Seegeborener Graf Plot
Dieser Artikel behandelt das Zähldiagramm von Seaborn und den Unterschied zwischen dem Zähldiagramm und einem Balkendiagramm. Wir werden uns auch die verfügbaren Python-Optionen für die Funktion countplot() von Seaborn ansehen.
Verwenden Sie die Funktion countplot() in Seaborn
countplot() ist eine Möglichkeit, die Anzahl der Beobachtungen pro Kategorie zu zählen und diese Informationen dann in Balken anzuzeigen. Sie können es als Histogramm betrachten, aber für kategoriale Daten ist es ein sehr einfaches Diagramm und sehr nützlich, insbesondere bei der explorativen Datenanalyse in Python.
Sehen Sie sich die Funktion countplot() in der Seaborn-Bibliothek an. Zuerst werden wir die Seaborn-Bibliothek importieren und einige Daten über Diamanten aus der Seaborn-Bibliothek laden.
import seaborn as sb
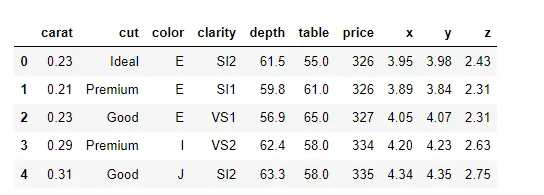
Data_DM = sb.load_dataset("diamonds")
Data_DM.head()
Jede Zeile dieses Datensatzes enthält Informationen zu einem bestimmten Diamanten.
Wir werden es mit clarity.isin auf SI1 und VS2 eingrenzen, sodass wir eine Kategorie mit nur zwei Optionen haben.
Data_DM = Data_DM[Data_DM.clarity.isin(["SI1", "VS2"])]
Data_DM.shape
Wenn wir alles eingrenzen, haben wir ungefähr 25323 verschiedene Diamanten in diesem Datensatz.
(25323, 10)
Jetzt können wir unser erstes Zähldiagramm erstellen. Dazu referenzieren wir die Seaborn-Bibliothek, rufen die Funktion countplot() auf und übergeben, welche Spalte wir plotten möchten.
Wir zeichnen die Spalte Farbe, und diese Daten stammen aus unserem Datenrahmen Data_DM.
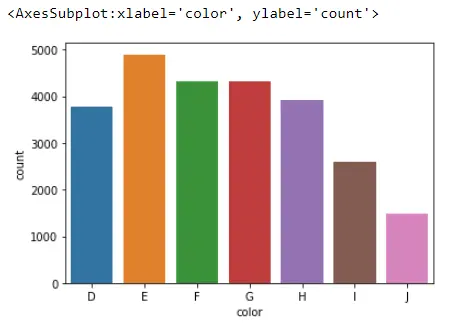
sb.countplot(x="color", data=Data_DM)
Was dies mit diesem Diagramm macht, ist die Anzahl der Beobachtungen zu zählen, die wir für jede Kategorie haben, die es in der Spalte Farbe findet. Zum Beispiel hat Seaborn etwa 1500 Diamanten mit einer Farbe gleich J gefunden.
Wenn wir value_counts() auf die Spalte color anwenden:
Data_DM.color.value_counts(sort=False)
Diese Zahlen zeichnen wir, wenn wir die Funktion countplot() verwenden.
D 3780
E 4896
F 4332
G 4323
H 3918
I 2593
J 1481
Name: color, dtype: int64
Eine nette Sache am Seaborn countplot() ist, dass wir einfach von vertikalen zu horizontalen Balken wechseln können. Alles, was wir tun müssen, ist dieses x in ein y umzuwandeln.
sb.countplot(y="color", data=Data_DM)
Ausgang:
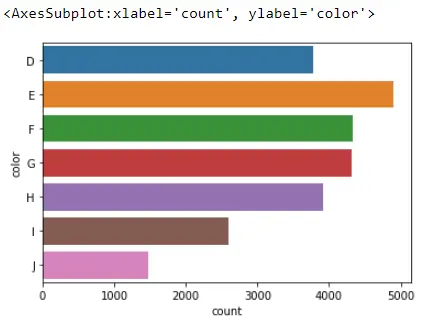
Seaborn Barplot vs. Countplot
An dieser Stelle könnten Sie also denken, dass der countplot von Seaborn dem barplot sehr ähnlich sieht. Aber es gibt einen wirklich großen Unterschied: Beim Seaborn-Countplot zählen wir nur die Anzahl der Beobachtungen pro Kategorie.
Mit dem barplot von Seaborn erhalten wir eine Schätzung für einige zusammenfassende Statistiken pro Kategorie. Zum Beispiel könnten wir den Durchschnitt pro Kategorie haben und daraus die Konfidenzintervalle erhalten; Deshalb wird ein Balkendiagramm verwendet.
Das Ordnungsargument
Sie werden für zwei verschiedene Dinge verwendet; Die Codierungsoptionen sind jedoch in beiden Diagrammen verfügbar. Schauen wir uns einige dieser Optionen im Seaborn-Code an.
Lassen Sie uns für die erste Option über die Reihenfolge in den Balken sprechen, die im obigen Diagramm erscheinen. Wenn wir uns unseren countplot für die Farbe dieser Diamanten ansehen, werden wir sehen, dass die Balken derzeit nicht nach den beliebtesten bis zu den unbeliebtesten sortiert sind.
Sie sind alphabetisch von D bis J aufgereiht.
sb.countplot(x="cut", data=Data_DM)
Aber wenn wir uns eine andere Spalte namens Schnitt ansehen, sehen wir, dass die Balken nicht mehr alphabetisch angeordnet sind.
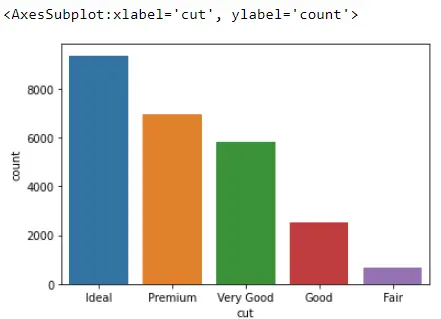
Es ist zunächst nicht klar, wie Seaborn diese Bars arrangiert; wir können durch den Prozess gehen. Wir sehen uns die Datentypen der diamonds-Spalten an und stellen fest, dass wir mehrere Float64-, Int64- und Kategorien haben.
Data_DM.dtypes
Diese drei Spalten werden als Kategoriedatentypen betrachtet. Schnitt, Farbe und Klarheit sind alle Kategorien.
carat float64
cut category
color category
clarity category
depth float64
table float64
price int64
x float64
y float64
z float64
dtype: object
Mal sehen, was es bedeutet. Um die Farbe zu überprüfen, haben wir diese Eigenschaft namens Kategorien.
Data_DM.color.cat.categories
Dies ist, was Seaborn verwendet, um diese Balken auszurichten.
Index(['D', 'E', 'F', 'G', 'H', 'I', 'J'], dtype='object')
Typischerweise werden Kategorie-Spalten mit dieser Eigenschaft namens Kategorien geliefert, und Seaborn wird diese verwenden, um herauszufinden, wie diese Balken ausgerichtet werden sollen.
Data_DM.cut.cat.categories
Ausgang:
Index(['Ideal', 'Premium', 'Very Good', 'Good', 'Fair'], dtype='object')
In der ersten reihen wir uns alphabetisch auf, aber in der zweiten reihen wir uns zuerst nach den besten Diamanten und dann nach unten zu den schlechtesten Diamanten.
Aber was ist, wenn die Reihenfolge dieser Kategorie nicht so ist, wie wir diese Balken haben möchten? Die Seaborn-Funktion countplot() hat ein Argument namens order, und wir können eine Liste übergeben, wie wir diese Balken anordnen möchten.
ord_of_c = ["J", "I", "H", "G", "F", "E", "D"]
sb.countplot(x="color", data=Data_DM, order=ord_of_c)
Ausgang:
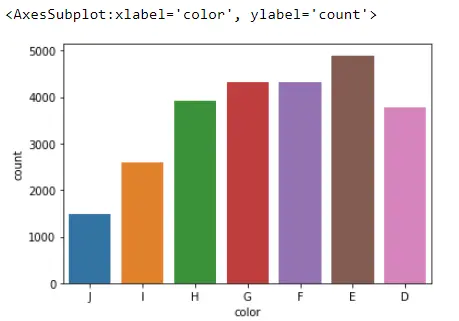
Wir können diese Balken auch in aufsteigender oder absteigender Reihenfolge sortieren, da dies ein Pandas-Datenrahmen ist, daher empfehlen wir die Verwendung der Methode value_counts(). Dadurch werden unsere Bars von den beliebtesten bis zu den unbeliebtesten sortiert.
Wenn wir uns den Index schnappen, sehen wir, dass die beliebteste Kategorie E ist und bis zur am wenigsten beliebten Kategorie J.
Data_DM.color.value_counts().index
Ausgang:
CategoricalIndex(['E', 'F', 'G', 'H', 'D', 'I', 'J'], categories=['D', 'E', 'F', 'G', 'H', 'I', 'J'], ordered=False, dtype='category')
Wir können diesen index verwenden, wenn wir unsere Bestellung für unsere Riegel erstellen. Jetzt haben wir diese absteigend sortiert.
Aber wenn wir es vorziehen, sie aufsteigend sortiert zu haben.
Alles, was wir tun müssen, ist diesen Index umzukehren, was wir mit zwei Doppelpunkten und einem negativen tun können, der den Index vollständig umkehrt.
sb.countplot(x="color", data=Data_DM, order=Data_DM.color.value_counts().index[::-1])
Ausgang:
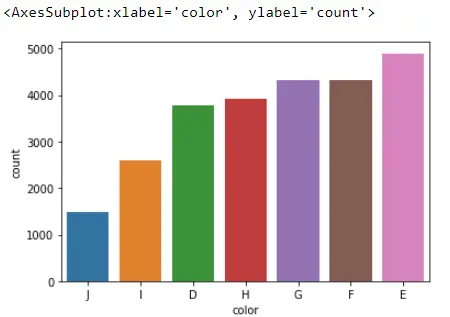
Weitere Optionen finden Sie, wenn Sie hier besuchen.
Vollständiger Code:
# In[1]:
import seaborn as sb
Data_DM = sb.load_dataset("diamonds")
Data_DM.head()
# In[2]:
Data_DM = Data_DM[Data_DM.clarity.isin(["SI1", "VS2"])]
Data_DM.shape
# In[3]:
sb.countplot(x="color", data=Data_DM)
# In[4]:
Data_DM.color.value_counts(sort=False)
# In[5]:
sb.countplot(y="color", data=Data_DM)
# In[6]: order argument
sb.countplot(x="cut", data=Data_DM)
# In[7]:
Data_DM.dtypes
# In[8]:
Data_DM.color.cat.categories
# In[9]:
Data_DM.cut.cat.categories
# In[10]:
ord_of_c = ["J", "I", "H", "G", "F", "E", "D"]
sb.countplot(x="color", data=Data_DM, order=ord_of_c)
# In[11]:
Data_DM.color.value_counts().index
# In[12]:
sb.countplot(x="color", data=Data_DM, order=Data_DM.color.value_counts().index[::-1])

Hello! I am Salman Bin Mehmood(Baum), a software developer and I help organizations, address complex problems. My expertise lies within back-end, data science and machine learning. I am a lifelong learner, currently working on metaverse, and enrolled in a course building an AI application with python. I love solving problems and developing bug-free software for people. I write content related to python and hot Technologies.
LinkedIn