SciPy 정규 분포 확률 계산
이 기사에서는 SciPy 정규 분포에 대해 설명합니다. SciPy를 사용하여 정규 분포의 확률을 계산합니다.
정규 분포
먼저 정규분포에 대해 알아보자.
정규 분포는 실제 값을 갖는 무작위 변수에 대한 연속 확률 분포입니다. 평균과 표준 편차를 사용하여 계산됩니다.
PDF라고도 하는 확률 밀도 함수는 분포에서 단일 지점의 우도를 계산합니다. PDF는 다음 공식을 사용하여 계산됩니다.
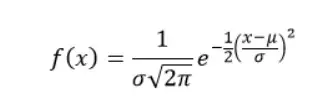
여기서 μ는 평균이고 σ는 분포의 표준 편차입니다.
SciPy를 사용하여 정규 분포 확률 계산
특정 분포의 확률 밀도 함수를 계산하기 위해 scipy.stats.norm.pdf() 메서드 중 하나를 사용합니다.
scipy.stats.norm.pdf() 구문은 다음과 같습니다.
scipy.stats.norm.pdf(data, loc, scale)
여기서 data는 배열 데이터의 형태로 동일하게 샘플링된 데이터를 나타내는 포인트 또는 값의 모음이고 loc은 샘플 데이터(평균)의 위치이며 scale은 표준 편차의 샘플입니다.
아래 방법을 사용하여 특정 분포의 pdf를 계산하는 방법을 살펴보겠습니다.
먼저 다음과 같이 필요한 라이브러리를 가져옵니다.

그런 다음 난수를 얻기 위해 배열을 만듭니다. 여기에서 -10에서 10 사이의 차이가 0.3인 배열을 만들고 개체 x_arr.에 저장했습니다.

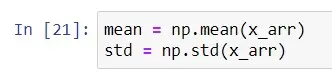
주어진 무작위 데이터를 사용하여 평균과 표준편차 값을 구해봅시다.
이제 loc=mean 및 scale=std.와 함께 norm 방법을 사용하여 pdf 값을 계산합니다.

여기서 5는 확률을 계산할 배열과 같은 객체입니다.
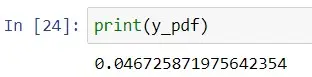
계산된 pdf 값 인쇄:
전체 코드 스크린샷은 다음과 같습니다.
이렇게 하면 평균 및 표준 편차 값을 사용하여 SciPy 라이브러리를 사용하여 정규 분포의 확률을 계산할 수 있습니다.

Shiv is a self-driven and passionate Machine learning Learner who is innovative in application design, development, testing, and deployment and provides program requirements into sustainable advanced technical solutions through JavaScript, Python, and other programs for continuous improvement of AI technologies.
LinkedIn