Crear un ClusterMap en Seaborn
-
Crear un Clustermap usando el método
clustermap()en Seaborn -
Agregue las opciones
row_colorsycol_colorsen el mapa de clúster de Seaborn

En esta demostración, aprenderemos qué es un mapa de conglomerados y cómo podemos crearlo y usarlo para múltiples opciones.
Crear un Clustermap usando el método clustermap() en Seaborn
El mapa de conglomerados seaborn es un gráfico matricial en el que puede visualizar sus entidades matriciales a través de un mapa de calor, pero también obtendremos una agrupación de sus filas y columnas.
Importemos algunas bibliotecas requeridas.
Código:
import seaborn as sb
import matplotlib.pyplot as plot
import numpy as np
import pandas as pd
Ahora, crearemos algunos datos sobre cuatro estudiantes hipotéticos. Tendremos sus nombres, horas de estudio, puntajes en una prueba y direcciones de calles.
Código:
TOY_DATA_DICT = {
"Name": ["Andrew", "Victor", "John", "Sarah"],
"study_hours": [11, 25, 22, 14],
"Score": [11, 30, 28, 19],
"Street_Address": [20, 30, 21, 12],
}
Entonces, estos datos de juguetes están en un diccionario, pero los convertiremos en un marco de datos de Pandas y estableceremos el índice como el nombre del estudiante.
Código:
TOY_DATA = pd.DataFrame(TOY_DATA_DICT)
TOY_DATA.set_index("Name", inplace=True)
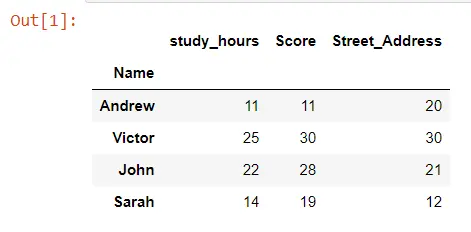
TOY_DATA
Entonces, tenemos cuatro estudiantes hipotéticos y tres columnas de datos diferentes. Como podemos observar aquí, hemos diseñado este conjunto de datos a propósito para que nuestras horas_estudio y puntuación sean bastante similares para cada estudiante.
Producción:
Hagamos un mapa de conglomerados para este marco de datos utilizando el método clustermap(). Solo necesitamos pasar el marco de datos completo llamado TOY_DATA.
Usamos un argumento de palabra clave más, annot, y lo configuramos como True. Este argumento nos permitirá ver los números reales impresos en la parte del mapa de calor del mapa de conglomerados.
Código:
import seaborn as sb
import matplotlib.pyplot as plot
import numpy as np
import pandas as pd
TOY_DATA_DICT = {
"Name": ["Andrew", "Victor", "John", "Sarah"],
"study_hours": [11, 25, 22, 14],
"Score": [11, 30, 28, 19],
"Street_Address": [20, 30, 21, 12],
}
TOY_DATA = pd.DataFrame(TOY_DATA_DICT)
TOY_DATA.set_index("Name", inplace=True)
TOY_DATA
sb.clustermap(TOY_DATA, figsize=(6, 4), annot=True)
plot.show()
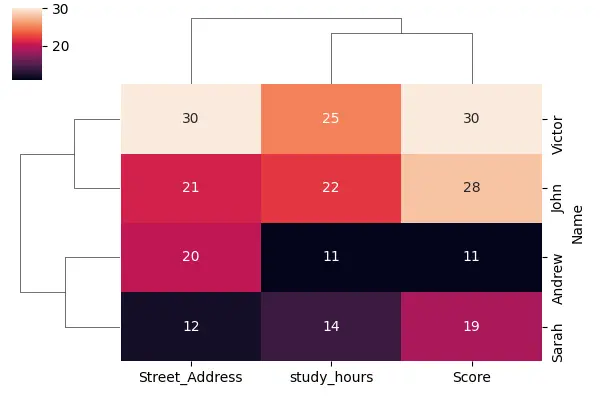
Tenemos valores más bajos con colores más oscuros y valores más altos con colores más claros, y también podemos notar que tenemos líneas a la izquierda y en la parte superior de este mapa de calor. Esas líneas se llaman dendrogramas, que es la forma en que Seaborn ha agrupado nuestros datos.
Podemos ver que nuestros study_hours y score se han agrupado juntos, mostrándonos la distancia desde las horas de estudio hasta el puntaje. Y dado que su distancia es la más pequeña, se agruparán primero en el dendrograma, y luego agregaremos street_address, que es menos similar a estas otras dos columnas.
Podemos decir que este dendrograma nos da una idea de qué tan lejos está cada una de estas diferentes columnas entre sí, y lo mismo sucede en las filas. También notará que Seaborn ha reordenado nuestras filas y nuestras columnas.
Producción:
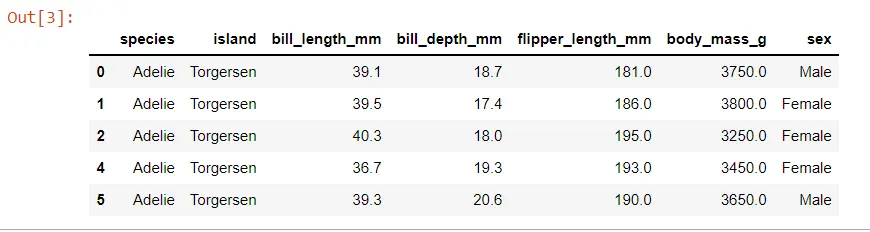
Veamos el mapa de conglomerados en un conjunto de datos avanzado. Estamos cargando algunos datos de la biblioteca Seaborn, y estos datos son sobre pingüinos.
Código:
PENGUINS = sb.load_dataset("penguins").dropna()
PENGUINS.head()
Producción:
Tenemos alrededor de 300 pingüinos diferentes en este conjunto de datos y podemos ver la forma de los datos usando el atributo forma.
Código:
print(PENGUINS.shape)
Producción:
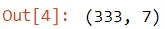
Construyamos un mapa de conglomerados para estos datos. Los datos que pasamos a uno de estos mapas de conglomerados deben ser numéricos, por lo que debemos filtrarlos solo a las columnas numéricas de este marco de datos.

Hagamos un mapa de clúster avanzado.
import seaborn as sb
import matplotlib.pyplot as plot
import numpy as np
import pandas as pd
PENGUINS = sb.load_dataset("penguins").dropna()
PENGUINS.head()
print(PENGUINS.shape)
NUMERICAL_COLS = PENGUINS.columns[2:6]
print(NUMERICAL_COLS)
sb.clustermap(PENGUINS[NUMERICAL_COLS], figsize=(6, 6))
plot.show()
Cuando ejecutamos este código, inmediatamente veremos que tenemos tres columnas con valores muy oscuros y solo una columna con valores muy claros. Eso es porque tenemos diferentes escalas para estas diferentes columnas.
Producción:
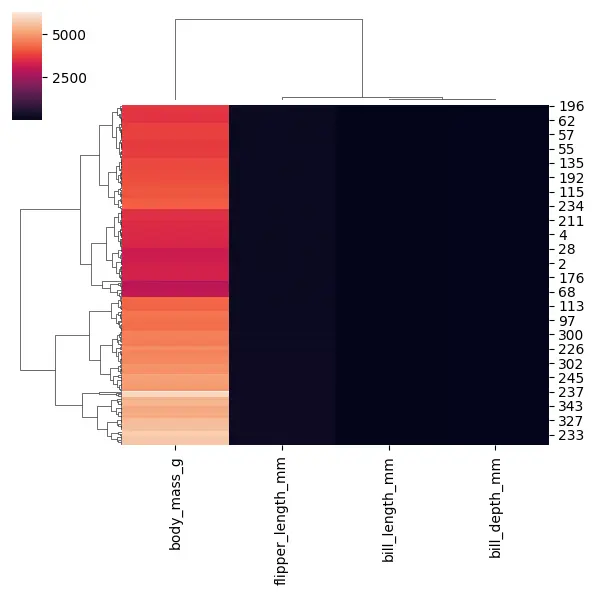
Tres columnas tienen valores más pequeños y una columna, body_mass_g, tiene valores muy grandes. Pero esto puede generar una especie de mapa de calor inútil, por lo que debemos escalar nuestros datos.
Hay algunas formas de escalar nuestros datos dentro del mapa de conglomerados, pero una forma fácil es usar este argumento llamado escala_estándar. El valor de este argumento será 0 si queremos escalar cada fila o 1 si vamos a escalar cada columna.
Código:
import seaborn as sb
import matplotlib.pyplot as plot
import numpy as np
import pandas as pd
PENGUINS = sb.load_dataset("penguins").dropna()
PENGUINS.head()
print(PENGUINS.shape)
NUMERICAL_COLS = PENGUINS.columns[2:6]
print(NUMERICAL_COLS)
sb.clustermap(PENGUINS[NUMERICAL_COLS], figsize=(6, 6), standard_scale=1)
plot.show()
Ahora, todos los valores se muestran entre 0 y 1. Nos ayuda a poner cada una de esas columnas en la misma escala para compararlas más fácilmente.
También podemos ver que todos los diferentes pingüinos se han agrupado, lo que podría ayudarnos a descubrir qué pingüinos son más similares entre sí.
Producción:
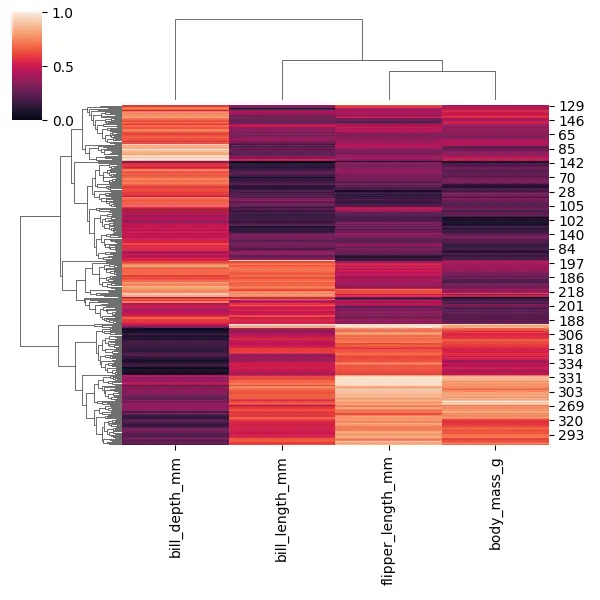
En el mapa de conglomerados marítimos, podemos cambiar tanto el enlace como la matriz utilizada para juzgar las distancias, así que intentemos cambiar el enlace usando el argumento del método. Podemos pasar la cadena como un valor llamado single, que es un enlace mínimo.
Código:
import seaborn as sb
import matplotlib.pyplot as plot
import numpy as np
import pandas as pd
PENGUINS = sb.load_dataset("penguins").dropna()
PENGUINS.head()
print(PENGUINS.shape)
NUMERICAL_COLS = PENGUINS.columns[2:6]
print(NUMERICAL_COLS)
sb.clustermap(
PENGUINS[NUMERICAL_COLS], figsize=(10, 9), standard_scale=1, method="single"
)
plot.show()
Notarás que nuestro dendrograma comienza a ser ligeramente diferente cuando usamos un solo enlace.
Producción:
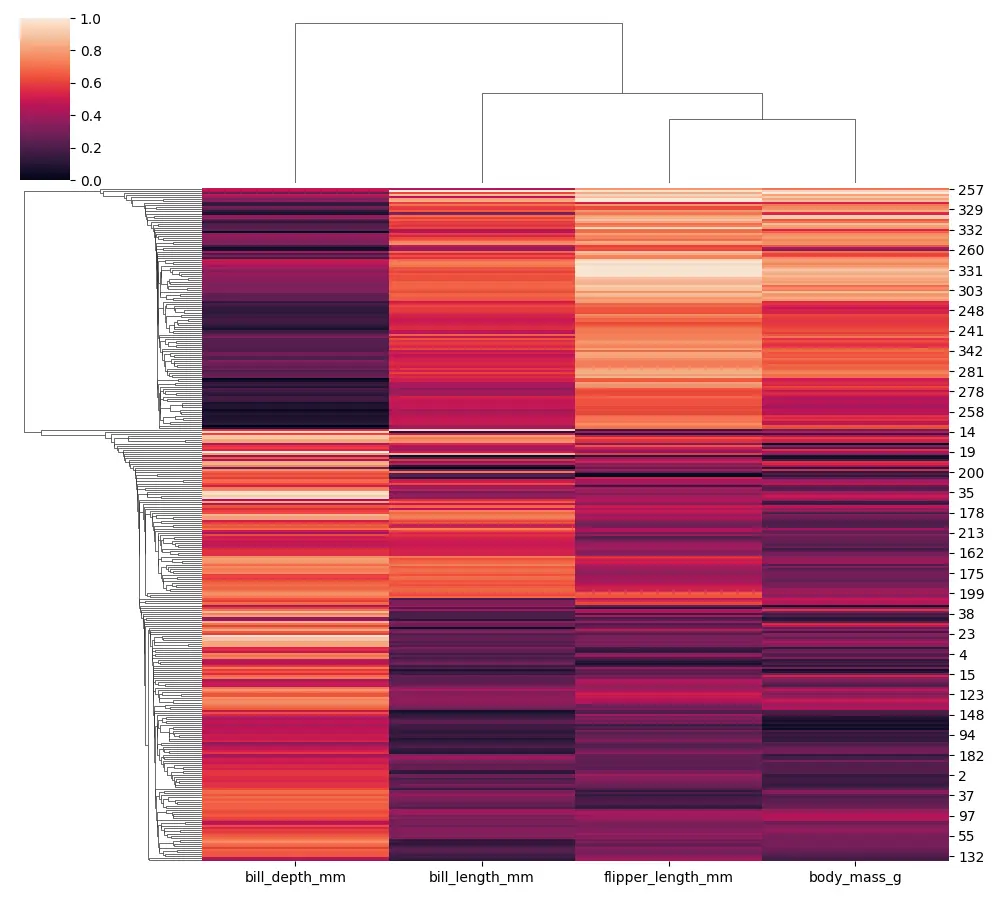
Agregue las opciones row_colors y col_colors en el mapa de clúster de Seaborn
Hay algunas opciones adicionales que podemos usar cuando construimos nuestro mapa de conglomerados. Las opciones adicionales con el mapa de clúster marino se llaman row_colors o col_colors.
Ahora, asignamos cada color y extraemos estos datos de nuestra columna de especies de pingüinos (la columna categórica).
Código:
import seaborn as sb
import matplotlib.pyplot as plot
import numpy as np
import pandas as pd
PENGUINS = sb.load_dataset("penguins").dropna()
PENGUINS.head()
NUMERICAL_COLS = PENGUINS.columns[2:6]
SPECIES_COLORS = PENGUINS.species.map(
{"Adelie": "blue", "Chinstrap": "red", "Gentoo": "green"}
)
sb.clustermap(
PENGUINS[NUMERICAL_COLS],
figsize=(10, 9),
standard_scale=1,
row_colors=SPECIES_COLORS,
)
plot.show()
Podemos ver una bandera por cada fila con los diferentes tipos de especies de pingüinos.
Producción:
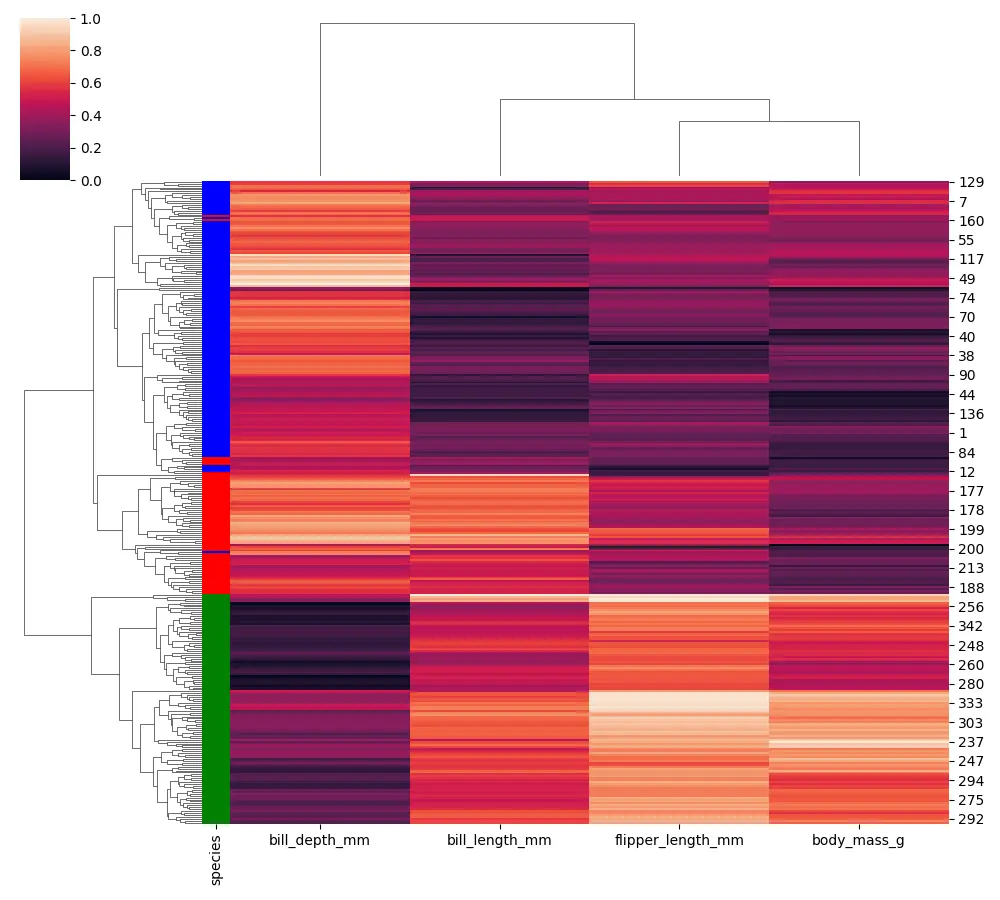
Seaborn está aprovechando scipy o fast cluster en el backend, por lo que si desea obtener más información sobre estas opciones de vinculación disponibles, puede consultar la documentación de scipy.

Hello! I am Salman Bin Mehmood(Baum), a software developer and I help organizations, address complex problems. My expertise lies within back-end, data science and machine learning. I am a lifelong learner, currently working on metaverse, and enrolled in a course building an AI application with python. I love solving problems and developing bug-free software for people. I write content related to python and hot Technologies.
LinkedIn