Datei mit C++ in einen binären Suchbaum einlesen
- Binärer Suchbaum in C++
- Einfügen in den binären Suchbaum in C++
- Löschung im binären Suchbaum in C++
- Lesen Sie die Datei in C++ in einen binären Suchbaum ein
In diesem Tutorial wird das Einlesen der Datei in einen binären Suchbaum in C++ erläutert. Zuerst werden wir schnell den binären Suchbaum und seine Funktionsweise besprechen.
Später werden wir sehen, wie man die Datei in einen binären Suchbaum einliest.
Binärer Suchbaum in C++
Der binäre Suchbaum ist ein binärer Baum mit einer speziellen Anordnung von Knoten, die später bei der Suche hilft. An dieser Stelle sei erwähnt, dass Statistiken zeigen, dass mehr als 90 % der Operationen Suchoperationen sind, wohingegen; Weniger als 10 % der Operationen umfassen Einfügen, Aktualisieren, Löschen usw.
In dem binären Suchbaum wird jeder Knoten so platziert, dass der Knoten immer größer als sein linkes Kind und kleiner als gleich (im Falle einer Duplizierung) seines rechten Kindes ist.
Diese Definition gilt rekursiv für jeden Knoten des Baums. Somit haben wir immer eine Wurzel, die größer als alle Knoten in ihrem linken Teilbaum und kleiner als gleich allen Knoten in ihrem rechten Teilbaum ist.
5 / 3 8 / \ / 1 2 6 9
Hier sehen Sie ein Beispiel für einen binären Suchbaum, der selbsterklärend ist; Wie zuvor hilft ein binärer Suchbaum bei der Suchoperation.
Zum Beispiel, wenn wir im obigen Baum nach 7 (sagen Sie es Taste) suchen möchten. Wir werden den Schlüssel mit dem Wurzelknoten 5 vergleichen.
Der Schlüssel ist größer als das Wurzelelement; Daher müssen wir nur im rechten Teilbaum nach dem Schlüssel suchen, da alle Werte im linken Teilbaum kleiner als der Wurzelknoten sind.
Als nächstes vergleichen wir den Schlüssel mit 8 und bewegen uns zum linken Teilbaum von 8, weil der Schlüssel kleiner als 8 ist. Als nächstes vergleichen wir 6 mit dem Schlüssel und bewegen uns zum rechten Teilbaum von 6.
Rechts von 6 haben wir NULL; deshalb stoppen wir das Element nicht gefunden. Wir haben 3 Vergleiche statt 6 durchgeführt.
Je mehr Elemente wir im Baum haben, desto geringer wird das Verhältnis der Vergleiche mit den gesamten Elementen im Baum. Die Suche erscheint trivial; Den vollständigen Code geben wir Ihnen jedoch später.
Bevor wir den vollständigen Code präsentieren, lassen Sie uns die Einfüge- und Löschvorgänge im BST besprechen. Es ist jedoch besser, zuerst die Definition der Klasse Node zu sehen.
template <class T>
class Node {
public:
T data;
Node* left;
Node* right;
Node(T data) {
this->data = data;
this->left = NULL;
this->right = NULL;
}
};
Hier haben wir eine Vorlage verwendet, um denselben Baum für jeden Datentyp zu verwenden. Den Nutzen zeigen wir Ihnen beim Einsatz unseres BST.
In unserer Definition der Klasse Node haben wir Daten vom Typ Vorlage, die wir zum Zeitpunkt der Objekterstellung auswählen können. Wir haben linke und rechte Zeiger, da wir unsere baumverknüpfte Implementierung implementieren werden.
Im Konstruktor weisen wir neben den Daten den linken und rechten Zeigern NULL zu, da jeder neue Knoten am Anfang keine linken und rechten untergeordneten Knoten hat.
Einfügen in den binären Suchbaum in C++
Erwägen Sie das Einfügen des neuen Elements in die BST. Es gibt zwei mögliche Fälle, entweder ist der Baum leer oder hat einen oder mehrere Knoten.
Der erste Fall ist, dass der Baum leer ist; das neue Element wird nach dieser Einfügung zum Wurzelknoten des Baums. Im zweiten Fall wird der neue Knoten entweder linkes oder rechtes Kind eines bestehenden Knotens.
Daher beginnen wir beim Wurzelknoten und vergleichen den Wert des Knotens mit unserem neuen Wert; Wir bewegen uns entweder links vom aktuellen Knoten oder rechts vom aktuellen Knoten.
Schließlich erreichen wir einen Punkt, an dem wir NULL (kein Knoten) haben; Wir werden einen neuen Knoten erstellen und ihn entsprechend den Werten des Knotens und des neuen Knotens zu einem linken oder rechten Kind machen.
Wenn wir beispielsweise den Knoten 7 in die BST einfügen, lautet die neue BST:
5 / 2 8 / \ /
1 3 6 9
7
Ausgehend vom Wurzelknoten ist 5 kleiner als 7, also nach rechts gehen. 8 ist größer, also bewegen wir uns auf die linke Seite. 6 ist kleiner; daher nach rechts bewegen.
Auf der rechten Seite gibt es keinen Knoten, also erstellen wir einen neuen Knoten und machen ihn zum rechten Kind des Knotens 6. Wir werden die Implementierung der Einfügefunktion sehen, aber vorher sehen Sie sich die Definition der Klasse BST an.
template <class T>
class BST {
Node<T> *root;
public:
BST() { root = NULL; }
...
Wir haben wieder eine Template-Klasse für BST erstellt, die nur das Datenelement root vom Typ Node<T> enthält. Im Konstruktor haben wir dem Knoten root NULL zugewiesen, was bedeutet, dass der Baum leer ist.
Daher weisen wir im Falle einer Löschung immer dann, wenn wir den letzten Knoten löschen, dem Wurzelknoten NULL zu. Sehen wir uns die Funktion Einfügen an.
Node<T>* insert(T key) { root = insert(root, key); }
Node<T>* insert(Node<T>* temp, T key) {
if (temp == NULL) return new Node<T>(key);
if (temp->data > key)
temp->left = insert(temp->left, key);
else
temp->right = insert(temp->right, key);
return temp;
}
Erstens haben wir eine Wrapper-Funktion, um die Workhorse-Funktion aufzurufen, die die Einfügeaufgabe ausführt. Der Grund für das Schreiben der Wrapper-Funktion ist, dass wir aus Sicherheitsgründen keinen Zugriff auf den root-Knoten ausserhalb der Klasse gewähren wollen.
Klicken Sie auf Wrapper-Funktion, wenn Sie mehr über Wrapper-Funktionen erfahren möchten.
In unserer Workhorse-Funktion haben wir eine rekursive Implementierung, bei der der Basisfall ein NULL-Knoten ist, bei dem wir einen neuen Knoten erstellen und seine Adresse an den Aufrufer zurückgeben, der diese Adresse entweder dem linken oder dem rechten Kind zum Verknüpfen zuweist der neue Knoten im Baum.
Wenn wir keinen NULL-Knoten haben, vergleichen wir die Daten und gehen nach rechts oder links, je nachdem, ob der aktuelle Knoten einen kleineren oder größeren Wert hat, da wir bereits die Suchstrategie besprochen haben.
Löschung im binären Suchbaum in C++
Wie beim Einfügen gibt es beim Löschen eines Elements im BST zwei mögliche Fälle. Entweder löschen wir den letzten Knoten, den Wurzelknoten, oder wir löschen einen Knoten, bei dem wir mehr als einen Knoten im Baum haben, sodass der Baum nach dem Löschen des aktuellen Knotens nicht leer wird.
Im ersten Fall löschen wir den Knoten und weisen dem Wurzelknoten NULL zu. Im zweiten Fall haben wir drei Möglichkeiten:
- Knoten hat keinen untergeordneten Knoten
- Knoten hat nur einen untergeordneten Knoten
- Knoten hat sowohl linke als auch rechte untergeordnete Knoten
Die ersten beiden Schemata sind sehr einfach. Falls es keinen untergeordneten Knoten gibt.
Löschen Sie den Knoten und geben Sie NULL zurück (da wir wieder eine rekursive Definition haben), damit der übergeordnete Knoten beim Aufrufen der Funktion seinem rechten oder linken Zeiger NULL zuweist.
Wenn der Knoten einen untergeordneten Knoten hat, ersetzen Sie den untergeordneten Knoten durch den aktuellen Knoten und löschen Sie den aktuellen Knoten. Infolgedessen wird der untergeordnete Knoten dem Großvater anstelle des Vaters zugewiesen, da der Vater sterben wird (Entschuldigung für diese Analogie).
Der letzte Fall ist knifflig, wenn ein Knoten sowohl linke als auch rechte Kinder hat. In diesem Fall haben wir zwei Möglichkeiten.
Wählen Sie zuerst den am weitesten links liegenden untergeordneten Knoten aus der rechten Unterstruktur des aktuellen Knotens oder den am weitesten rechts liegenden untergeordneten Knoten aus der linken Unterstruktur aus. Kopieren Sie in beiden Fällen den Wert des ausgewählten Knotens in den aktuellen Knoten.
Jetzt haben wir zwei Knoten im BST mit demselben Wert; Daher rufen wir die rekursive delete-Funktion erneut im linken Teilbaum oder rechten Teilbaum des aktuellen Knotens auf.
Betrachten Sie das Beispiel; Nehmen wir an, wir möchten 5 aus dem Root-Knoten löschen. Wir können den Knoten 6 aus dem rechten Unterbaum auswählen, der der Knoten ganz links im rechten Unterbaum von 5 ist, oder wir können den Knoten 3 aus dem linken Unterbaum auswählen, der der Knoten ganz rechts ist der linke Teilbaum von 5.
5 3 6 / \ / \ / 2 8 2 8 2 8 / \ / \ / / \ / \ 1 3 6 9 1 6 9 1 3 9
Sehen wir uns die Implementierung der Funktion Löschen an.
Node<T>* deleteNode(T key) { root = deleteNode(root, key); }
Node<T>* deleteNode(Node<T>* temp, T key) {
if (temp == NULL) return temp;
if (temp->data > key)
temp->left = deleteNode(temp->left, key);
else if (temp->data < key)
temp->right = deleteNode(temp->right, key);
else {
if (temp->left == NULL && temp->right == NULL) {
delete temp;
temp = NULL;
} else if (temp->left == NULL) {
Node<T>* curr = temp;
temp = temp->right;
delete curr;
} else if (temp->right == NULL) {
Node<T>* curr = temp;
temp = temp->left;
delete curr;
} else {
Node<T>* toBeDeleted = findMinNode(temp->right);
temp->data = toBeDeleted->data;
temp->right = deleteNode(temp->right, toBeDeleted->data);
}
}
return temp;
}
Auch hier haben wir zunächst eine Wrapper-Funktion. Als nächstes haben wir die Workhorse-Funktion.
In den ersten drei Zeilen suchen wir nach unserem Zielknoten. Der Zielwert existiert in diesem Fall nicht im Baum; letztendlich erreichen wir den NULL-Knoten.
Andernfalls gibt es drei Fälle, entweder ist der aktuelle Knoten größer als der Schlüssel oder kleiner als der Schlüssel, oder der aktuelle Knoten ist unser Zielknoten (in diesem Fall wechseln wir zum anderen Teil).
Im anderen Teil übergeben wir drei Fälle; Wir haben bereits besprochen, dass der Zielknoten keinen untergeordneten Knoten hat, nur den rechten untergeordneten Knoten, nur den linken untergeordneten Knoten und sowohl den linken als auch den rechten untergeordneten Knoten (im anderen Teil behandelt).
In diesem Teil verwenden wir die Funktion findMinNode, um den kleinsten Knoten aus dem rechten Teilbaum des aktuellen/Zielknotens auszuwählen. Sehen Sie sich jetzt die gesamte Klasse von BST an.
#include <iostream>
using namespace std;
template <class T>
class Node {
public:
T data;
Node* left;
Node* right;
Node(T data) {
this->data = data;
this->left = NULL;
this->right = NULL;
}
};
template <class T>
class BST {
Node<T>* root;
public:
BST() { root = NULL; }
Node<T>* insert(T key) { root = insert(root, key); }
Node<T>* insert(Node<T>* temp, T key) {
if (temp == NULL) return new Node<T>(key);
if (temp->data > key)
temp->left = insert(temp->left, key);
else
temp->right = insert(temp->right, key);
return temp;
}
Node<T>* findMinNode(Node<T>* temp) {
while (temp->left != NULL) temp = temp->left;
return temp;
}
Node<T>* deleteNode(T key) { root = deleteNode(root, key); }
Node<T>* deleteNode(Node<T>* temp, T key) {
if (temp == NULL) return temp;
if (temp->data > key)
temp->left = deleteNode(temp->left, key);
else if (temp->data < key)
temp->right = deleteNode(temp->right, key);
else {
if (temp->left == NULL && temp->right == NULL) {
delete temp;
temp = NULL;
} else if (temp->left == NULL) {
Node<T>* curr = temp;
temp = temp->right;
delete curr;
} else if (temp->right == NULL) {
Node<T>* curr = temp;
temp = temp->left;
delete curr;
} else {
Node<T>* toBeDeleted = findMinNode(temp->right);
temp->data = toBeDeleted->data;
temp->right = deleteNode(temp->right, toBeDeleted->data);
}
}
return temp;
}
void preOrder() {
preOrder(root);
cout << '\n';
}
void preOrder(Node<T>* temp) {
if (temp == NULL) return;
cout << temp->data << " ";
preOrder(temp->left);
preOrder(temp->right);
}
void inOrder() {
inOrder(root);
cout << '\n';
}
void inOrder(Node<T>* temp) {
if (temp == NULL) return;
inOrder(temp->left);
cout << temp->data << " ";
inOrder(temp->right);
}
};
int main() {
BST<int> tree;
tree.insert(40);
tree.insert(22);
tree.insert(15);
tree.insert(67);
tree.insert(34);
tree.insert(90);
tree.preOrder();
tree.inOrder();
tree.deleteNode(40);
cout << "After deleting 40 temp from the tree\n";
tree.preOrder();
tree.inOrder();
return 0;
}
Wir haben die gesamte BST-Klasse mit den Traversalfunktionen inOrder und preOrder, um die Form unseres Baums zu sehen. Wir können unsere BST aus In-Order- und Pre-Order-Traversal oder aus In-Order- und Post-Order-Traversal aufbauen; Sie können diesen Artikel lesen.
Sehen wir uns die Ausgabe des Codes an.
40 22 15 34 67 90
15 22 34 40 67 90
After deleting 40 temp from the tree
67 22 15 34 90
15 22 34 67 90
In dieser Ausgabe hat die erste Zeile einen Vorordnungsdurchlauf und die zweite Zeile einen In-Order-Durchlauf. Zunächst einmal gibt In-Order-BST immer sortierte Elemente aus.
Daher bestätigt die zweite Zeile irgendwie, dass unser Code das Einfügen richtig durchführt.
Aus den ersten beiden Zeilen (Traversalen) können wir einen binären Baum konstruieren. Die Vorbestellung beginnt immer mit der Traversierung vom Root-Knoten; daher ist 40 der Wurzelknoten.
Wenn wir 40 in In-Order Traversal (zweite Zeile) sehen, können wir unseren Binärbaum in linke und rechte Teilbäume unterteilen, wobei 67 und 90 im rechten Teilbaum stehen und 15 , 22 und 34 befinden sich im linken Unterbaum; In ähnlicher Weise können wir den verbleibenden Binärbaum vervollständigen. Schließlich ist unser Binärbaum:
40 / 22 67 / \ 15 34 90
Dieser Binärbaum hat Eigenschaften von BST und zeigt, dass unser Code gut funktioniert; ähnlich können wir nach dem Löschen von 40 einen binären Baum konstruieren.
67 / 22 90 / 15 34
Knoten 40 ist unser Zielknoten, der sowohl linke als auch rechte Kindknoten hat. Wir haben den am weitesten links befindlichen aus dem rechten Unterbaum ausgewählt, nämlich 67, weil 67 kein linkes Kind hat; Daher haben wir den Wert 67 an unseren Zielknoten kopiert und die Funktion Löschen erneut aufgerufen, um 67 aus dem rechten Teilbaum der Wurzel zu löschen.
Jetzt haben wir einen Fall, in dem 67 das einzig richtige Kind hat, 90; deshalb ersetzen wir 90 durch 67. Damit wird 90 das rechte Kind von 67.
Lesen Sie die Datei in C++ in einen binären Suchbaum ein
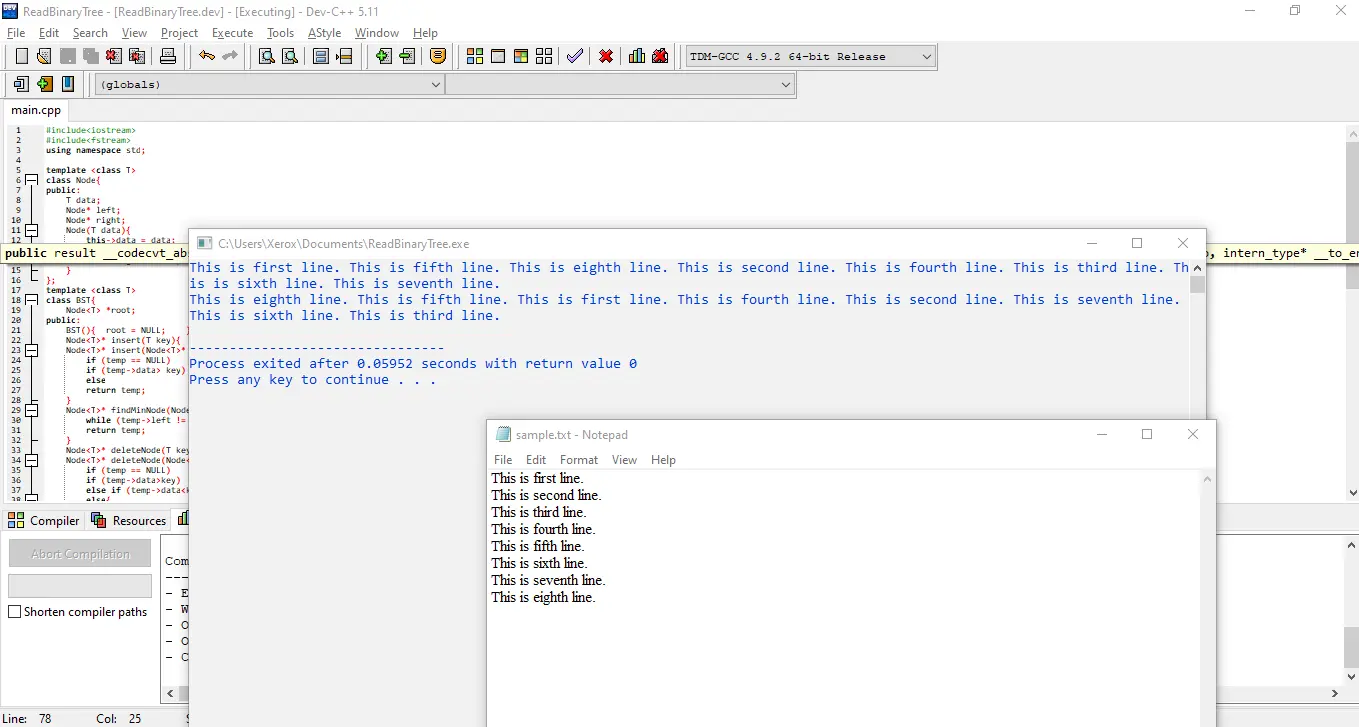
Schließlich können wir jetzt das Einlesen von Dateien in BST besprechen. Auch hier werden wir es Schritt für Schritt tun.
Betrachten Sie zunächst die folgende Datei.
This is first line.
This is second line.
This is third line.
This is fourth line.
This is fifth line.
This is sixth line.
This is seventh line.
This is eighth line.
Wir können diese Datei einfach in C++ mit der Funktion getline lesen. Siehe Code:
#include <fstream>
#include <iostream>
using namespace std;
int main() {
ifstream in("sample.txt");
string s;
while (getline(in, s)) cout << s << '\n';
in.close();
}
Wir haben die gleiche Ausgabe, die Sie im Inhalt der Datei im vorherigen Kasten sehen können. Unser Ziel ist es jedoch, Text in BST zu platzieren, damit wir eine schnellere Suche durchführen können.
Es ist also einfach; Wir haben BST bereits in der Klassenvorlage implementiert, die wir auch für Zeichenfolgen verwenden können. Alles, was wir tun müssen, ist, ein entsprechendes Objekt von BST zu erstellen.
Sie können Inhalte in der Datei sample.txt speichern, um die Datei durch Code zu lesen. Hier haben wir den Code, um die Datei in einen binären Suchbaum einzulesen.
#include <fstream>
#include <iostream>
using namespace std;
template <class T>
class Node {
public:
T data;
Node* left;
Node* right;
Node(T data) {
this->data = data;
this->left = NULL;
this->right = NULL;
}
};
template <class T>
class BST {
Node<T>* root;
public:
BST() { root = NULL; }
Node<T>* insert(T key) { root = insert(root, key); }
Node<T>* insert(Node<T>* temp, T key) {
if (temp == NULL) return new Node<T>(key);
if (temp->data > key)
temp->left = insert(temp->left, key);
else
temp->right = insert(temp->right, key);
return temp;
}
Node<T>* findMinNode(Node<T>* temp) {
while (temp->left != NULL) temp = temp->left;
return temp;
}
Node<T>* deleteNode(T key) { root = deleteNode(root, key); }
Node<T>* deleteNode(Node<T>* temp, T key) {
if (temp == NULL) return temp;
if (temp->data > key)
temp->left = deleteNode(temp->left, key);
else if (temp->data < key)
temp->right = deleteNode(temp->right, key);
else {
if (temp->left == NULL && temp->right == NULL) {
delete temp;
temp = NULL;
} else if (temp->left == NULL) {
Node<T>* curr = temp;
temp = temp->right;
delete curr;
} else if (temp->right == NULL) {
Node<T>* curr = temp;
temp = temp->left;
delete curr;
} else {
Node<T>* toBeDeleted = findMinNode(temp->right);
temp->data = toBeDeleted->data;
temp->right = deleteNode(temp->right, toBeDeleted->data);
}
}
return temp;
}
void preOrder() {
preOrder(root);
cout << '\n';
}
void preOrder(Node<T>* temp) {
if (temp == NULL) return;
cout << temp->data << " ";
preOrder(temp->left);
preOrder(temp->right);
}
void inOrder() {
inOrder(root);
cout << '\n';
}
void inOrder(Node<T>* temp) {
if (temp == NULL) return;
inOrder(temp->left);
cout << temp->data << " ";
inOrder(temp->right);
}
};
int main() {
BST<string> tree;
ifstream in("sample.txt");
string s;
while (getline(in, s)) tree.insert(s);
tree.preOrder();
tree.inOrder();
in.close();
return 0;
}
Ausgang:
Wiederum haben wir zuerst eine Preorder-Traversierung, die zeigt, dass der Wurzelknoten Dies ist die erste Zeile ist; Wenn wir jedoch In-Order-Traversal sehen, haben wir die Ausgabe in sortierter Reihenfolge.
Das heißt, achte beginnend mit e, dem kleinsten Buchstaben unter erster, zweiter, dritter, vierter, fünfter, sechster, siebter und achter, während Als nächstes haben wir fifth, was kleiner als first ist, weil f in fifth kleiner ist als r in first.