在 Pandas DataFrame 中規範化一列
- Pandas 中的資料歸一化
-
用
mean歸一化來歸納 Pandas DataFrame -
用
最小-最大歸一化方法對 Pandas DataFrame 進行歸一化 -
使用
分位數歸一化對 Pandas DataFrame 進行歸一化

資料的標準化或歸一化是特徵工程的第一步。列的歸一化將涉及到把列的值帶到一個共同的尺度,主要是針對範圍不同的列進行的。在 Pandas 中,可以通過各種函式對 Dataframes 的列進行歸一化。本文將幫助你練習這些函式,並幫助你在正確的情況下應用這些函式。
Pandas 中的資料歸一化
有兩種最廣泛使用的資料歸一化方法。
- 平均值歸一化
- 最小-最大歸一化
- 量子化標準化
在 Pandas 中並沒有任何特定的方法來執行資料歸一化。我們將解釋這些歸一化是什麼,以及如何使用原生 Pandas 和一點原生 python 函式來實現它。
我們將在各個地方使用下面的程式碼段來建立一個帶有隨機元素的 DataFrame,如下圖所示,它將返回一個類似的 DataFrame。
import pandas as pd
import numpy as np
np.random.seed(0)
df = pd.DataFrame(np.random.randint(-100, 100, size=(20, 4)), columns=list("ABCD"))
print(df)
它將返回一個類似的 DataFrame,如下所示。
A B C D
0 72 -53 17 92
1 -33 95 3 -91
2 -79 -64 -13 -30
3 -12 40 -42 93
4 -61 -13 74 -12
5 -19 65 -75 -23
6 -28 -91 48 15
7 97 -21 75 92
8 -18 -1 77 -71
9 47 47 42 67
10 -68 93 -91 85
11 27 -68 -69 51
12 63 14 83 -72
13 -66 28 28 64
14 -47 33 -62 -83
15 -21 32 5 -58
16 86 -69 20 -99
17 -35 69 -43 -65
18 2 19 -89 74
19 -18 -9 28 42
[20 rows x 4 columns]
用 mean 歸一化來歸納 Pandas DataFrame
“均值 “歸一化是對不同範圍的 DataFrame 進行歸一化的最簡單方法之一。歸一化是通過減去 DataFrame 所有元素的平均值併除以標準差來完成的。
import pandas as pd
import numpy as np
np.random.seed(0)
df = pd.DataFrame(np.random.randint(-100, 100, size=(20, 4)), columns=list("ABCD"))
def mean_norm(df_input):
return df_input.apply(lambda x: (x - x.mean()) / x.std(), axis=0)
df_mean_norm = mean_norm(df)
print(df_mean_norm)
輸出:
A B C D
0 1.452954 -1.090261 0.278088 1.247208
1 -0.514295 1.585670 0.037765 -1.333223
2 -1.376137 -1.289148 -0.236890 -0.473079
3 -0.120845 0.591236 -0.734701 1.261309
4 -1.038895 -0.367037 1.256545 -0.219266
5 -0.251995 1.043252 -1.301176 -0.374374
6 -0.420617 -1.777325 0.810231 0.161453
7 1.921346 -0.511681 1.273711 1.247208
8 -0.233260 -0.150069 1.308043 -1.051208
9 0.984561 0.717801 0.707236 0.894690
10 -1.170045 1.549509 -1.575831 1.148503
11 0.609847 -1.361470 -1.198181 0.669079
12 1.284333 0.121140 1.411038 -1.065309
13 -1.132573 0.374269 0.466913 0.852388
14 -0.776595 0.464672 -1.078020 -1.220417
15 -0.289467 0.446591 0.072097 -0.867899
16 1.715254 -1.379551 0.329586 -1.446028
17 -0.551766 1.115574 -0.751867 -0.966604
18 0.141455 0.211543 -1.541499 0.993395
19 -0.233260 -0.294714 0.466913 0.542172
如果你使用的是 Jupyter 筆記本,可以使用 Matplotlib 對兩個 DataFrame 進行視覺化,如下圖所示。
# %matplotlib inline
df["A"].plot(kind="bar")
通過選擇歸一化前的 DataFrame 的 A 列,並將其視覺化為一個條形圖,注意到 y 軸包含-100 到 100 的範圍內的值。
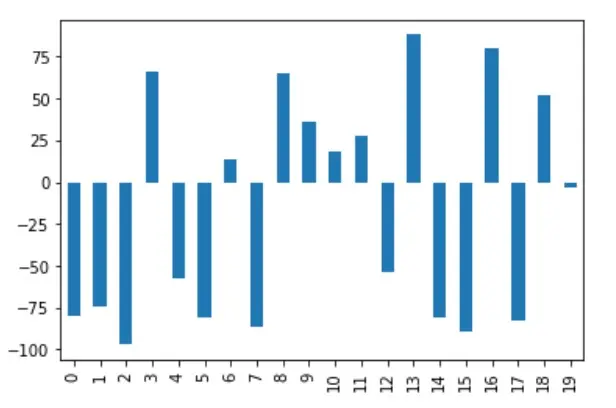
# %matplotlib inline
df_mean_norm["A"].plot(kind="bar")
下圖顯示了歸一化後的資料;當同一列視覺化時,y 軸位於-1.5 至+1.5 的範圍內。
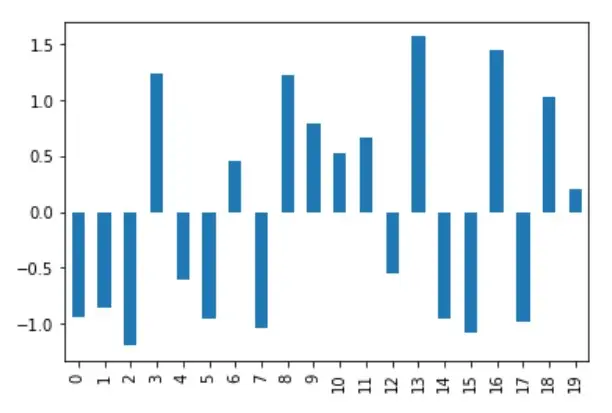
用 最小-最大 歸一化方法對 Pandas DataFrame 進行歸一化
這是廣泛使用的歸一化方法之一。歸一化輸出減去 DataFrame 的最小值,然後除以相應列的最高值和最低值之差。
import pandas as pd
import numpy as np
np.random.seed(0)
df = pd.DataFrame(np.random.randint(-100, 100, size=(20, 4)), columns=list("ABCD"))
def minmax_norm(df_input):
return (df - df.min()) / (df.max() - df.min())
df_minmax_norm = minmax_norm(df)
print(df_minmax_norm)
輸出:
A B C D
0 0.857955 0.204301 0.620690 0.994792
1 0.261364 1.000000 0.540230 0.041667
2 0.000000 0.145161 0.448276 0.359375
3 0.380682 0.704301 0.281609 1.000000
4 0.102273 0.419355 0.948276 0.453125
5 0.340909 0.838710 0.091954 0.395833
6 0.289773 0.000000 0.798851 0.593750
7 1.000000 0.376344 0.954023 0.994792
8 0.346591 0.483871 0.965517 0.145833
9 0.715909 0.741935 0.764368 0.864583
10 0.062500 0.989247 0.000000 0.958333
11 0.602273 0.123656 0.126437 0.781250
12 0.806818 0.564516 1.000000 0.140625
13 0.073864 0.639785 0.683908 0.848958
14 0.181818 0.666667 0.166667 0.083333
15 0.329545 0.661290 0.551724 0.213542
16 0.937500 0.118280 0.637931 0.000000
17 0.250000 0.860215 0.275862 0.177083
18 0.460227 0.591398 0.011494 0.901042
19 0.346591 0.440860 0.683908 0.734375
在上面的輸出中,我們可以推斷出每一列的最小值被轉化為 0,每一列的最大值被轉化為 1。
歸一化後的列 A 是視覺化的,如下圖所示。
# %matplotlib inline
df_minmax_norm["A"].plot(kind="bar")
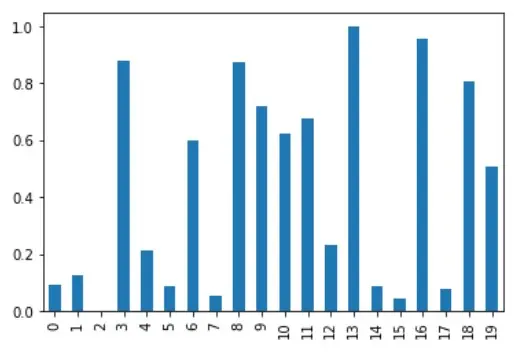
雖然這對近距離的 DataFrame 很有好處,但 MinMax 歸一化可能不適合有許多異常值的 DataFrame。
使用 分位數 歸一化對 Pandas DataFrame 進行歸一化
量子化歸一化用於高維資料分析。它觀察並假設每一列的統計分佈是相同的。分位數歸一化包括以下步驟。
- 對每列內的數值進行排序(Ranking); 2。
- 每行的平均值,用平均值代替行中每個元素的值。
- 將數值重新排序到最初的順序。
import numpy as np
import pandas as pd
np.random.seed(0)
df = pd.DataFrame(np.random.randint(-100, 100, size=(20, 4)), columns=list("ABCD"))
def quantile_norm(df_input):
sorted_df = pd.DataFrame(
np.sort(df_input.values, axis=0), index=df_input.index, columns=df_input.columns
)
mean_df = sorted_df.mean(axis=1)
mean_df.index = np.arange(1, len(mean_df) + 1)
quantile_df = df_input.rank(method="min").stack().astype(int).map(mean_df).unstack()
return quantile_df
df_quantile_norm = quantile_norm(df)
print(df_quantile_norm)
4.輸出。
A B C D
0 77.00 -58.25 8.25 77.00
1 -36.50 92.00 -10.50 -79.25
2 -90.00 -66.50 -20.00 -20.00
3 24.75 44.00 -36.50 92.00
4 -66.50 -36.50 71.75 -3.00
5 -3.00 71.75 -73.00 -10.50
6 -20.00 -90.00 54.00 8.25
7 92.00 -41.00 77.00 77.00
8 8.25 -10.50 87.00 -58.25
9 54.00 54.00 44.00 44.00
10 -79.25 87.00 -90.00 71.75
11 44.00 -73.00 -66.50 24.75
12 71.75 -3.00 92.00 -66.50
13 -73.00 18.00 24.75 31.75
14 -58.25 31.75 -58.25 -73.00
15 -10.50 24.75 -3.00 -36.50
16 87.00 -79.25 18.00 -90.00
17 -41.00 77.00 -41.00 -41.00
18 31.75 8.25 -79.25 54.00
19 8.25 -20.00 24.75 18.00
量子化歸一化的輸出可以直觀地顯示在 A 列上,如下圖所示。
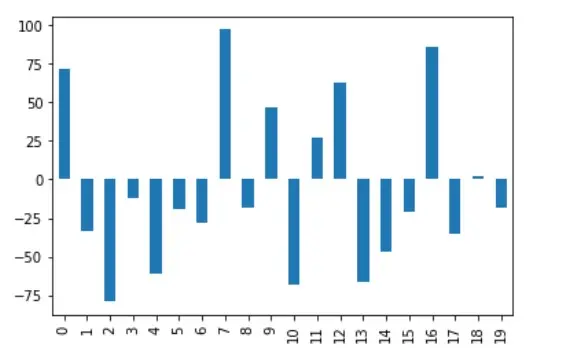
相關文章 - Pandas DataFrame
- 如何將 Pandas DataFrame 列標題獲取為列表
- 如何刪除 Pandas DataFrame 列
- 如何在 Pandas 中將 DataFrame 列轉換為日期時間
- 如何在 Pandas DataFrame 中將浮點數轉換為整數
- 如何按一列的值對 Pandas DataFrame 進行排序
- 如何用 group-by 和 sum 獲得 Pandas 總和