시본 카운트 플롯
이 기사에서는 Seaborn 카운트 플롯과 카운트 플롯과 막대 플롯의 차이점에 대해 설명합니다. Seaborn의 countplot() 기능에 사용 가능한 Python 옵션도 살펴봅니다.
Seaborn에서 countplot() 기능 사용
countplot()은 범주당 관찰 수를 세고 해당 정보를 막대로 표시하는 방법입니다. 히스토그램으로 생각할 수 있지만 범주형 데이터의 경우 매우 간단한 플롯이며 특히 Python에서 탐색적 데이터 분석을 수행할 때 매우 유용합니다.
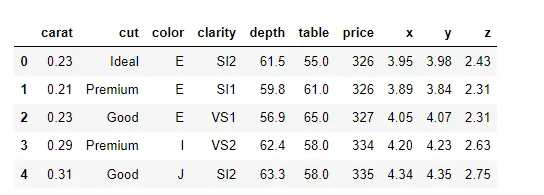
Seaborn 라이브러리에서 countplot() 기능을 확인하십시오. 먼저 Seaborn 라이브러리를 가져오고 Seaborn 라이브러리에서 다이아몬드에 대한 일부 데이터를 로드합니다.
import seaborn as sb
Data_DM = sb.load_dataset("diamonds")
Data_DM.head()
이 데이터 세트의 각 행에는 하나의 특정 다이아몬드에 대한 정보가 포함되어 있습니다.
clarity.isin을 사용하여 SI1 및 VS2로 범위를 좁히므로 두 가지 옵션만 있는 범주가 있습니다.
Data_DM = Data_DM[Data_DM.clarity.isin(["SI1", "VS2"])]
Data_DM.shape
모든 범위를 좁히면 이 데이터 세트에 약 25323개의 서로 다른 다이아몬드가 있습니다.
(25323, 10)
이제 첫 번째 카운트 플롯을 만들 준비가 되었습니다. 이를 위해 Seaborn 라이브러리를 참조하고 countplot() 함수를 호출하고 플롯하려는 열을 전달합니다.
우리는 색상 열을 플로팅할 것이며 이러한 데이터는 Data_DM 데이터 프레임에서 가져옵니다.
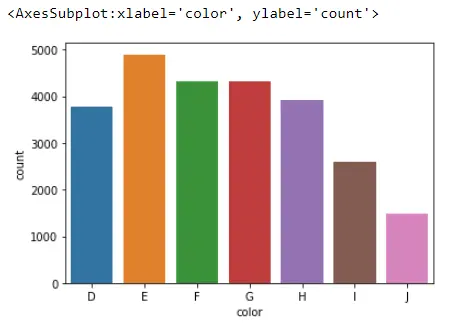
sb.countplot(x="color", data=Data_DM)
이것이 이 플롯에서 수행하는 작업은 색상 열에서 찾은 각 범주에 대한 관측값 수를 계산하는 것입니다. 예를 들어, Seaborn은 J와 같은 색상을 가진 약 1500개의 다이아몬드를 발견했습니다.
value_counts()를 color 열에 적용한 경우:
Data_DM.color.value_counts(sort=False)
이 숫자는 countplot() 함수를 사용할 때 플롯하는 것입니다.
D 3780
E 4896
F 4332
G 4323
H 3918
I 2593
J 1481
Name: color, dtype: int64
Seaborn countplot()의 한 가지 좋은 점은 세로 막대에서 가로 막대로 쉽게 전환할 수 있다는 것입니다. 우리가 해야 할 일은 이 x를 y로 바꾸는 것입니다.
sb.countplot(y="color", data=Data_DM)
출력:
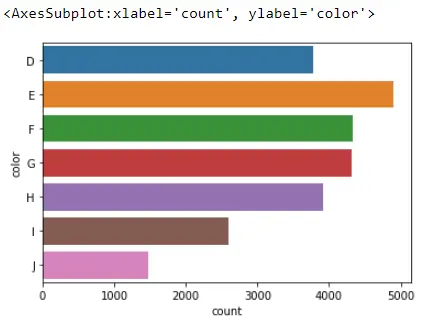
Seaborn Barplot 대 Countplot
따라서 이 시점에서 Seaborn countplot이 barplot과 매우 유사하다고 생각할 수 있습니다. 그러나 한 가지 정말 큰 차이점이 있습니다. Seaborn 카운트플롯을 사용하면 범주당 관찰 수를 세는 것입니다.
Seaborn barplot을 사용하여 범주별 요약 통계에 대한 추정치를 얻습니다. 예를 들어 범주별 평균을 갖고 여기에서 신뢰 구간을 얻을 수 있습니다. 이것이 막대 그래프가 사용되는 이유입니다.
주문 인수
그들은 두 가지 다른 용도로 사용됩니다. 그러나 코딩 옵션은 두 플롯 모두에서 사용할 수 있습니다. Seaborn 코드에서 이러한 옵션 중 일부를 확인해 봅시다.
첫 번째 옵션의 경우 위 그림에 나타나는 막대의 순서에 대해 이야기해 보겠습니다. 해당 다이아몬드의 색상에 대한 카운트플롯을 보면 막대가 현재 가장 인기 있는 것부터 가장 인기 없는 것 순으로 정렬되어 있지 않음을 알 수 있습니다.
D에서 J까지 알파벳순으로 정렬됩니다.
sb.countplot(x="cut", data=Data_DM)
그러나 잘라내기라는 다른 열을 보면 막대가 더 이상 알파벳순으로 정렬되지 않음을 알 수 있습니다.
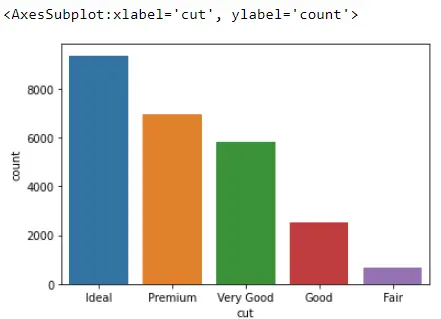
처음에는 Seaborn이 이러한 막대를 어떻게 배열하고 있는지 명확하지 않습니다. 우리는 그 과정을 살펴볼 수 있습니다. 다이아몬드 열의 데이터 유형을 살펴보고 여러 float64, int64 및 범주가 있음을 확인합니다.
Data_DM.dtypes
이 세 열은 범주 데이터 유형으로 간주됩니다. cut, color 및 clarity는 모두 범주입니다.
carat float64
cut category
color category
clarity category
depth float64
table float64
price int64
x float64
y float64
z float64
dtype: object
그것이 무엇을 의미하는지 봅시다. 색상을 확인하기 위해 카테고리라는 속성이 있습니다.
Data_DM.color.cat.categories
이것은 Seaborn이 해당 막대를 정렬하는 데 사용하는 것입니다.
Index(['D', 'E', 'F', 'G', 'H', 'I', 'J'], dtype='object')
일반적으로 카테고리 열은 카테고리라는 속성과 함께 제공되며 Seaborn은 이를 사용하여 해당 막대를 정렬하는 방법을 파악합니다.
Data_DM.cut.cat.categories
출력:
Index(['Ideal', 'Premium', 'Very Good', 'Good', 'Fair'], dtype='object')
첫 번째는 알파벳순으로 정렬하지만 두 번째는 최고의 다이아몬드를 기준으로 먼저 정렬하고 최악의 다이아몬드까지 정렬합니다.
그러나 해당 카테고리의 순서가 해당 막대가 표시되는 방식이 아닌 경우에는 어떻게 해야 합니까? Seaborn countplot() 함수에는 order라는 인수가 있으며 해당 막대를 주문하는 방법 목록을 전달할 수 있습니다.
ord_of_c = ["J", "I", "H", "G", "F", "E", "D"]
sb.countplot(x="color", data=Data_DM, order=ord_of_c)
출력:
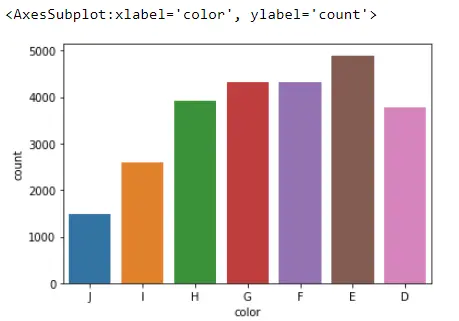
이 막대는 Pandas 데이터 프레임이므로 오름차순 또는 내림차순으로 정렬할 수도 있으므로 value_counts() 메서드를 사용하는 것이 좋습니다. 이렇게 하면 가장 인기 있는 바부터 가장 인기 없는 바 순으로 바가 정렬됩니다.
계속해서 인덱스를 가져오면 가장 인기 있는 범주가 E이고 가장 인기 없는 범주인 J가 표시됩니다.
Data_DM.color.value_counts().index
출력:
CategoricalIndex(['E', 'F', 'G', 'H', 'D', 'I', 'J'], categories=['D', 'E', 'F', 'G', 'H', 'I', 'J'], ordered=False, dtype='category')
막대에 대한 주문을 생성할 때 이 인덱스를 사용할 수 있습니다. 이제 내림차순으로 정렬했습니다.
그러나 오름차순 정렬을 선호한다면.
우리가 해야 할 일은 두 개의 콜론과 인덱스를 완전히 전환할 음수 하나로 할 수 있는 이 인덱스를 뒤집는 것입니다.
sb.countplot(x="color", data=Data_DM, order=Data_DM.color.value_counts().index[::-1])
출력:
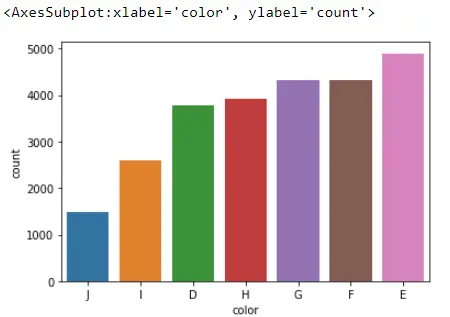
여기를 방문하면 더 많은 옵션을 찾을 수 있습니다.
전체 코드:
# In[1]:
import seaborn as sb
Data_DM = sb.load_dataset("diamonds")
Data_DM.head()
# In[2]:
Data_DM = Data_DM[Data_DM.clarity.isin(["SI1", "VS2"])]
Data_DM.shape
# In[3]:
sb.countplot(x="color", data=Data_DM)
# In[4]:
Data_DM.color.value_counts(sort=False)
# In[5]:
sb.countplot(y="color", data=Data_DM)
# In[6]: order argument
sb.countplot(x="cut", data=Data_DM)
# In[7]:
Data_DM.dtypes
# In[8]:
Data_DM.color.cat.categories
# In[9]:
Data_DM.cut.cat.categories
# In[10]:
ord_of_c = ["J", "I", "H", "G", "F", "E", "D"]
sb.countplot(x="color", data=Data_DM, order=ord_of_c)
# In[11]:
Data_DM.color.value_counts().index
# In[12]:
sb.countplot(x="color", data=Data_DM, order=Data_DM.color.value_counts().index[::-1])

Hello! I am Salman Bin Mehmood(Baum), a software developer and I help organizations, address complex problems. My expertise lies within back-end, data science and machine learning. I am a lifelong learner, currently working on metaverse, and enrolled in a course building an AI application with python. I love solving problems and developing bug-free software for people. I write content related to python and hot Technologies.
LinkedIn