C++를 사용하여 이진 검색 트리로 파일 읽기
이 자습서에서는 파일을 C++에서 이진 검색 트리로 읽는 방법에 대해 설명합니다. 먼저 이진 검색 트리와 그 작동에 대해 빠르게 설명합니다.
나중에 파일을 이진 검색 트리로 읽는 방법을 살펴보겠습니다.
C++의 이진 검색 트리
이진 검색 트리는 나중에 검색에 도움이 되는 특별한 노드 배열이 있는 이진 트리입니다. 여기에서 통계에 따르면 작업의 90% 이상이 검색 작업인 것으로 나타났습니다. 작업의 10% 미만에는 삽입, 업데이트, 삭제 등이 포함됩니다.
이진 검색 트리에서 각 노드는 노드가 항상 왼쪽 자식보다 크고 오른쪽 자식보다 작도록(중복의 경우) 배치됩니다.
이 정의는 트리의 모든 노드에 재귀적으로 적용됩니다. 따라서 항상 왼쪽 하위 트리의 모든 노드보다 크고 오른쪽 하위 트리의 모든 노드보다 작은 루트가 있습니다.
5 / 3 8 / \ / 1 2 6 9
여기에서 자명한 이진 검색 트리의 예를 볼 수 있습니다. 이전과 마찬가지로 이진 검색 트리는 검색 작업에 도움이 됩니다.
예를 들어 위의 트리에서 7(키라고 말하십시오)을 검색하려는 경우입니다. 키를 루트 노드 5와 비교합니다.
키가 루트 요소보다 큽니다. 따라서 왼쪽 하위 트리의 모든 값이 루트 노드보다 작기 때문에 오른쪽 하위 트리에서만 키를 검색해야 합니다.
다음으로 키를 8과 비교하고 키가 8보다 작기 때문에 8의 왼쪽 하위 트리로 이동합니다. 다음으로 6을 키와 비교하고 6의 오른쪽 하위 트리로 이동합니다.
6의 오른쪽에는 NULL이 있습니다. 따라서 요소를 찾을 수 없음을 중지합니다. 6 대신 3 비교를 수행했습니다.
트리에 있는 요소가 많을수록 트리의 전체 요소와의 비교 비율이 더 줄어듭니다. 검색은 사소한 것 같습니다. 그러나 나중에 완전한 코드를 제공할 것입니다.
전체 코드를 제시하기 전에 BST의 삽입 및 삭제 작업에 대해 논의해 봅시다. 그러나 먼저 Node 클래스의 정의를 확인하는 것이 좋습니다.
template <class T>
class Node {
public:
T data;
Node* left;
Node* right;
Node(T data) {
this->data = data;
this->left = NULL;
this->right = NULL;
}
};
여기에서는 템플릿을 사용하여 모든 데이터 유형에 대해 동일한 트리를 사용했습니다. BST를 사용할 때의 이점을 보여드리겠습니다.
Node 클래스의 정의에는 객체 생성 시 선택할 수 있는 템플릿 유형의 데이터가 있습니다. 트리 링크 구현을 구현할 때 왼쪽 및 오른쪽 포인터가 있습니다.
생성자에서 데이터 외에 시작의 모든 새 노드에는 왼쪽 및 오른쪽 자식 노드가 없기 때문에 왼쪽 및 오른쪽 포인터에 NULL을 할당합니다.
C++에서 이진 검색 트리에 삽입
BST에 새 요소를 삽입하는 것을 고려하십시오. 트리가 비어 있거나 하나 이상의 노드가 있는 두 가지 가능한 경우가 있습니다.
첫 번째 경우는 트리가 비어 있는 경우입니다. 새 요소는 이 삽입 후 트리의 루트 노드가 됩니다. 두 번째 경우 새 노드는 기존 노드의 왼쪽 또는 오른쪽 자식이 됩니다.
따라서 루트 노드에서 시작하여 노드의 값을 새 값과 비교합니다. 현재 노드의 왼쪽이나 현재 노드의 오른쪽으로 이동합니다.
마지막으로 NULL(노드 없음)이 있는 지점에 도달합니다. 새 노드를 만들고 노드와 새 노드의 값에 따라 왼쪽 또는 오른쪽 자식으로 만듭니다.
예를 들어 BST에 노드 7을 삽입하면 새 BST는 다음과 같습니다.
5 / 2 8 / \ /
1 3 6 9
7
루트 노드에서 시작하여 5는 7보다 작으므로 오른쪽으로 이동합니다. 8이 더 크므로 왼쪽으로 이동합니다. 6은 더 작습니다. 따라서 오른쪽으로 이동하십시오.
오른쪽에는 노드가 없으므로 새 노드를 만들고 노드 6의 오른쪽 자식으로 만듭니다. 삽입 함수의 구현을 볼 수 있지만 그 전에 클래스 BST의 정의를 참조하십시오.
template <class T>
class BST {
Node<T> *root;
public:
BST() { root = NULL; }
...
다시 한 번, Node<T> 유형의 데이터 멤버 root만 있는 BST용 템플릿 클래스를 만들었습니다. 생성자에서 NULL을 루트 노드에 할당했습니다. 이는 트리가 비어 있음을 의미합니다.
따라서 삭제의 경우 마지막 노드를 삭제할 때마다 루트 노드에 NULL을 할당합니다. 삽입 기능을 살펴보겠습니다.
Node<T>* insert(T key) { root = insert(root, key); }
Node<T>* insert(Node<T>* temp, T key) {
if (temp == NULL) return new Node<T>(key);
if (temp->data > key)
temp->left = insert(temp->left, key);
else
temp->right = insert(temp->right, key);
return temp;
}
먼저 삽입 작업을 수행하는 주력 함수를 호출하는 래퍼 함수가 있습니다. 래퍼 함수를 작성하는 이유는 보안상의 이유로 클래스 외부의 루트 노드에 대한 액세스 권한을 부여하고 싶지 않기 때문입니다.
래퍼 기능에 대해 알고 싶다면 래퍼 기능을 클릭하세요.
주력 함수에는 기본 사례가 NULL 노드인 재귀 구현이 있습니다. 여기에서 새 노드를 만들고 해당 주소를 호출자에게 반환하고 이 주소를 왼쪽 또는 오른쪽 자식에 할당하여 링크에 할당합니다. 트리의 새 노드.
NULL 노드가 없으면 이미 검색 전략을 논의한 것처럼 데이터를 비교하고 현재 노드의 값이 더 작거나 큰지에 따라 오른쪽 또는 왼쪽으로 이동합니다.
C++의 이진 검색 트리에서 삭제
삽입과 마찬가지로 BST의 요소 삭제에는 두 가지 가능한 경우가 있습니다. 마지막 노드인 루트 노드를 삭제하거나 트리에 둘 이상의 노드가 있는 일부 노드를 삭제하여 현재 노드를 삭제한 후에도 트리가 비어 있지 않도록 합니다.
첫 번째 경우 노드를 삭제하고 NULL을 루트 노드에 할당합니다. 두 번째 경우에는 세 가지 가능성이 있습니다.
- 노드에 하위 노드가 없습니다.
- 노드에는 자식 노드가 하나만 있습니다.
- 노드에는 왼쪽 및 오른쪽 자식 노드가 모두 있습니다.
처음 두 체계는 매우 간단합니다. 자식 노드가 없는 경우.
노드를 삭제하고 NULL을 반환하여 함수를 호출할 때 부모 노드가 오른쪽 또는 왼쪽 포인터에 NULL을 할당하도록 합니다.
노드에 자식 노드가 하나 있는 경우 자식 노드를 현재 노드로 바꾸고 현재 노드를 삭제합니다. 결과적으로 아버지가 죽기 때문에 자식 노드는 아버지 대신 할아버지에게 할당됩니다(이 유추에 대해 죄송합니다).
노드에 왼쪽 및 오른쪽 자식이 모두 있는 마지막 경우는 까다롭습니다. 이 경우 두 가지 선택이 있습니다.
먼저 현재 노드의 오른쪽 하위 트리에서 가장 왼쪽의 하위 노드를 선택하거나 왼쪽 하위 트리에서 가장 오른쪽의 하위 노드를 선택합니다. 두 경우 모두 현재 노드에서 선택 노드의 값을 복사합니다.
이제 BST에 동일한 값을 가진 두 개의 노드가 있습니다. 따라서 현재 노드의 왼쪽 하위 트리 또는 오른쪽 하위 트리에서 재귀 삭제 기능을 다시 호출합니다.
예를 고려하십시오. 루트 노드에서 5를 삭제한다고 가정합니다. 5의 오른쪽 하위 트리에서 가장 왼쪽 노드인 오른쪽 하위 트리에서 노드 6을 선택하거나 왼쪽 하위 트리에서 가장 오른쪽 노드인 3 노드를 선택할 수 있습니다. 5의 왼쪽 하위 트리.
5 3 6 / \ / \ / 2 8 2 8 2 8 / \ / \ / / \ / \ 1 3 6 9 1 6 9 1 3 9
delete 기능의 구현을 살펴보겠습니다.
Node<T>* deleteNode(T key) { root = deleteNode(root, key); }
Node<T>* deleteNode(Node<T>* temp, T key) {
if (temp == NULL) return temp;
if (temp->data > key)
temp->left = deleteNode(temp->left, key);
else if (temp->data < key)
temp->right = deleteNode(temp->right, key);
else {
if (temp->left == NULL && temp->right == NULL) {
delete temp;
temp = NULL;
} else if (temp->left == NULL) {
Node<T>* curr = temp;
temp = temp->right;
delete curr;
} else if (temp->right == NULL) {
Node<T>* curr = temp;
temp = temp->left;
delete curr;
} else {
Node<T>* toBeDeleted = findMinNode(temp->right);
temp->data = toBeDeleted->data;
temp->right = deleteNode(temp->right, toBeDeleted->data);
}
}
return temp;
}
다시 말하지만, 먼저 래퍼 함수가 있습니다. 다음으로 주력 기능이 있습니다.
처음 세 줄에서 대상 노드를 검색합니다. 이 경우 대상 값은 트리에 존재하지 않습니다. 궁극적으로 NULL 노드에 도달합니다.
그렇지 않으면 현재 노드가 키보다 크거나 작은 경우 또는 현재 노드가 대상 노드인 경우(이 경우 다른 부분으로 이동)의 세 가지 경우가 있습니다.
다른 부분에서는 세 가지 사례를 전달하고 있습니다. 대상 노드에는 자식 노드가 없고, 오른쪽 자식 노드만 있고, 왼쪽 자식 노드만 있고, 왼쪽 및 오른쪽 자식이 모두 있다는 것은 이미 논의했습니다(다른 부분에서 처리).
이 부분에서는 findMinNode 기능을 사용하여 현재/대상 노드의 오른쪽 하위 트리에서 가장 작은 노드를 선택합니다. 이제 BST의 전체 클래스를 참조하십시오.
#include <iostream>
using namespace std;
template <class T>
class Node {
public:
T data;
Node* left;
Node* right;
Node(T data) {
this->data = data;
this->left = NULL;
this->right = NULL;
}
};
template <class T>
class BST {
Node<T>* root;
public:
BST() { root = NULL; }
Node<T>* insert(T key) { root = insert(root, key); }
Node<T>* insert(Node<T>* temp, T key) {
if (temp == NULL) return new Node<T>(key);
if (temp->data > key)
temp->left = insert(temp->left, key);
else
temp->right = insert(temp->right, key);
return temp;
}
Node<T>* findMinNode(Node<T>* temp) {
while (temp->left != NULL) temp = temp->left;
return temp;
}
Node<T>* deleteNode(T key) { root = deleteNode(root, key); }
Node<T>* deleteNode(Node<T>* temp, T key) {
if (temp == NULL) return temp;
if (temp->data > key)
temp->left = deleteNode(temp->left, key);
else if (temp->data < key)
temp->right = deleteNode(temp->right, key);
else {
if (temp->left == NULL && temp->right == NULL) {
delete temp;
temp = NULL;
} else if (temp->left == NULL) {
Node<T>* curr = temp;
temp = temp->right;
delete curr;
} else if (temp->right == NULL) {
Node<T>* curr = temp;
temp = temp->left;
delete curr;
} else {
Node<T>* toBeDeleted = findMinNode(temp->right);
temp->data = toBeDeleted->data;
temp->right = deleteNode(temp->right, toBeDeleted->data);
}
}
return temp;
}
void preOrder() {
preOrder(root);
cout << '\n';
}
void preOrder(Node<T>* temp) {
if (temp == NULL) return;
cout << temp->data << " ";
preOrder(temp->left);
preOrder(temp->right);
}
void inOrder() {
inOrder(root);
cout << '\n';
}
void inOrder(Node<T>* temp) {
if (temp == NULL) return;
inOrder(temp->left);
cout << temp->data << " ";
inOrder(temp->right);
}
};
int main() {
BST<int> tree;
tree.insert(40);
tree.insert(22);
tree.insert(15);
tree.insert(67);
tree.insert(34);
tree.insert(90);
tree.preOrder();
tree.inOrder();
tree.deleteNode(40);
cout << "After deleting 40 temp from the tree\n";
tree.preOrder();
tree.inOrder();
return 0;
}
트리의 모양을 보기 위해 inOrder 및 preOrder 순회 함수가 있는 전체 BST 클래스가 있습니다. 순차 및 선주문 순회 또는 순차 및 후순 순회에서 BST를 구축할 수 있습니다. 이 기사를 읽을 수 있습니다.
코드의 출력을 보자.
40 22 15 34 67 90
15 22 34 40 67 90
After deleting 40 temp from the tree
67 22 15 34 90
15 22 34 67 90
이 출력에서 첫 번째 줄에는 사전 순회가 있고 두 번째 줄에는 순회가 있습니다. 우선 순서대로 BST는 항상 정렬된 요소를 제공합니다.
따라서 두 번째 줄은 어떻게든 코드가 제대로 삽입되고 있음을 확인합니다.
처음 두 줄(순회)에서 이진 트리를 구성할 수 있습니다. 선주문은 항상 루트 노드에서 순회를 시작합니다. 따라서 40은 루트 노드입니다.
순서 순회(두 번째 줄)에서 40이 표시되면 이진 트리를 왼쪽 및 오른쪽 하위 트리로 분할할 수 있습니다. 여기서 67 및 90은 오른쪽 하위 트리에 있고 15는 , 22 및 34는 왼쪽 하위 트리에 있습니다. 마찬가지로 나머지 이진 트리를 완성할 수 있습니다. 마지막으로 이진 트리는 다음과 같습니다.
40 / 22 67 / \ 15 34 90
이 이진 트리에는 BST 속성이 있으며 코드가 제대로 작동하고 있음을 보여줍니다. 마찬가지로 40을 삭제한 후 이진 트리를 구성할 수 있습니다.
67 / 22 90 / 15 34
노드 40은 왼쪽 및 오른쪽 자식 노드가 모두 있는 대상 노드입니다. 67에는 왼쪽 하위 트리가 없기 때문에 67인 오른쪽 하위 트리에서 가장 왼쪽을 선택했습니다. 따라서 대상 노드에서 67 값을 복사하고 delete 기능을 다시 호출하여 루트의 오른쪽 하위 트리에서 67을 삭제했습니다.
이제 67에 유일하게 올바른 자식인 90이 있는 경우가 있습니다. 따라서 90을 67로 대체합니다. 결과적으로 90은 67의 오른쪽 자식이 됩니다.
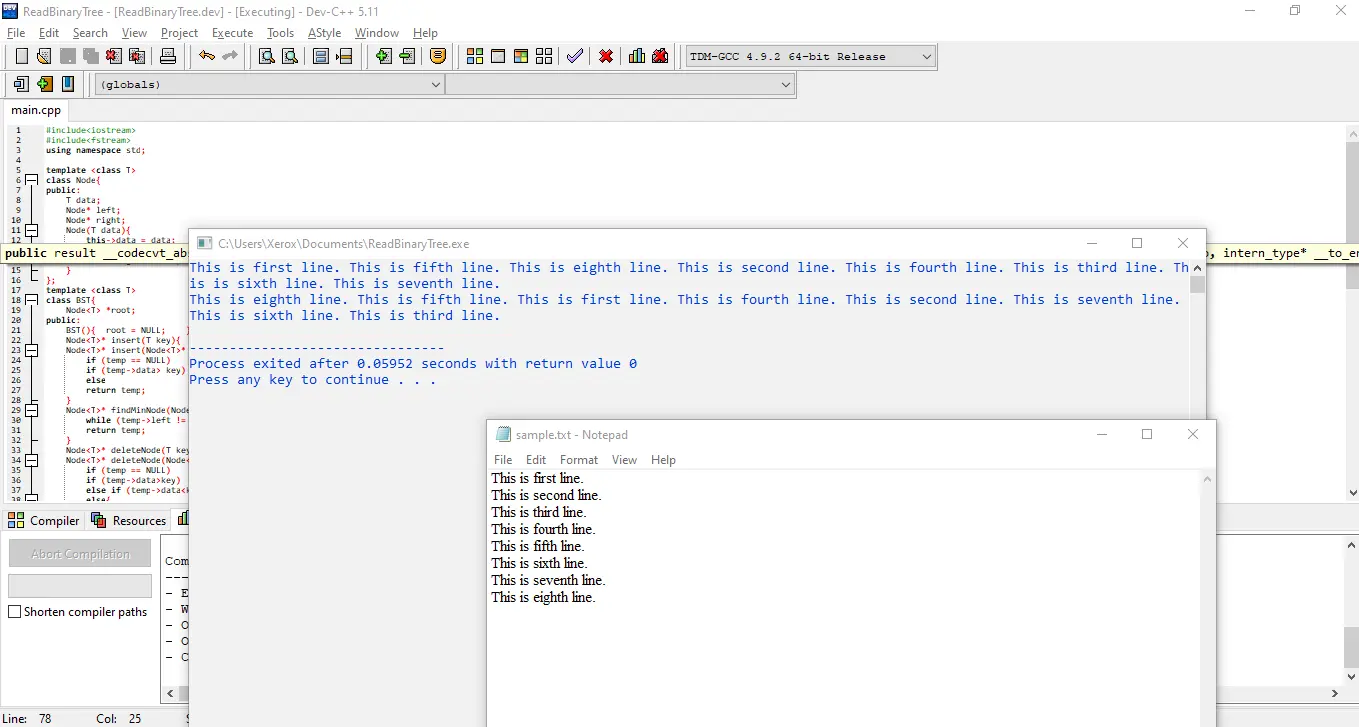
C++에서 이진 검색 트리로 파일 읽기
마지막으로 이제 파일을 BST로 읽는 방법에 대해 논의할 수 있습니다. 다시 한 번 차근차근 해보겠습니다.
먼저 다음 파일을 고려하십시오.
This is first line.
This is second line.
This is third line.
This is fourth line.
This is fifth line.
This is sixth line.
This is seventh line.
This is eighth line.
getline 기능을 사용하여 C++에서 이 파일을 쉽게 읽을 수 있습니다. 코드를 참조하십시오:
#include <fstream>
#include <iostream>
using namespace std;
int main() {
ifstream in("sample.txt");
string s;
while (getline(in, s)) cout << s << '\n';
in.close();
}
이전 상자의 파일 내용에서 볼 수 있는 것과 동일한 출력이 표시됩니다. 그러나 우리의 목표는 더 빠른 검색을 할 수 있도록 텍스트를 BST에 배치하는 것입니다.
간단합니다. 우리는 이미 클래스 템플릿에 BST를 구현했으며 문자열에도 사용할 수 있습니다. 그에 따라 BST의 객체를 생성하기만 하면 됩니다.
sample.txt 파일에 내용을 저장하여 코드를 통해 파일을 읽을 수 있습니다. 여기에 파일을 이진 검색 트리로 읽어들이는 코드가 있습니다.
#include <fstream>
#include <iostream>
using namespace std;
template <class T>
class Node {
public:
T data;
Node* left;
Node* right;
Node(T data) {
this->data = data;
this->left = NULL;
this->right = NULL;
}
};
template <class T>
class BST {
Node<T>* root;
public:
BST() { root = NULL; }
Node<T>* insert(T key) { root = insert(root, key); }
Node<T>* insert(Node<T>* temp, T key) {
if (temp == NULL) return new Node<T>(key);
if (temp->data > key)
temp->left = insert(temp->left, key);
else
temp->right = insert(temp->right, key);
return temp;
}
Node<T>* findMinNode(Node<T>* temp) {
while (temp->left != NULL) temp = temp->left;
return temp;
}
Node<T>* deleteNode(T key) { root = deleteNode(root, key); }
Node<T>* deleteNode(Node<T>* temp, T key) {
if (temp == NULL) return temp;
if (temp->data > key)
temp->left = deleteNode(temp->left, key);
else if (temp->data < key)
temp->right = deleteNode(temp->right, key);
else {
if (temp->left == NULL && temp->right == NULL) {
delete temp;
temp = NULL;
} else if (temp->left == NULL) {
Node<T>* curr = temp;
temp = temp->right;
delete curr;
} else if (temp->right == NULL) {
Node<T>* curr = temp;
temp = temp->left;
delete curr;
} else {
Node<T>* toBeDeleted = findMinNode(temp->right);
temp->data = toBeDeleted->data;
temp->right = deleteNode(temp->right, toBeDeleted->data);
}
}
return temp;
}
void preOrder() {
preOrder(root);
cout << '\n';
}
void preOrder(Node<T>* temp) {
if (temp == NULL) return;
cout << temp->data << " ";
preOrder(temp->left);
preOrder(temp->right);
}
void inOrder() {
inOrder(root);
cout << '\n';
}
void inOrder(Node<T>* temp) {
if (temp == NULL) return;
inOrder(temp->left);
cout << temp->data << " ";
inOrder(temp->right);
}
};
int main() {
BST<string> tree;
ifstream in("sample.txt");
string s;
while (getline(in, s)) tree.insert(s);
tree.preOrder();
tree.inOrder();
in.close();
return 0;
}
출력:
다시, 먼저 루트 노드가 This is the first line임을 보여주는 선주문 순회가 있습니다. 그러나 순서 순회가 표시되면 출력이 정렬된 순서로 표시됩니다.
즉, e부터 시작하는 eight는 first, second, third, fourth, fifth, sixth, seventh, eighth 중에서 가장 작은 문자입니다. 다음으로 fifth의 f가 first의 r보다 작기 때문에 first보다 작은 fifth가 있습니다.