SciPy scipy.stats.multivariate_normal
Das Python-Scipy-Objekt scipy.stats.multivariate_normal wird verwendet, um die multivariate Normalverteilung zu analysieren und verschiedene Parameter in Bezug auf die Verteilung mit den verschiedenen verfügbaren Methoden zu berechnen.
Syntax zur Berechnung der Wahrscheinlichkeitsdichtefunktion mit dem Objekt scipy.stats.multivariate_normal
scipy.stats.multivariate_normal.pdf(x, mean=None, cov=1, allow_singular=False)
Parameter:
x |
Werte, deren pdf ermittelt werden soll. Die zweite Dimension dieser Variablen repräsentiert die Komponenten des Datensatzes. |
mean |
Array-ähnliches Element, das den Mittelwert der Verteilung darstellt. Jeder Wert des Arrays repräsentiert den Wert für jede Komponente im Datensatz. Der Standardwert ist 0. |
cov |
Kovarianzmatrix der Daten. Der Standardwert ist 1. |
allow_singular |
Wenn auf True gesetzt, kann Singular cov erlaubt werden. Der Standardwert ist False |
Zurückkehren:
Eine Array-ähnliche Struktur, die Wahrscheinlichkeitswerte für jedes Element in x enthält.
Beispiel: Erstellen Sie eine Wahrscheinlichkeitsdichtefunktion mit der Methode scipy.stats.multivariate_normal.pdf
import numpy as np
from scipy.stats import multivariate_normal
mean = np.array([0.4, 0.8])
cov = np.array([[0.1, 0.3], [0.3, 1.0]])
x = np.random.uniform(size=(5, 2))
y = multivariate_normal.pdf(x, mean=mean, cov=cov)
print("Tha data and corresponding pdfs are:")
print("Data-------PDF value")
for i in range(len(x)):
print(x[i], end=" ")
print("------->", end=" ")
print(y[i], end="\n")
Ausgabe:
Tha data and corresponding pdfs are:
Data-------PDF value
[0.60156002 0.53917659] -------> 0.030687330659191728
[0.60307471 0.25205368] -------> 0.0016016741361277501
[0.27254519 0.06817383] -------> 0.7968146411119688
[0.33630808 0.21039553] -------> 0.7048988855032084
[0.0009666 0.52414497] -------> 0.010307396714783708
Im obigen Beispiel stellt x das Array von Werten dar, dessen pdf gefunden werden soll. Die Zeilen stellen jeden Wert von x dar, dessen pdf gefunden werden soll, und die Spalten stellen die Anzahl der Komponenten dar, die verwendet werden, um jeden Wert darzustellen.
Hier besteht jeder Wert von x aus zwei Komponenten und ist somit ein Vektor der Länge 2. Der Mittelwert ist ein Vektor mit einer Länge gleich der Anzahl der Komponenten. Wenn d die Anzahl der Komponenten im Datensatz ist, ist cov eine symmetrische quadratische Matrix der Größe d*d.
Die Methode scipy.stats.multivariate_normal.pdf nimmt die Eingabe x, mean und die Kovarianzmatrix cov und gibt einen Vektor mit einer Länge gleich der Anzahl der Zeilen in x aus, wobei jeder Wert in der Ausgabe ist Der Vektor repräsentiert den pdf-Wert für jede Zeile in x.
Beispiel: Ziehen Sie Zufallsstichproben aus einer multivariaten Normalverteilung mit der Methode scipy.stats.multivariate_normal.rvs
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import multivariate_normal
mean = np.array([0.4, 0.8])
cov = np.array([[0.1, 0.3], [0.3, 1.0]])
x = multivariate_normal.rvs(mean, cov, 100)
plt.scatter(x[:, 0], x[:, 1])
plt.show()
Ausgabe:
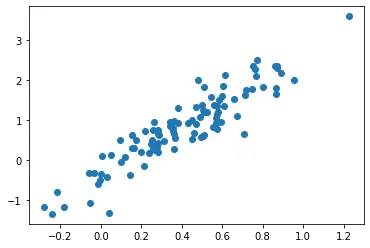
Das obige Diagramm stellt das Streudiagramm von 20 Zufallsstichproben dar, die zufällig aus einer multivariaten Normalverteilung mit zwei Merkmalen gezogen wurden. Die Verteilung hat einen Mittelwert von [0.4,0.8], wobei 0.4 den Mittelwert des ersten Merkmals und 0.8 den Mittelwert des zweiten Merkmals darstellt. Wir zeichnen schließlich das Streudiagramm der Stichproben mit dem ersten Merkmal entlang der X-Achse und dem zweiten Merkmal entlang der Y-Achse.
Aus dem Diagramm geht hervor, dass die meisten Stichprobenpunkte um [0.4,0.8] zentriert sind, was den Mittelwert der multivariaten Verteilung darstellt.
Beispiel: Holen Sie sich die kumulative Verteilungsfunktion mit der Methode scipy.stats.multivariate_normal.cdf
Cumulative distribution function (CDF) ist das Integral von pdf. CDF zeigt uns, dass jeder aus der Grundgesamtheit entnommene Wert einen Wahrscheinlichkeitswert kleiner oder gleich einem bestimmten Wert haben wird. Wir können cdf von Punkten der multivariaten Verteilung mit der Methode scipy.stats.multivariate_normal.cdf berechnen.
import numpy as np
from scipy.stats import multivariate_normal
mean = np.array([0.4, 0.8])
cov = np.array([[0.1, 0.3], [0.3, 1.0]])
x = np.random.uniform(size=(5, 2))
y = multivariate_normal.cdf(x, mean=mean, cov=cov)
print("Tha data and corresponding cdfs are:")
print("Data-------CDF value")
for i in range(len(x)):
print(x[i], end=" ")
print("------->", end=" ")
print(y[i], end="\n")
Ausgabe:
Tha data and corresponding cdfs are:
Data-------CDF value
[0.89027577 0.06036432] -------> 0.22976054289355996
[0.78164237 0.09611703] -------> 0.24075282906929418
[0.53051197 0.63041372] -------> 0.4309184323329717
[0.15571201 0.97173575] -------> 0.21985053519541042
[0.72988545 0.22477096] -------> 0.28256819625802715
Im obigen Beispiel stellt x das Array von Punkten dar, an denen cdf zu finden ist. Die Zeilen stellen jeden Wert von x dar, bei dem cdf zu finden ist, und die Spalten stellen die Anzahl der Komponenten dar, die verwendet werden, um jeden Wert darzustellen.
Hier besteht jeder Wert von x aus zwei Komponenten und ist somit ein Vektor der Länge 2. Der Mittelwert ist ein Vektor mit einer Länge gleich der Anzahl der Komponenten. Wenn d die Anzahl der Komponenten im Datensatz ist, ist cov eine symmetrische quadratische Matrix der Größe d*d.
Die Methode scipy.stats.multivariate_normal.cdf nimmt die Eingabe x, mean und die Kovarianzmatrix cov und gibt einen Vektor mit einer Länge gleich der Anzahl der Zeilen in x aus, wobei jeder Wert in der Ausgabe ist Der Vektor repräsentiert den cdf-Wert für jede Zeile in x.

Suraj Joshi is a backend software engineer at Matrice.ai.
LinkedIn