) {
pid_t pid = fork();
if (pid == 0) {
// Child process
std::cout << "Child process " << i << ", PID: " << getpid() << "\n";
return 0;
} else if (pid < 0) {
// Error handling
std::cerr << "Fork failed\n";
return 1;
}
}
// Parent process
std::cout << "Parent process, PID: " << getpid() << "\n";
return 0;
}
The provided code demonstrates the use of multiple fork() calls to create several child processes from a single parent process.
Within the main() function, we have a for loop that iterates three times.
During each iteration, a call to fork() is made. When fork() is called, it creates a new process.
If the return value of fork() is 0, it means we are in the child process. We print a message indicating the child process’s index (i) and its process ID (getpid()).
If fork() returns a positive value, it indicates that we are in the parent process. The value returned is the process ID of the newly created child process.
If fork() fails, it returns -1, indicating an error. In such cases, we print an error message to standard error (cerr) and exit the program.
After the loop completes, the parent process continues execution, printing a message indicating it is the parent process along with its process ID.
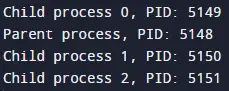
In the provided code, the parent process is initially executed, printing Parent process to the console. Subsequently, each child process is created within a loop, and as they are spawned, they print their respective messages indicating their index and process ID.
However, the order in which these messages are printed may vary depending on the scheduling behavior of the operating system. This variability arises because the operating system manages the execution of processes and determines the order in which they run based on various factors such as system load and priority levels.
Thus, while the parent process typically prints its message first, the order in which the child processes prints its messages can be unpredictable.
Executing this code demonstrates how multiple child processes can be created from a single parent process using the fork() system call in C++. Each child process runs concurrently, performing independent tasks as specified in the code.
This method enables efficient parallel execution of tasks, contributing to improved performance and scalability of applications.
Automatic Children Cleanup
Automatic children cleanup in creating processes with fork() in C++ is crucial for preventing resource leaks and maintaining system stability. When a parent process spawns child processes, automatically cleaning up terminated child processes ensures efficient resource utilization and prevents the accumulation of zombie processes.
This approach enhances the reliability and performance of applications by systematically managing the lifecycle of child processes. By implementing automatic cleanup mechanisms, developers can focus on developing robust and scalable applications without worrying about manually managing child process termination, thus simplifying the code and improving maintainability.
Example Code:
#include <sys/wait.h>
#include <unistd.h>
#include <iostream>
int num_children = 0;
void sigchld_handler(int signum) {
// Reap all terminated child processes
while (waitpid(-1, nullptr, WNOHANG) > 0) num_children--;
}
int main() {
// Set up signal handler for SIGCHLD
struct sigaction sa;
sa.sa_handler = sigchld_handler;
sigemptyset(&sa.sa_mask);
sa.sa_flags = SA_RESTART | SA_NOCLDSTOP;
if (sigaction(SIGCHLD, &sa, nullptr) == -1) {
std::cerr << "Failed to set up signal handler\n";
return 1;
}
const int num_processes = 3;
// Create child processes
for (int i = 0; i < num_processes; ++i) {
pid_t pid = fork();
if (pid == 0) {
// Child process
std::cout << "Child process " << i << ", PID: " << getpid() << "\n";
sleep(2); // Simulate child process work
return 0;
} else if (pid < 0) {
// Error handling
std::cerr << "Fork failed\n";
return 1;
} else {
// Increment the count of child processes created
num_children++;
}
}
// Parent process
while (num_children > 0) {
// Do other work in the parent process
std::cout << "Parent process, PID: " << getpid() << "\n";
sleep(1);
}
return 0;
}
The code exemplifies how to automatically manage child processes using signal handlers in C++. It comprises two main components: the setup of a signal handler to manage terminated child processes and the main function responsible for creating and managing child processes.
Firstly, the signal handler, sigchld_handler, is designed to handle the SIGCHLD signal, which informs the parent process of child process terminations. Within this handler, the waitpid() function is employed with the WNOHANG option to promptly reap terminated child processes, decrementing the num_children counter accordingly.
Secondly, in the main function, the signal handler is configured to respond to SIGCHLD signals using the sigaction() function. Subsequently, the main function initiates the creation of multiple child processes through a loop.
Each successful fork operation increments the num_children counter. In the child process block, denoted by pid == 0, the child process prints a message displaying its index and process ID (PID) before performing simulated work and returning.
Error handling for fork failures is implemented to print an error message if necessary.
Lastly, the parent process enters a loop where it executes other tasks until all child processes have been completed. During each iteration, the parent process prints its own message and checks for terminated child processes by decrementing the num_children counter.
This mechanism ensures efficient management of child processes, preventing issues such as zombie processes and resource leaks.
The output of the provided code may vary due to the concurrent execution of processes and the scheduling behavior of the operating system. However, the expected output typically follows a pattern like the one below:
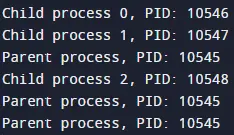
Child process 0, PID: <child_PID_1>
Child process 1, PID: <child_PID_2>
Parent process, PID: <parent_PID>
Child process 2, PID: <child_PID_3>
Parent process, PID: <parent_PID>
Parent process, PID: <parent_PID>
The code spawns multiple child processes, each printing a Child process message with its index and process ID. Once all child processes are created, the parent process intermittently prints its own message, Parent process, until all child processes finish their tasks and terminate.
The number and order of Parent process messages vary depending on the operating system’s scheduling behavior. This behavior exemplifies the concurrent execution of processes, with the parent process managing child processes while performing its own tasks, demonstrating the versatility of process management in C++ programming.
Executing this code demonstrates the effectiveness of automatic child process cleanup using signal handlers in C++. The parent process can spawn and manage multiple child processes efficiently while ensuring proper cleanup of terminated child processes.
This method enhances the reliability and performance of applications involving process management, preventing issues like zombie processes and resource leaks.
Conclusion
The article highlights the importance and versatility of the fork() system call in C++ for creating processes. It explores various methods, including basic fork(), multiple forks, and automatic children cleanup, demonstrating their significance in building robust and efficient applications.
From spawning child processes to managing their lifecycle and resource cleanup, fork() empowers developers to implement parallelism, concurrency, and process isolation effectively. Understanding and mastering these methods are fundamental for developers seeking to leverage the full potential of process management in C++ programming, enabling them to design scalable and reliable applications tailored to diverse use cases and system requirements.

Founder of DelftStack.com. Jinku has worked in the robotics and automotive industries for over 8 years. He sharpened his coding skills when he needed to do the automatic testing, data collection from remote servers and report creation from the endurance test. He is from an electrical/electronics engineering background but has expanded his interest to embedded electronics, embedded programming and front-/back-end programming.
LinkedIn Facebook