Implementar regresión polinomial en Python
Este artículo se centrará en la regresión polinomial y cómo podemos aplicarla a datos del mundo real usando Python.
Primero, entenderemos qué es la regresión y en qué se diferencia de la regresión polinomial. Luego, veremos los casos en los que necesitamos específicamente la regresión polinomial.
Veremos varios ejemplos de programación para comprender mejor el concepto.
Definición de regresión
La regresión es un método estadístico para determinar la relación entre variables independientes o características y una variable dependiente o resultado. En el aprendizaje automático, se utiliza como un método para el modelado predictivo, en el que se emplea un algoritmo para anticipar resultados continuos.
En el aprendizaje automático supervisado, la solución de problemas de regresión es una de las aplicaciones más comunes entre los modelos de aprendizaje automático.
Entrenamos los algoritmos para encontrar la relación entre una variable dependiente y una variable independiente para predecir algunos resultados basados en algunos conjuntos de datos de entrada no vistos.
Los modelos de regresión se utilizan principalmente en modelos de análisis predictivo donde las aplicaciones necesitan pronosticar datos futuros en función de algunos datos de entrada o datos históricos. Por ejemplo, las organizaciones pueden utilizar el análisis de regresión para predecir las ventas del próximo mes en función de los datos de ventas actuales.
Las empresas médicas pueden usar modelos de regresión para pronosticar tendencias de salud en público durante un período determinado. Los usos típicos de las técnicas de regresión son:
- Pronosticar resultados continuos, como valores de propiedad, precios de acciones o ventas;
- Predecir el desempeño de futuras ventas minoristas o actividades de marketing para maximizar el uso de recursos;
- Predecir patrones de clientes o usuarios, como servicios de transmisión o sitios web de compras;
- Analizar conjuntos de datos para descubrir cómo se relacionan las variables y los resultados;
- Predecir las tasas de interés y los precios de las acciones en función de varios factores;
- Creación de visualizaciones de series temporales.
Tipos de regresión
Existen muchas técnicas de regresión, pero principalmente estas se agrupan en tres categorías principales:
- Regresión lineal simple
- Regresión logística
- Regresión lineal múltiple
Regresión lineal simple
La regresión lineal simple es un enfoque de regresión lineal en el que se traza una línea recta dentro de los puntos de datos para minimizar el error entre la línea y los puntos de datos. Es una de las formas más fundamentales y sencillas de regresión de aprendizaje automático.
En este escenario, se considera que las variables independientes y dependientes tienen una relación lineal.
Regresión logística
Cuando la variable dependiente solo puede tener dos valores, true o false, o sí o no, se utiliza la regresión logística. La posibilidad de que ocurra una variable dependiente se puede predecir utilizando modelos de regresión logística.
Los valores de salida deben, en la mayoría de los casos, ser binarios. La relación entre las variables dependientes e independientes se puede representar mediante una curva sigmoidea.
Regresión lineal múltiple
La regresión lineal múltiple se usa cuando se emplea más de una variable independiente. Las técnicas de regresión lineal múltiple incluyen la regresión polinomial.
Cuando hay muchas variables independientes, es una regresión lineal múltiple. Cuando están presentes numerosas variables independientes, logra un mejor ajuste que la regresión lineal básica.
Cuando se muestra en dos dimensiones, el resultado es una línea curva que se ajusta a los puntos de datos.
En regresión simple, usamos la siguiente fórmula para encontrar el valor de una variable dependiente usando un valor independiente:
$$
y = a+bx+c
$$
Dónde:
yes la variable dependienteaes el intercepto en ybes la pendienteces la tasa de error
En muchos casos, la regresión lineal no dará el resultado perfecto cuando hay más de una variable independiente, por lo que se necesita la regresión polinomial, que tiene la fórmula,
$$
y = a_0 + a_1x_1 + a_2x_2^2 + …..+ a_nx_n^n
$$
Como podemos ver, y es la variable dependiente de x.
El grado de este polinomio debe tener el valor óptimo ya que un grado más alto sobreajusta los datos. Con un valor de grado más bajo, el modelo se ajusta por debajo de los resultados.
Implementar regresión polinomial en Python
Python incluye funciones para determinar un vínculo entre puntos de datos y dibujar una línea de regresión polinomial. En lugar de repasar la fórmula matemática, le mostraremos cómo usar estas estrategias.
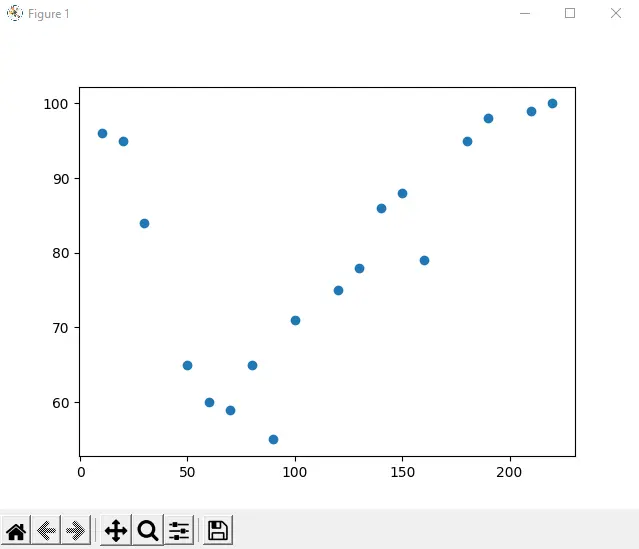
En el siguiente ejemplo, se registraron 18 automóviles al pasar por una cabina de peaje. Registramos la velocidad del automóvil y la hora del día (hora) cuando nos pasó.
Las horas del día están representadas en el eje x, y la velocidad está representada en el eje y:
import matplotlib.pyplot as plot
xAxis = [
10,
20,
30,
50,
60,
70,
80,
90,
100,
120,
130,
140,
150,
160,
180,
190,
210,
220,
]
yAxis = [96, 95, 84, 65, 60, 59, 65, 55, 71, 75, 78, 86, 88, 79, 95, 98, 99, 100]
plot.scatter(xAxis, yAxis)
plot.show()
Producción:
Ahora, dibujaremos una regresión polinomial usando NumPy y Matplotlib.
import numpy
import matplotlib.pyplot as plot
xAxis = [
10,
20,
30,
50,
60,
70,
80,
90,
100,
120,
130,
140,
150,
160,
180,
190,
210,
220,
]
yAxis = [96, 95, 84, 65, 60, 59, 65, 55, 71, 75, 78, 86, 88, 79, 95, 98, 99, 100]
model = numpy.poly1d(numpy.polyfit(xAxis, yAxis, 3))
linesp = numpy.linspace(10, 220, 100)
plot.scatter(xAxis, yAxis)
plot.plot(linesp, model(linesp))
plot.show()
Producción:
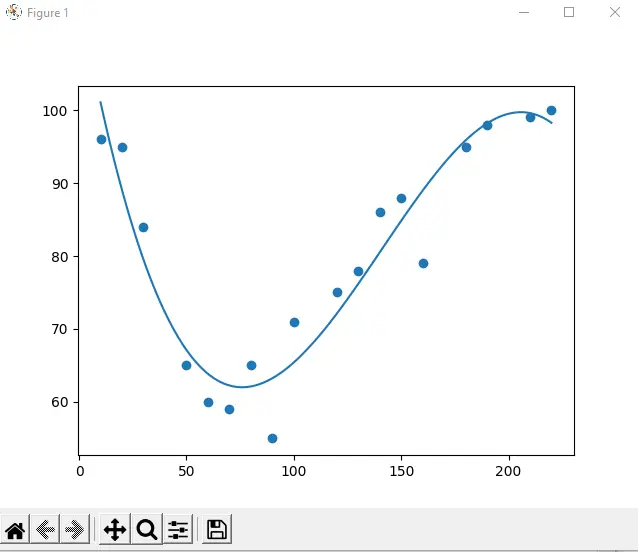
En el ejemplo anterior, usamos las bibliotecas NumPy y Matplotlib para dibujar una regresión polinomial usando las declaraciones de importación. Después de eso, creamos matrices para el eje x y el eje y como:
xAxis = [
10,
20,
30,
50,
60,
70,
80,
90,
100,
120,
130,
140,
150,
160,
180,
190,
210,
220,
]
yAxis = [96, 95, 84, 65, 60, 59, 65, 55, 71, 75, 78, 86, 88, 79, 95, 98, 99, 100]
Ahora, hemos utilizado un método de la biblioteca NumPy para hacer un modelo polinomial como:
model = numpy.poly1d(numpy.polyfit(xAxis, yAxis, 3))
Ahora especificaremos cómo mostrar la línea. En nuestro caso lo hemos arrancado de 10 a 220.
linesp = numpy.linspace(10, 220, 100)
Las últimas tres líneas de código se utilizan para dibujar el gráfico, luego la línea de regresión y luego mostrar el gráfico.
plot.scatter(xAxis, yAxis)
plot.plot(linesp, model(linesp))
plot.show()
La relación entre el eje x y el eje y
Es fundamental conocer la relación entre los ejes (x e y) porque si no hay relación entre ellos, es imposible predecir valores o resultados futuros de la regresión.
Calcularemos un valor llamado R-Squared para medir la relación. Va de 0 a 1, donde 0 representa ninguna relación y 1 representa 100% relacionado.
import numpy
import matplotlib.pyplot as plot
from sklearn.metrics import r2_score
xAxis = [
10,
20,
30,
50,
60,
70,
80,
90,
100,
120,
130,
140,
150,
160,
180,
190,
210,
220,
]
yAxis = [96, 95, 84, 65, 60, 59, 65, 55, 71, 75, 78, 86, 88, 79, 95, 98, 99, 100]
model = numpy.poly1d(numpy.polyfit(xAxis, yAxis, 3))
print(r2_score(yAxis, model(xAxis)))
Producción :
0.9047652736246418
El valor de 0.9 muestra la fuerte relación entre x e y.
Si el valor es muy bajo, muestra una relación muy débil. Además, indica que este conjunto de datos no es adecuado para la regresión polinomial.

Husnain is a professional Software Engineer and a researcher who loves to learn, build, write, and teach. Having worked various jobs in the IT industry, he especially enjoys finding ways to express complex ideas in simple ways through his content. In his free time, Husnain unwinds by thinking about tech fiction to solve problems around him.
LinkedIn