Lisser les données en Python
-
Utilisez la méthode
scipy.signal.savgol_filter()pour lisser les données en Python -
Utilisez la méthode
numpy.convolvepour lisser les données en Python -
Utilisez le
statsmodels.kernel_regressionpour lisser les données en Python

Python a une vaste application dans l’analyse et la visualisation de données. Lorsque nous analysons des ensembles de données massifs contenant de nombreuses observations, nous pouvons rencontrer des situations où nous devons lisser les courbes sur un graphique pour étudier plus attentivement le tracé final. Nous verrons comment y parvenir en Python en utilisant différentes méthodes.
Utilisez la méthode scipy.signal.savgol_filter() pour lisser les données en Python
Le filtre Savitzky-Golay est un filtre numérique qui utilise des points de données pour lisser le graphique. Il utilise la méthode des moindres carrés qui crée une petite fenêtre et applique un polynôme sur les données de cette fenêtre, puis utilise ce polynôme pour supposer le point central de la fenêtre particulière. Ensuite, la fenêtre est décalée d’un point de données et le processus est itéré jusqu’à ce que tous les voisins soient relativement ajustés les uns par rapport aux autres.
Nous pouvons utiliser la fonction scipy.signal.savgol_filter() pour implémenter cela en Python.
Voir l’exemple suivant.
import numpy as np
from scipy.signal import savgol_filter
import matplotlib.pyplot as plt
x = np.linspace(0, 2 * np.pi, 100)
y = np.sin(x) + np.random.random(100) * 0.2
yhat = savgol_filter(y, 51, 3)
plt.plot(x, y)
plt.plot(x, yhat, color="green")
plt.show()
Production:
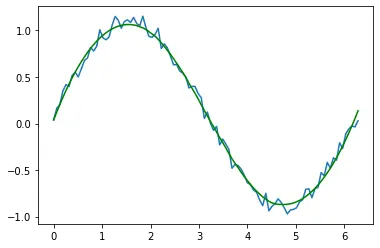
Dans l’exemple ci-dessus, nous avons utilisé la méthode de filtrage pour lisser les données à tracer sur l’axe des y. Nous avons tracé à la fois les données d’origine et les données lissées afin que vous puissiez observer la différence.
Utilisez la méthode numpy.convolve pour lisser les données en Python
Le numpy.convolve() Donne la convolution discrète et linéaire de deux séquences unidimensionnelles. Nous allons l’utiliser pour créer des moyennes mobiles qui peuvent filtrer et lisser les données.
Ceci n’est pas considéré comme une bonne méthode.
Par exemple,
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0, 2 * np.pi, 100)
y = np.sin(x) + np.random.random(100) * 0.8
def smooth(y, box_pts):
box = np.ones(box_pts) / box_pts
y_smooth = np.convolve(y, box, mode="same")
return y_smooth
plt.plot(x, y)
plt.plot(x, smooth(y, 3))
plt.plot(x, smooth(y, 19))
Production:
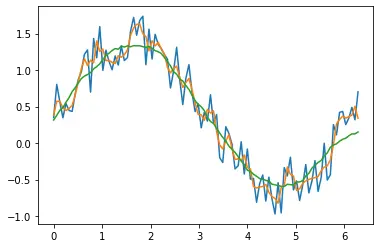
Dans l’exemple ci-dessus, nous avons tracé deux moyennes mobiles avec un delta de temps de 3 et 19. Nous avons tracé les deux dans le graphique.
Nous pouvons également utiliser d’autres méthodes pour calculer les moyennes mobiles.
Utilisez le statsmodels.kernel_regression pour lisser les données en Python
La régression du noyau calcule la moyenne conditionnelle E[y|X] où y = g(X) + e et s’intègre dans le modèle. Il peut être utilisé pour lisser les données en fonction de la variable de contrôle.
Pour ce faire, nous devons utiliser la fonction KernelReg() du module statsmodels.
Par exemple,
from statsmodels.nonparametric.kernel_regression import KernelReg
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0, 2 * np.pi, 100)
y = np.sin(x) + np.random.random(100) * 0.2
kr = KernelReg(y, x, "c")
plt.plot(x, y, "+")
y_pred, y_std = kr.fit(x)
plt.plot(x, y_pred)
plt.show()
Production:
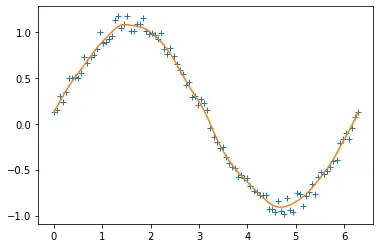
Notez que cette méthode produit un bon résultat mais est considérée comme très lente. On peut aussi utiliser la transformée de Fourier, mais elle ne fonctionne qu’avec des données périodiques.