Python Numpy.histogram() 함수
Minahil Noor
2023년1월30일
NumPy
-
numpy.histogram()의 구문 -
예제 코드:
numpy.histogram() -
예제 코드: bin의 수와 크기를 지정하는
numpy.histogram() -
예제 코드:
density매개 변수를 사용하는numpy.histogram() -
예제 코드: 히스토그램을 그리는
numpy.histogram()
Python NumPy numpy.histogram() 함수는 히스토그램의 값을 생성합니다. 히스토그램을 플로팅하지 않지만 값을 계산합니다. 배열을 매개 변수로 전달합니다. 이 함수는 히스토그램을 계산하고 히스토그램 값을 저장 한 배열을 반환합니다. 히스토그램의 숫자 표현을 반환한다고 말할 수 있습니다.
numpy.histogram()의 구문
numpy.histogram(a, bins=10, range=None, normed=None, weights=None, density=None)
매개 변수
a |
array_like 구조입니다. 히스토그램을 계산하기위한 입력 데이터를 나타냅니다. |
bins |
정수, 문자열 또는 스칼라 시퀀스입니다. ‘빈’의 수를 나타냅니다. bin은 0-5, 6-10 등과 같은 범위와 같습니다. bins가 정수이면 동일한 간격의 bins수를 나타냅니다. 문자열이면 빈 공간을 계산하는 방법을 나타냅니다. 시퀀스라면 폭이 다른 빈을 나타냅니다. |
range |
부동 소수점 숫자로 주어진 범위입니다. 그것은bins의 상한과 하한 범위를 나타냅니다. 범위가 지정되지 않으면[a.min(), a.max()]가 범위입니다. |
normed |
부울 매개 변수입니다. 그 기능은 density매개 변수와 비슷하지만 빈 간격이 같지 않으면 잘못된 결과가 생성됩니다. |
weights |
array_like 구조입니다. 크기는 a와 같습니다. ‘밀도’가 ‘참’이면 가중치가 정규화됩니다. |
density |
부울 매개 변수입니다. 값이 True이면 빈도를 계산하는 대신 확률을 계산합니다. |
반환
hist와bin_edges의 두 배열을 반환합니다. 배열 hist는 히스토그램의 값을 표시하고 bin_edges는 빈 가장자리를 표시합니다. bin_edges의 크기는 항상 1 + (hist 크기) 즉length(hist) + 1입니다.
예제 코드: numpy.histogram()
매개 변수 a는 필수 매개 변수입니다. 빈 수를 전달하지 않고이 함수를 실행하면 동일하지 않은 공간을 가진 10 개의 빈을 계산합니다.
import numpy as np
a = np.array(
[89, 34, 56, 87, 90, 23, 45, 12, 65, 78, 9, 34, 12, 11, 2, 65, 78, 82, 28, 78]
)
histogram = np.histogram(a)
print(histogram)
출력:
(
array([2, 3, 2, 2, 1, 0, 1, 2, 3, 4], dtype=int64),
array([2.0, 10.8, 19.6, 28.4, 37.2, 46.0, 54.8, 63.6, 72.4, 81.2, 90.0]),
)
예제 코드: bin의 수와 크기를 지정하는numpy.histogram()
먼저 빈 수를 지정합니다.
import numpy as np
a = np.array(
[89, 34, 56, 87, 90, 23, 45, 12, 65, 78, 9, 34, 12, 11, 2, 65, 78, 82, 28, 78]
)
histogram = np.histogram(a, bins=2)
print(histogram)
출력:
(array([10, 10], dtype=int64), array([ 2., 46., 90.]))
위의 코드는 빈이 2 개인 히스토그램을 계산했습니다. 빈은[2., 46.)및[46., 90.)입니다.
이제 빈의 가장자리를 지정합니다.
import numpy as np
a = np.array(
[89, 34, 56, 87, 90, 23, 45, 12, 65, 78, 9, 34, 12, 11, 2, 65, 78, 82, 28, 78]
)
histogram = np.histogram(a, bins=[0, 30, 60, 90])
print(histogram)
출력:
(array([7, 4, 9]), array([0, 30, 60, 90]))
예제 코드: density 매개 변수를 사용하는numpy.histogram()
import numpy as np
a = np.array(
[89, 34, 56, 87, 90, 23, 45, 12, 65, 78, 9, 34, 12, 11, 2, 65, 78, 82, 28, 78]
)
histogram = np.histogram(a, bins=5, density=True)
print(histogram)
출력:
(array([ 0.01420455, 0.01136364, 0.00284091, 0.00852273, 0.01988636]),
array([ 2. , 19.6, 37.2, 54.8, 72.4, 90. ]))
히스토그램 값을 계산하는 대신 함수가 확률을 생성합니다.
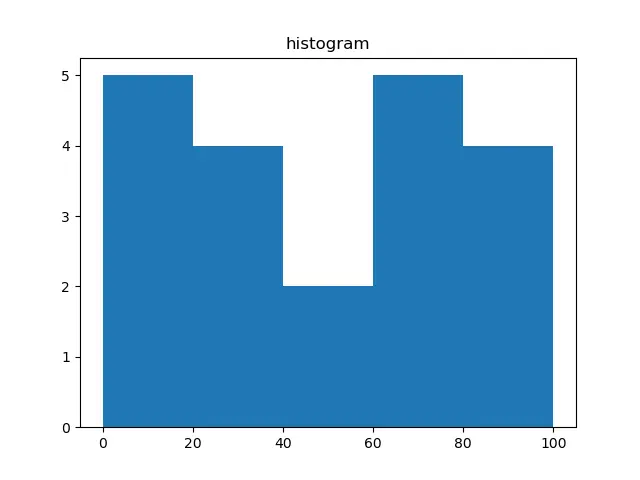
예제 코드: 히스토그램을 그리는numpy.histogram()
pyplot을 사용하여 히스토그램을 그릴 수 있습니다.
from matplotlib import pyplot as plt
import numpy as np
a = np.array(
[89, 34, 56, 87, 90, 23, 45, 12, 65, 78, 9, 34, 12, 11, 2, 65, 78, 82, 28, 78]
)
plt.hist(a, bins=[0, 20, 40, 60, 80, 100])
plt.title("histogram")
plt.show()
출력:
튜토리얼이 마음에 드시나요? DelftStack을 구독하세요 YouTube에서 저희가 더 많은 고품질 비디오 가이드를 제작할 수 있도록 지원해주세요. 구독하다