二分探索木の中間順の次節点
二分木の中間順の次節点は、二分木の中間順探索で次に来るノードです。つまり、ツリー内の最後のノードは NULL です。二分探索木の中間順探索はソートされた配列であるので、次のノードは NULL です。与えられたノードよりも小さいキーを持つノードをその順不同の後継ノードと定義します。BST では、中間順の次節点には 2つの可能性があり、そのノードの右サブツリーまたは祖先の中で値が最も小さいノードが中間順後継者となります。そうでない場合、そのノードの中間順の次節点は存在しません。
BST アルゴリズムにおける中間順の次節点
root==NULLならば、succをNULLに設定して返します。root->data<current->dataならば、succをcurrent、currentをcurrent->leftとします。root->data>current->dataの場合、currentをcurrent->rightとします。root->data==current->dataでroot->right!=NULLの場合、succ=minimum(current->right).succを返します。
BST での中間順の次節点

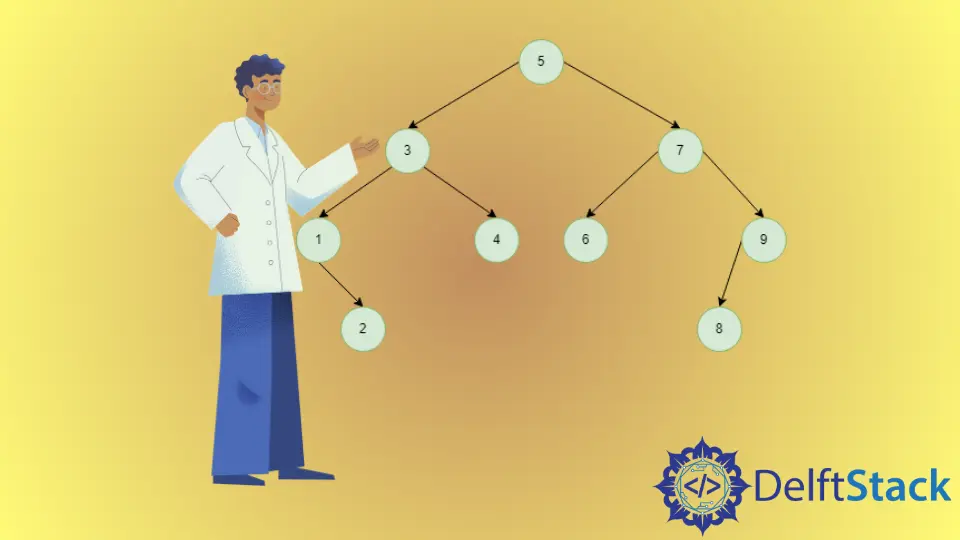
3 には右ノードがあり、 4 は右サブツリーの 3 よりも大きい最小ノードであるため、 3 の中間順の次節点は 4 です。
4 には正しいノードがないため、 4 の中間順の次節点は 5 であり、その祖先を調べる必要があります。その中で、 5 は 4 よりも大きい最小のノードです。
BST の実装における中間順の次節点
#include <iostream>
using namespace std;
class Node {
public:
int data;
Node *left, *right;
Node(int x) {
this->data = x;
this->left = this->right = NULL;
}
};
Node* insert(Node* root, int key) {
if (root == NULL) {
return new Node(key);
}
if (key < root->data) {
root->left = insert(root->left, key);
} else {
root->right = insert(root->right, key);
}
return root;
}
Node* getNextleft(Node* root) {
while (root->left) {
root = root->left;
}
return root;
}
void inorderSuccessor(Node* root, Node*& succ, int key) {
if (root == NULL) {
succ = NULL;
return;
}
if (root->data == key) {
if (root->right) {
succ = getNextleft(root->right);
}
}
else if (key < root->data) {
succ = root;
inorderSuccessor(root->left, succ, key);
} else {
inorderSuccessor(root->right, succ, key);
}
}
int main() {
int keys[] = {1, 5, 8, 2, 6, 3, 7, 4};
Node* root = NULL;
for (int key : keys) {
root = insert(root, key);
}
for (int key : keys) {
Node* prec = NULL;
inorderSuccessor(root, prec, key);
if (prec) {
cout << "Inorder successor of node " << key << " is " << prec->data;
} else {
cout << "No inorder Successor of node " << key;
}
cout << '\n';
}
return 0;
}
BST アルゴリズムにおける中間順の次節点の複雑性
時間計算量
- 平均ケース
平均的なケースでは、BST の中から順不同の後継者を見つける時間の複雑さは、二分探索木の高さのオーダーです。平均すると、BST の高さは O(logn) です。これは、形成された BST がバランスのとれた BST である場合に発生します。したがって、時間の複雑さは [Big Theta]: O(logn) のオーダーです。
- 最良の場合
ベストケースは木がバランスのとれた BST である場合です。ベストケースの削除の時間複雑度は O(logn) のオーダーです。これは平均ケースの時間複雑度と同じです。
- 最悪の場合
最悪の場合、ルートから最深部のリーフノードまで、つまり木の高さ h 全体を移動しなければならないかもしれません。木が不均衡である場合、すなわち、木が歪んでいる場合、木の高さは n になるかもしれません。
空間の複雑さ
アルゴリズムの空間の複雑さは、再帰呼び出しに必要な余分な空間があるため、O(h) となります。

Harshit Jindal has done his Bachelors in Computer Science Engineering(2021) from DTU. He has always been a problem solver and now turned that into his profession. Currently working at M365 Cloud Security team(Torus) on Cloud Security Services and Datacenter Buildout Automation.
LinkedIn