팬더 패밀리 트리 소개

이 튜토리얼에서는 트리 데이터 구조와 유형을 소개하고 Python에서 가계도(계층적 트리/일반 트리라고도 함) 구현에 대해 자세히 설명합니다.
트리 데이터 구조와 그 중요성
컴퓨터 과학에서 나무는 뿌리, 가지, 잎이 있는 실제 나무에서 영감을 받았습니다. 유일한 차이점은 루트가 트리의 맨 위에 있는 트리 데이터 구조가 거꾸로 시각화된다는 것입니다. 아래에 시각적으로 표현해 보겠습니다.
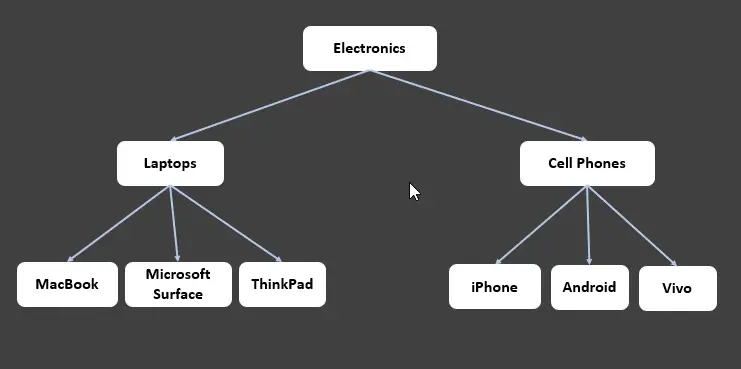
위의 트리에서 모든 엔터티는 노드로 알려져 있습니다. Electronics 노드는 root 노드입니다. 여기에는 두 개의 자식 노드 노트북과 휴대폰이 있으며 각 자식 노드는 리프 노드(자식이 없는 노드)의 부모입니다.
각 화살표는 두 개의 노드를 연결하는 모서리입니다. 우리는 이것을 다음과 같이 시각화할 수 있습니다.
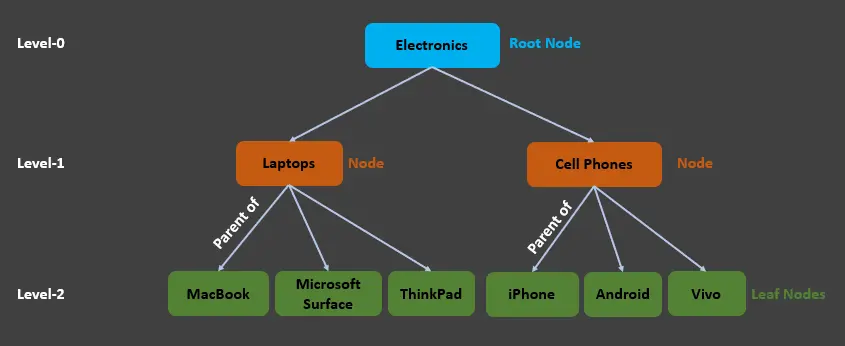
Level-0에는 전자 제품인 루트 노드가 있고 레벨 1에는 노트북과 휴대폰이라는 두 개의 노드가 있음을 알 수 있습니다.
노트북은전자 제품의 하위 노드이자 리프 노드(MacBook,Microsoft Surface,ThinkPad)의 상위 노드입니다.Cell Phones는Electronics의 하위 노드이자 리프 노드(iPhone,Android,Vivo)의 상위 노드입니다.
전자 제품과 휴대 전화는 아이폰의 조상이라고 할 수 있습니다. 마찬가지로 Cell Phones 및 iPhone은 Electronics 노드의 자손입니다. 같은 경우가 노트북에 적용됩니다.
자식-부모 계층으로 인해 계층적 데이터 구조라고도 합니다. 예를 들어 파일 시스템과 같이 문제를 단순화하고 속도를 높이며 검색 및 정렬이 필요한 곳에서 널리 사용됩니다.
비선형 데이터 구조를 나타내야 하는 경우 트리를 사용합니다. 트리 데이터 구조를 사용하려면 각 트리에 특정 루트 노드가 있고 각 자식 노드에 부모가 있는 반면 부모에는 많은 자식이 있을 수 있다는 속성을 충족해야 합니다.
트리 데이터 구조마다 이 속성을 만족해야 하지만, 트리 데이터 구조마다 다른 추가 속성이 있다.
트리 데이터 구조의 유형에는 여기에서 찾을 수 있는 General Tree, Binary Tree, Binary Search Tree(BST), Adelson-Velshi and Landis(AVL) Tree, Red-Black Tree 및 N-ary Tree가 있습니다. 튜토리얼에서는 일반 트리에만 초점을 맞춥니다.
판다 가계도
조상에 대한 정보를 저장한 아래 표가 있습니다. 자녀에 대한 제약이 없어야 합니다. 각 노드에는 무한한 수의 자식 노드가 있을 수 있습니다.
그래서 우리는 가계도를 구현하기 위해 일반 가계도를 사용하고 있습니다.
일반 트리에서는 트리의 계층 구조에 대한 제한이 없으며 모든 노드는 무제한의 자식 노드를 가질 수 있습니다. 일반 트리는 다른 모든 트리 데이터 구조의 상위 집합입니다.
조상 정보 테이블:
id |
gender |
first_name |
last_name |
dob |
dod |
fid |
mid |
birth_place |
job |
|---|---|---|---|---|---|---|---|---|---|
AnAn |
중 | 안토니오 | 안돌리니 | 1901년 | 콜레오네 | ||||
SiAn |
에프 | 시뇨라 | 안돌리니 | 1901년 | 콜레오네 | 주부 | |||
PaAn87 |
중 | 파올로 | 안돌리니 | 1887년 | 1901년 | AnAn |
SiAn |
||
ViCo92 |
중 | 비토 | 콜레오네 | 1892년 | 1954년 | AnAn |
SiAn |
콜레오네 | 대부 |
CaCo97 |
에프 | 카멜라 | 콜레오네 | 1897년 | 1959년 | ||||
ToHa10 |
중 | 톰 | 하겐 | 1910년 | 1970년 | ViCo92 |
CaCo97 |
뉴욕 | consigliere |
SaCo16 |
중 | 산티노 | 콜레오네 | 1916년 | 1948년 | ViCo92 |
CaCo97 |
뉴욕 | 갱 단원 |
SaCo17 |
에프 | 산드라 | 콜롬보 | 1917년 | 메시나 | ||||
FrCo19 |
중 | 프레데리코 | 콜레오네 | 1919년 | 1959년 | ViCo92 |
CaCo97 |
뉴욕 | 카지노 매니저 |
MiCo20 |
중 | 남자 이름 | 콜레오네 | 1920년 | 1997년 | ViCo92 |
CaCo97 |
뉴욕 | 대부 |
ThHa20 |
에프 | 거기에 | 하겐 | 1920년 | 뉴저지 | 예술 전문가 | |||
LuMa23 |
에프 | 루시 | 만치니 | 1923년 | 호텔 직원 | ||||
KaAd24 |
에프 | 케이 | 아담스 | 1934년 | |||||
FrCo37 |
에프 | 프란체사 | 콜레오네 | 1937년 | SaCo16 |
SaCo17 |
|||
KaCo37 |
에프 | 캐서린 | 콜레오네 | 1937년 | SaCo16 |
SaCo17 |
|||
FrCo40 |
에프 | 솔직한 | 콜레오네 | 1940년 | SaCo16 |
SaCo17 |
|||
SaCo45 |
중 | 산티노 주니어 | 콜레오네 | 1945년 | SaCo16 |
SaCo17 |
|||
FrHa |
중 | 솔직한 | 하겐 | 1940년 | ToHa10 |
Th20 |
|||
AnHa42 |
중 | 앤드류 | 하겐 | 1942년 | ToHa10 |
Th20 |
성직자 | ||
ViMa |
중 | 빈센트 | 만치니 | 1948년 | SaCo16 |
LuMa23 |
뉴욕 | 대부 | |
GiHa58 |
에프 | 지아나 | 하겐 | 1948년 | ToHa10 |
Th20 |
|||
AnCo51 |
중 | 앤서니 | 콜레오네 | 1951년 | MiCo20 |
KaAd24 |
뉴욕 | 가수 | |
MaCo53 |
에프 | 메리 | 콜레오네 | 1953년 | 1979년 | MiCo20 |
KaAd24 |
뉴욕 | 학생 |
ChHa54 |
에프 | 크리스티나 | 하겐 | 1954년 | ToHa10 |
Th20 |
|||
CoCo27 |
에프 | 콘스탄치아 | 콜레오네 | 1927년 | ViCo92 |
CaCo97 |
뉴욕 | 임차인 | |
CaRi20 |
중 | 카를로 | 리치 | 1920년 | 1955년 | 네바다 | 마권 업자 | ||
ViRi49 |
중 | 승리자 | 리치 | 1949년 | CaRi20 |
CoCo27 |
뉴욕 | ||
MiRi |
중 | 남자 이름 | 리치 | 1955년 | CaRi20 |
CoCo27 |
우리는 직접 비순환 그래프 (DAG)로 개인 간의 관계를 볼 수 있지만, 아래 주어진 단계에 따라 이 테이블을 가계도로 나타내기 위해 그래프 그리기를 사용할 것입니다.
{{ % step %}}
-
필요한 라이브러리 가져오기 및 데이터 읽기
import pandas as pd import numpy as np from graphviz import Digraph.csv파일에서 데이터를 읽기 위해pandas라이브러리를 가져오고 데이터 조작을 위해 데이터 프레임을 사용합니다. 그런 다음numpy및graphviz를 가져와 어레이 작업을 수행하고 각각 직접 비순환 그래프(DAG)를 생성합니다. -
데이터 읽기
rawdf = pd.read_csv("./data.csv", keep_default_na=False)read_csv()메서드는data.csv파일을 읽는 데 사용되는 반면keep_default_na=False는NaN대신 빈 셀을 갖는 데 사용됩니다. -
테이블을 Edge 목록으로 변환
다음으로 다음 코드를 통해 시작 정점이
id이고 끝 정점이ParentID인 가장자리 목록으로 테이블을 변환해야 합니다.두 개의 데이터 프레임 만들기:
```python
element1 = rawdf[["id", "mid"]]
element2 = rawdf[["id", "fid"]]
print(
"'element1' head data:\n",
element1.head(),
"\n\n",
"'element2' head data: \n",
element2.head(),
)
```
출력:
```text
'element1' head data:
id mid
0 AnAn
1 SiAn
2 PaAn87 SiAn
3 ViCo92 SiAn
4 CaCo97
'element2' head data:
id fid
0 AnAn
1 SiAn
2 PaAn87 AnAn
3 ViCo92 AnAn
4 CaCo97
```
여기서 `element1` 데이터 프레임에는 `id`와 `mid`라는 두 개의 열이 있는 반면 `element2` 데이터 프레임에는 `id`와 `fid가 있는 두 개의 새 데이터 프레임 `element1`과 `element2`를 만듭니다. ` 열로.
열 이름을 바꿉니다.
<!--adsense-->
```python
element1.columns = ["Child", "ParentID"]
element2.columns = element1.columns
print(
"'element1' data:\n",
element1.head(),
"\n\n",
"'element2' data: \n",
element2.head(),
)
```
출력:
```text
'element1' data:
Child ParentID
0 AnAn
1 SiAn
2 PaAn87 SiAn
3 ViCo92 SiAn
4 CaCo97
'element2' data:
Child ParentID
0 AnAn
1 SiAn
2 PaAn87 AnAn
3 ViCo92 AnAn
4 CaCo97
```
위의 코드 스니펫은 위의 출력과 같이 `element1` 및 `element2` 데이터 프레임의 열 이름을 `Child` 및 `ParentID`로 바꿉니다.
데이터 프레임을 연결하고 빈 셀을 `NaN`으로 교체:
```python
element = pd.concat([element1, element2])
element.replace("", np.nan, regex=True, inplace=True)
print(element.head())
```
출력:
```text
Child ParentID
0 AnAn NaN
1 SiAn NaN
2 PaAn87 SiAn
3 ViCo92 SiAn
4 CaCo97 NaN
```
`concat()` 메서드는 `element1` 및 `element2` 데이터 프레임을 연결하여 `element`라는 새 데이터 프레임을 만드는 데 사용되며 `replace()` 메서드는 빈 셀을 `NaN`으로 바꿉니다.
`ParentID`의 각 공백을 특정 문자열로 바꿉니다.
```python
t = pd.DataFrame({"tmp": ["no_entry" + str(i) for i in range(element.shape[0])]})
element["ParentID"].fillna(t["tmp"], inplace=True)
```
데이터 프레임 병합:
```python
df = element.merge(rawdf, left_index=True, right_index=True, how="left")
print(df.head())
```
출력:
```text
Child ParentID id gender first_name last_name dob dod fid \
0 AnAn no_entry0 AnAn M Antonio Andolini 1901
0 AnAn no_entry0 AnAn M Antonio Andolini 1901
1 SiAn no_entry1 SiAn F Signora Andolini 1901
1 SiAn no_entry1 SiAn F Signora Andolini 1901
2 PaAn87 SiAn PaAn87 M Paolo Andolini 1887 1901 AnAn
mid birth_place job
0 Corleone
0 Corleone
1 Corleone housewife
1 Corleone housewife
2 SiAn
```
여기에서 `merge()`를 사용하여 지정된 메서드를 사용하여 두 데이터 프레임의 데이터를 업데이트하여 병합합니다. 특정 매개변수를 사용하여 대체해야 하는 데이터 값과 유지해야 하는 데이터 값을 제어합니다.
이를 위해 아래에 간략하게 설명된 다음 매개변수를 사용하고 있습니다.
1. `rawdf` - 병합할 필수 데이터 프레임입니다.
2. `left_index` - 해당 값에 따라 왼쪽 데이터 프레임의 인덱스를 조인 키로 사용할지 여부를 결정할 수 있습니다.
`True`로 설정되어 있으면 사용할 수 있습니다. 그렇지 않으면 아닙니다. 기본적으로 해당 값은 `False`입니다.
3. `right_index` - `left_index`와 유사하지만 여기서는 오른쪽 데이터 프레임의 인덱스를 결합 키로 사용할 수 있는지 여부를 결정해야 합니다.
`True`로 설정되어 있으면 사용할 수 있습니다. 그렇지 않으면 아닙니다. 기본적으로 해당 값도 `False`입니다.
4. `방법` - `왼쪽`, `외부`, `오른쪽`, `교차` 또는 `내부`를 병합하는 방법을 나타냅니다. 기본적으로 해당 값은 `inner`입니다.
전체 이름이 있는 `이름` 열 만들기:
```python
df["name"] = df[df.columns[4:6]].apply(
lambda x: " ".join(x.dropna().astype(str)), axis=1
)
print(df.head())
```
출력:
```text
Child ParentID id gender first_name last_name dob dod fid \
0 AnAn no_entry0 AnAn M Antonio Andolini 1901
0 AnAn no_entry0 AnAn M Antonio Andolini 1901
1 SiAn no_entry1 SiAn F Signora Andolini 1901
1 SiAn no_entry1 SiAn F Signora Andolini 1901
2 PaAn87 SiAn PaAn87 M Paolo Andolini 1887 1901 AnAn
mid birth_place job name
0 Corleone Antonio Andolini
0 Corleone Antonio Andolini
1 Corleone housewife Signora Andolini
1 Corleone housewife Signora Andolini
2 SiAn Paolo Andolini
```
여기서는 `lambda` 표현식을 사용하여 각 행을 반복하고 `first_name`과 `last_name`을 조인합니다. 그런 다음 위의 출력에서 볼 수 있듯이 이 전체 이름을 `name`이라는 새 열에 배치합니다.
몇 개의 열을 삭제하고 `df` 데이터 프레임에서 열 순서 변경:
<!--adsense-->
```python
df = df.drop(["Child", "fid", "mid", "first_name", "last_name"], axis=1)
df = df[["id", "name", "gender", "dob", "dod", "birth_place", "job", "ParentID"]]
print(df.head())
```
출력:
```text
id name gender dob dod birth_place job ParentID
0 AnAn Antonio Andolini M 1901 Corleone no_entry0
0 AnAn Antonio Andolini M 1901 Corleone no_entry0
1 SiAn Signora Andolini F 1901 Corleone housewife no_entry1
1 SiAn Signora Andolini F 1901 Corleone housewife no_entry1
2 PaAn87 Paolo Andolini M 1887 1901 SiAn
```
먼저 `df` 데이터 프레임에서 `Child`, `fid`, `mid`, `first_name` 및 `last_name` 열을 삭제하고 결과 데이터 프레임에서 볼 수 있듯이 열 순서를 변경합니다.
-
직접 비순환 그래프(DAG) 생성
DAG를 생성하려면 시스템에
graphviz가 있어야 합니다.
```python
f = Digraph(
"neato",
format="pdf",
encoding="utf8",
filename="data",
node_attr={"color": "lightblue2", "style": "filled"},
)
f.attr("node", shape="box")
for index, record in df.iterrows():
f.edge(str(record["ParentID"]), str(record["id"]), label="")
f.view()
```
이 코드 조각은 `graphviz`의 `Digraph()` 클래스를 사용합니다. 이 클래스는 몇 가지 속성을 취하고 [DOT](https://www.graphviz.org/doc/info/lang.html) 언어로 방향성 그래프 설명을 생성하며 `.attr(로 연결된 `f` 변수에 이 참조를 저장합니다. )` 메서드를 사용하여 노드의 모양을 지정합니다.
마지막으로 `df` 데이터 프레임을 반복하여 에지를 생성하고 `f.view()`를 사용하여 그래프를 봅니다.
출력:

그래프에 다음과 같은 항목이 있다고 가정합니다.
1. 한 가지 색상은 여성용이고 다른 색상은 남성용입니다.
2. 이름을 ID로 대체
3. 가계도 화살처럼 생긴 화살
4. 예를 들어 `job`, `dob`, `dod` 등과 같이 각 상자(노드)에 더 많은 세부 정보를 추가합니다.
그렇게 하려면 다음 코드를 실행합니다.
```python
f = Digraph(
"neato",
format="jpg",
encoding="utf8",
filename="detailed_data",
node_attr={"style": "filled"},
graph_attr={"concentrate": "true", "splines": "ortho"},
)
f.attr("node", shape="box")
for index, row in df.iterrows():
f.node(
row["id"],
label=row["name"]
+ "\n"
+ row["job"]
+ "\n"
+ str(row["dob"])
+ "\n"
+ row["birth_place"]
+ "\n"
+ str(row["dod"]),
_attributes={
"color": "lightpink"
if row["gender"] == "F"
else "lightblue"
if row["gender"] == "M"
else "lightgray"
},
)
for index, row in df.iterrows():
f.edge(str(row["ParentID"]), str(row["id"]), label="")
f.view()
```
출력:

`graph_attr={"concentrate": "true", "splines": "ortho"})`를 사용하여 정확한 시작 및 종료 노드와 정사각형 모서리로 모서리를 그룹화합니다. `label=`은 그래프 노드의 `name`, `job`, `dob`, `birth_place` 및 `dod`를 표시하는 데 사용됩니다.
`_attributes={'color':'lightpink' if row['S']=='F' else 'lightblue' if row['S']=='M' else 'lightgray'}`는 다음을 정의하는 데 사용됩니다. `성별` 속성에 따라 각 노드의 색상. 아래에서 전체 소스 코드를 찾을 수 있습니다.
{{ % /step %}}
완전한 소스 코드:
import pandas as pd
import numpy as np
from graphviz import Digraph
rawdf = pd.read_csv("./data.csv", keep_default_na=False)
element1 = rawdf[["id", "mid"]]
element2 = rawdf[["id", "fid"]]
element1.columns = ["Child", "ParentID"]
element2.columns = element1.columns
element = pd.concat([element1, element2])
element.replace("", np.nan, regex=True, inplace=True)
t = pd.DataFrame({"tmp": ["no_entry" + str(i) for i in range(element.shape[0])]})
element["ParentID"].fillna(t["tmp"], inplace=True)
df = element.merge(rawdf, left_index=True, right_index=True, how="left")
df["name"] = df[df.columns[4:6]].apply(
lambda x: " ".join(x.dropna().astype(str)), axis=1
)
df = df.drop(["Child", "fid", "mid", "first_name", "last_name"], axis=1)
df = df[["id", "name", "gender", "dob", "dod", "birth_place", "job", "ParentID"]]
f = Digraph(
"neato",
format="pdf",
encoding="utf8",
filename="data",
node_attr={"color": "lightblue2", "style": "filled"},
)
f.attr("node", shape="box")
for index, record in df.iterrows():
f.edge(str(record["ParentID"]), str(record["id"]), label="")
f.view()
f = Digraph(
"neato",
format="jpg",
encoding="utf8",
filename="detailed_data",
node_attr={"style": "filled"},
graph_attr={"concentrate": "true", "splines": "ortho"},
)
f.attr("node", shape="box")
for index, row in df.iterrows():
f.node(
row["id"],
label=row["name"]
+ "\n"
+ row["job"]
+ "\n"
+ str(row["dob"])
+ "\n"
+ row["birth_place"]
+ "\n"
+ str(row["dod"]),
_attributes={
"color": "lightpink"
if row["gender"] == "F"
else "lightblue"
if row["gender"] == "M"
else "lightgray"
},
)
for index, row in df.iterrows():
f.edge(str(row["ParentID"]), str(row["id"]), label="")
f.view()
