Erstellen Sie eine ClusterMap in Seaborn
-
Erstellen Sie eine Clustermap mit der
clustermap()-Methode in Seaborn -
Fügen Sie die Optionen
row_colorsundcol_colorsin der Seaborn Clustermap hinzu

In dieser Demonstration lernen wir, was eine Clusterkarte ist und wie wir sie für mehrere Optionen erstellen und verwenden können.
Erstellen Sie eine Clustermap mit der clustermap()-Methode in Seaborn
Die Seaborn-Clusterkarte ist ein Matrixplot, in dem Sie Ihre Matrixentitäten durch eine Heatmap visualisieren können, aber wir erhalten auch eine Clusterung Ihrer Zeilen und Spalten.
Lassen Sie uns einige erforderliche Bibliotheken importieren.
Code:
import seaborn as sb
import matplotlib.pyplot as plot
import numpy as np
import pandas as pd
Jetzt werden wir einige Daten über vier hypothetische Studenten erstellen. Wir werden ihre Namen, Lernstunden, Testergebnisse und Straßenadressen haben.
Code:
TOY_DATA_DICT = {
"Name": ["Andrew", "Victor", "John", "Sarah"],
"study_hours": [11, 25, 22, 14],
"Score": [11, 30, 28, 19],
"Street_Address": [20, 30, 21, 12],
}
Diese Spielzeugdaten befinden sich also in einem Wörterbuch, aber wir konvertieren dies in einen Pandas-Datenrahmen und setzen den Index auf den Namen des Schülers.
Code:
TOY_DATA = pd.DataFrame(TOY_DATA_DICT)
TOY_DATA.set_index("Name", inplace=True)
TOY_DATA
Wir haben also vier hypothetische Studenten und drei verschiedene Datenspalten. Wie wir hier feststellen können, haben wir diesen Datensatz absichtlich so gestaltet, dass unsere Studienstunden und Punktzahl für jeden Schüler ziemlich ähnlich sind.
Ausgang:
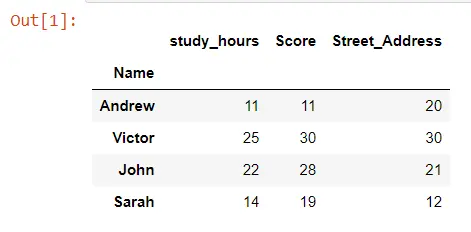
Lassen Sie uns mit der Methode clustermap() eine Clusterkarte für diesen Datenrahmen erstellen. Wir müssen nur den gesamten Datenrahmen namens TOY_DATA übergeben.
Wir verwenden ein weiteres Schlüsselwortargument, annot, und setzen es auf True. Dieses Argument ermöglicht es uns, die tatsächlichen Zahlen zu sehen, die auf dem Heatmap-Teil der Clusterkarte ausgedruckt sind.
Code:
import seaborn as sb
import matplotlib.pyplot as plot
import numpy as np
import pandas as pd
TOY_DATA_DICT = {
"Name": ["Andrew", "Victor", "John", "Sarah"],
"study_hours": [11, 25, 22, 14],
"Score": [11, 30, 28, 19],
"Street_Address": [20, 30, 21, 12],
}
TOY_DATA = pd.DataFrame(TOY_DATA_DICT)
TOY_DATA.set_index("Name", inplace=True)
TOY_DATA
sb.clustermap(TOY_DATA, figsize=(6, 4), annot=True)
plot.show()
Wir haben niedrigere Werte, die dunklere Farben erhalten, und höhere Werte, die hellere Farben erhalten, und wir können auch feststellen, dass wir links und oben auf dieser Heatmap Linien haben. Diese Linien werden Dendrogramme genannt, und so hat Seaborn unsere Daten gruppiert.
Wir können sehen, dass unsere Studienstunden und Ergebnis zusammen gruppiert wurden, was uns den Abstand von den Lernstunden zum Ergebnis anzeigt. Und da ihr Abstand am kleinsten ist, werden sie zuerst im Dendrogramm zusammengefasst, und dann fügen wir street_address hinzu, was diesen beiden anderen Spalten weniger ähnlich ist.
Wir können sagen, dass dieses Dendrogramm uns ein Gefühl dafür gibt, wie weit jede dieser verschiedenen Spalten voneinander entfernt ist, und dasselbe passiert in den Zeilen. Sie werden auch feststellen, dass Seaborn unsere Zeilen und Spalten neu geordnet hat.
Ausgang:
Sehen wir uns die Clusterkarte auf einem erweiterten Datensatz an. Wir laden einige Daten aus der Seaborn-Bibliothek, und diese Daten beziehen sich auf Pinguine.
Code:
PENGUINS = sb.load_dataset("penguins").dropna()
PENGUINS.head()
Ausgang:
Wir haben ungefähr 300 verschiedene Pinguine in diesem Datensatz, und wir können die Form der Daten anhand des Attributs Form erkennen.
Code:
print(PENGUINS.shape)
Ausgang:
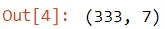
Lassen Sie uns eine Clusterkarte für diese Daten erstellen. Die Daten, die wir an eine dieser Clusterkarten übergeben, sollten numerisch sein, daher müssen wir sie nur auf die numerischen Spalten dieses Datenrahmens herunterfiltern.

Lassen Sie uns eine erweiterte Clusterkarte erstellen.
import seaborn as sb
import matplotlib.pyplot as plot
import numpy as np
import pandas as pd
PENGUINS = sb.load_dataset("penguins").dropna()
PENGUINS.head()
print(PENGUINS.shape)
NUMERICAL_COLS = PENGUINS.columns[2:6]
print(NUMERICAL_COLS)
sb.clustermap(PENGUINS[NUMERICAL_COLS], figsize=(6, 6))
plot.show()
Wenn wir diesen Code ausführen, sehen wir sofort, dass wir drei Spalten mit sehr dunklen Werten und nur eine Spalte mit sehr hellen Werten haben. Das liegt daran, dass wir für diese verschiedenen Spalten unterschiedliche Skalen haben.
Ausgang:
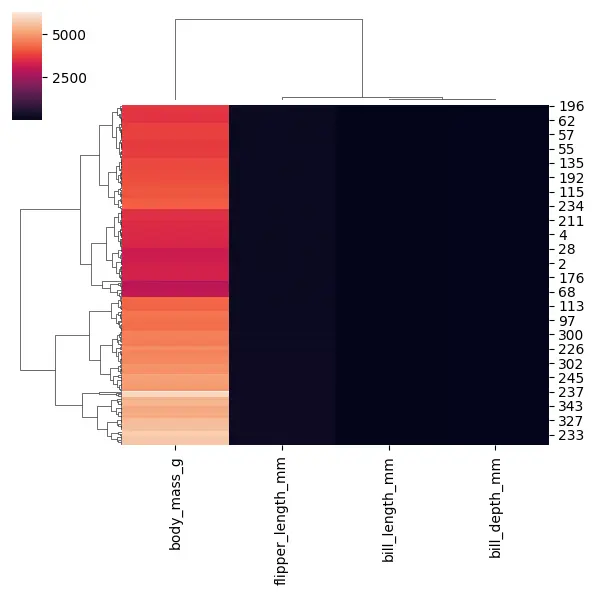
Drei Spalten haben kleinere Werte und eine Spalte, body_mass_g, hat sehr große Werte. Dies kann jedoch zu einer Art wenig hilfreicher Heatmap führen, daher müssen wir unsere Daten skalieren.
Es gibt einige Möglichkeiten, unsere Daten innerhalb der Clusterkarte zu skalieren, aber eine einfache Möglichkeit ist die Verwendung dieses Arguments namens standard_scale. Der Wert für dieses Argument ist entweder 0, wenn wir jede Zeile skalieren wollen, oder 1, wenn wir jede Spalte skalieren wollen.
Code:
import seaborn as sb
import matplotlib.pyplot as plot
import numpy as np
import pandas as pd
PENGUINS = sb.load_dataset("penguins").dropna()
PENGUINS.head()
print(PENGUINS.shape)
NUMERICAL_COLS = PENGUINS.columns[2:6]
print(NUMERICAL_COLS)
sb.clustermap(PENGUINS[NUMERICAL_COLS], figsize=(6, 6), standard_scale=1)
plot.show()
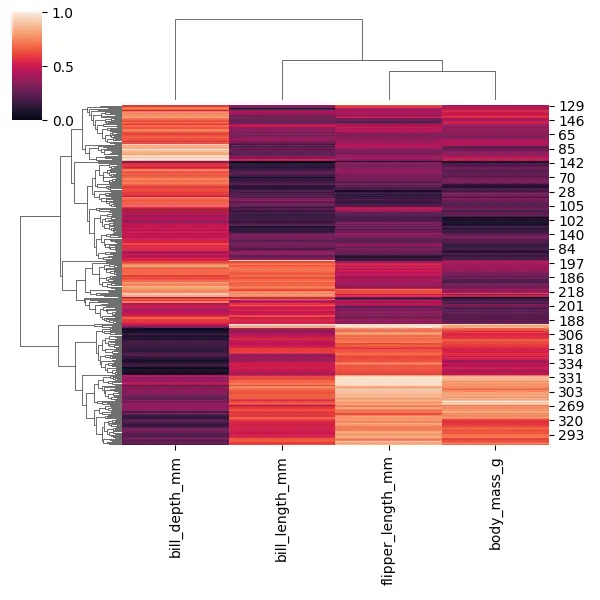
Jetzt werden alle Werte zwischen 0 und 1 angezeigt. Es hilft uns, jede dieser Spalten auf der gleichen Skala zu platzieren, um sie einfacher vergleichen zu können.
Wir können auch sehen, dass all die verschiedenen Pinguine gruppiert wurden, was uns helfen könnte, herauszufinden, welche Pinguine einander am ähnlichsten sind.
Ausgang:
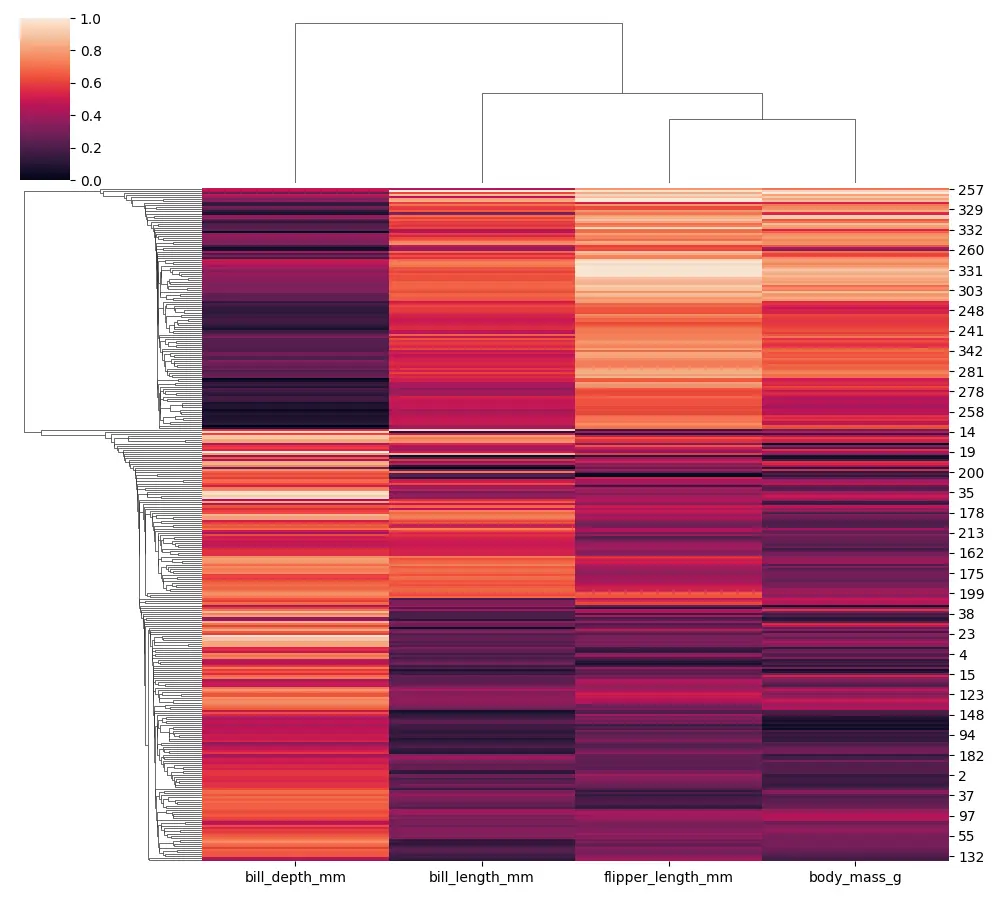
In der Seaborn-Clusterkarte können wir sowohl die Verknüpfung als auch die Matrix ändern, die zur Beurteilung der Entfernungen verwendet werden. Versuchen wir also, die Verknüpfung mit dem Argument Methode zu ändern. Wir können den String als Wert namens single übergeben, was eine minimale Verknüpfung ist.
Code:
import seaborn as sb
import matplotlib.pyplot as plot
import numpy as np
import pandas as pd
PENGUINS = sb.load_dataset("penguins").dropna()
PENGUINS.head()
print(PENGUINS.shape)
NUMERICAL_COLS = PENGUINS.columns[2:6]
print(NUMERICAL_COLS)
sb.clustermap(
PENGUINS[NUMERICAL_COLS], figsize=(10, 9), standard_scale=1, method="single"
)
plot.show()
Sie werden feststellen, dass sich unser Dendrogramm leicht unterscheidet, wenn wir eine einzelne Verknüpfung verwenden.
Ausgang:
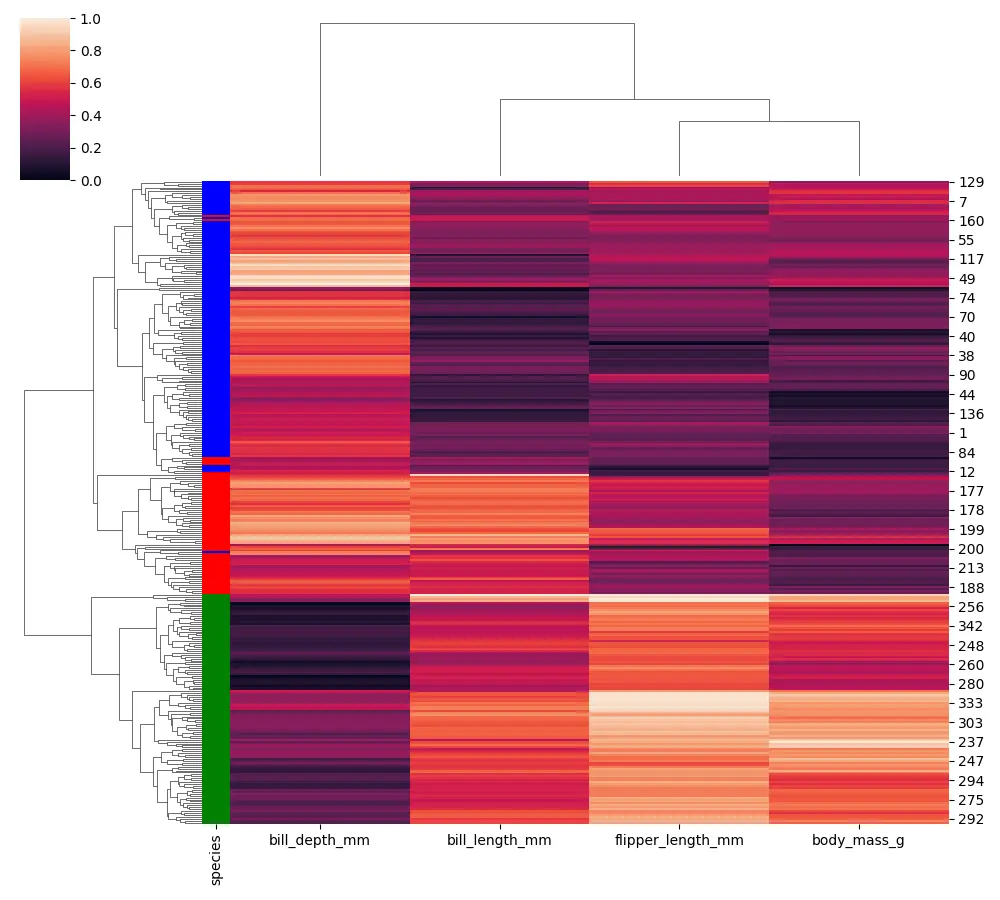
Fügen Sie die Optionen row_colors und col_colors in der Seaborn Clustermap hinzu
Es gibt einige zusätzliche Optionen, die wir beim Erstellen unserer Clusterkarte verwenden können. Die zusätzlichen Optionen bei der Seaborn-Clusterkarte heißen row_colors oder col_colors.
Jetzt weisen wir jede Farbe zu und ziehen diese Daten aus unserer Pinguin-Spalte Spezies (der kategorialen Spalte).
Code:
import seaborn as sb
import matplotlib.pyplot as plot
import numpy as np
import pandas as pd
PENGUINS = sb.load_dataset("penguins").dropna()
PENGUINS.head()
NUMERICAL_COLS = PENGUINS.columns[2:6]
SPECIES_COLORS = PENGUINS.species.map(
{"Adelie": "blue", "Chinstrap": "red", "Gentoo": "green"}
)
sb.clustermap(
PENGUINS[NUMERICAL_COLS],
figsize=(10, 9),
standard_scale=1,
row_colors=SPECIES_COLORS,
)
plot.show()
Wir können für jede Reihe eine Flagge mit den verschiedenen Arten von Pinguinarten sehen.
Ausgang:
Seaborn nutzt scipy oder fast Cluster im Backend, wenn Sie also mehr über diese verfügbaren Verknüpfungsoptionen erfahren möchten, können Sie sich die scipy Dokumentation ansehen.

Hello! I am Salman Bin Mehmood(Baum), a software developer and I help organizations, address complex problems. My expertise lies within back-end, data science and machine learning. I am a lifelong learner, currently working on metaverse, and enrolled in a course building an AI application with python. I love solving problems and developing bug-free software for people. I write content related to python and hot Technologies.
LinkedIn