SciPy scipy.stats.multivariante_normal
El objeto Python Scipy scipy.stats.multivariate_normal se utiliza para analizar la distribución normal multivariante y calcular diferentes parámetros relacionados con la distribución utilizando los diferentes métodos disponibles.
Sintaxis para gemerar la función de densidad de probabilidad usando el objeto scipy.stats.multivariate_normal
scipy.stats.multivariate_normal.pdf(x, mean=None, cov=1, allow_singular=False)
Parámetros:
x |
Valores cuyo pdf se quiere determinar. La segunda dimensión de esta variable representa los componentes del conjunto de datos. |
mean |
Elemento tipo matriz que representa la media de la distribución. Cada valor de la matriz representa el valor de cada componente en el conjunto de datos. El valor por defecto es 0. |
cov |
Matriz de covarianza de los datos. El valor por defecto es 1. |
allow_singular |
Si se establece en True, se puede permitir el singular cov. El valor por defecto es False |
Regreso:
Una estructura similar a una matriz que contiene el valor de probabilidad para cada elemento en x.
Ejemplo: generar la función de densidad de probabilidad utilizando el método scipy.stats.multivariate_normal.pdf
import numpy as np
from scipy.stats import multivariate_normal
mean = np.array([0.4, 0.8])
cov = np.array([[0.1, 0.3], [0.3, 1.0]])
x = np.random.uniform(size=(5, 2))
y = multivariate_normal.pdf(x, mean=mean, cov=cov)
print("Tha data and corresponding pdfs are:")
print("Data-------PDF value")
for i in range(len(x)):
print(x[i], end=" ")
print("------->", end=" ")
print(y[i], end="\n")
Producción:
Tha data and corresponding pdfs are:
Data-------PDF value
[0.60156002 0.53917659] -------> 0.030687330659191728
[0.60307471 0.25205368] -------> 0.0016016741361277501
[0.27254519 0.06817383] -------> 0.7968146411119688
[0.33630808 0.21039553] -------> 0.7048988855032084
[0.0009666 0.52414497] -------> 0.010307396714783708
En el ejemplo anterior, x representa la matriz de valores cuyo pdf se encuentra. Las filas representan cada valor de x cuyo pdf se quiere encontrar, y las columnas representan el número de componentes utilizados para representar cada valor.
Aquí, cada valor de x consta de dos componentes y, por lo tanto, es un vector de longitud 2. La media será un vector de longitud igual al número de componentes. De manera similar, si d es el número de componentes en el conjunto de datos, cov será una matriz cuadrada simétrica de tamaño d*d.
El método scipy.stats.multivariate_normal.pdf toma la entrada x, media y la matriz de covarianza cov y genera un vector con una longitud igual al número de filas en x donde cada valor en la salida vector representa el valor pdf para cada fila en x.
Ejemplo: Extraiga muestras aleatorias de una distribución normal multivariante utilizando el método scipy.stats.multivariate_normal.rvs
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import multivariate_normal
mean = np.array([0.4, 0.8])
cov = np.array([[0.1, 0.3], [0.3, 1.0]])
x = multivariate_normal.rvs(mean, cov, 100)
plt.scatter(x[:, 0], x[:, 1])
plt.show()
Producción:
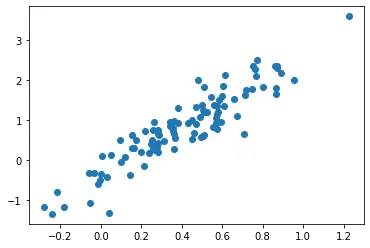
El diagrama anterior representa el diagrama de dispersión de 20 muestras aleatorias extraídas al azar de una distribución normal multivariada con dos características. La distribución tiene un valor medio de [0.4,0.8] donde 0.4 representa el valor medio de la primera característica y 0.8 la media de la segunda característica. Finalmente dibujamos el diagrama de dispersión de muestras aleatorias con la primera característica a lo largo del eje X y la segunda característica a lo largo del eje Y.
De la gráfica, está claro que la mayoría de los puntos de muestra se centran alrededor de [0.4,0.8], que representa la media de la distribución multivariada.
Ejemplo: obtener la función de distribución acumulativa utilizando el método scipy.stats.multivariate_normal.cdf
La función de distribución acumulativa (CDF) es la integral de pdf. CDF nos muestra que cualquier valor tomado de la población tendrá un valor de probabilidad menor o igual a algún valor. Podemos calcular cdf de puntos de distribución multivariante usando el método scipy.stats.multivariate_normal.cdf.
import numpy as np
from scipy.stats import multivariate_normal
mean = np.array([0.4, 0.8])
cov = np.array([[0.1, 0.3], [0.3, 1.0]])
x = np.random.uniform(size=(5, 2))
y = multivariate_normal.cdf(x, mean=mean, cov=cov)
print("Tha data and corresponding cdfs are:")
print("Data-------CDF value")
for i in range(len(x)):
print(x[i], end=" ")
print("------->", end=" ")
print(y[i], end="\n")
Producción:
Tha data and corresponding cdfs are:
Data-------CDF value
[0.89027577 0.06036432] -------> 0.22976054289355996
[0.78164237 0.09611703] -------> 0.24075282906929418
[0.53051197 0.63041372] -------> 0.4309184323329717
[0.15571201 0.97173575] -------> 0.21985053519541042
[0.72988545 0.22477096] -------> 0.28256819625802715
En el ejemplo anterior, x representa la matriz de puntos en los que se encuentra cdf. Las filas representan cada valor de x en el que se encuentra cdf, y las columnas representan el número de componentes utilizados para representar cada valor.
Aquí, cada valor de x consta de dos componentes y, por lo tanto, es un vector de longitud 2. La media será un vector de longitud igual al número de componentes. De manera similar, si d es el número de componentes en el conjunto de datos, cov será una matriz cuadrada simétrica de tamaño d*d.
El método scipy.stats.multivariate_normal.cdf toma la entrada x, mean y la matriz de covarianza cov y genera un vector con una longitud igual al número de filas en x donde cada valor en la salida El vector representa el valor cdf para cada fila en x.

Suraj Joshi is a backend software engineer at Matrice.ai.
LinkedIn