Binärer Suchbaum Inorder Succesor
- Inorder-Nachfolger im BST-Algorithmus
- Inorder Successor in BST Veranschaulichung
- Inorder Successor in der BST-Implementierung
- Komplexität des Inorder Successor in BST-Algorithmus
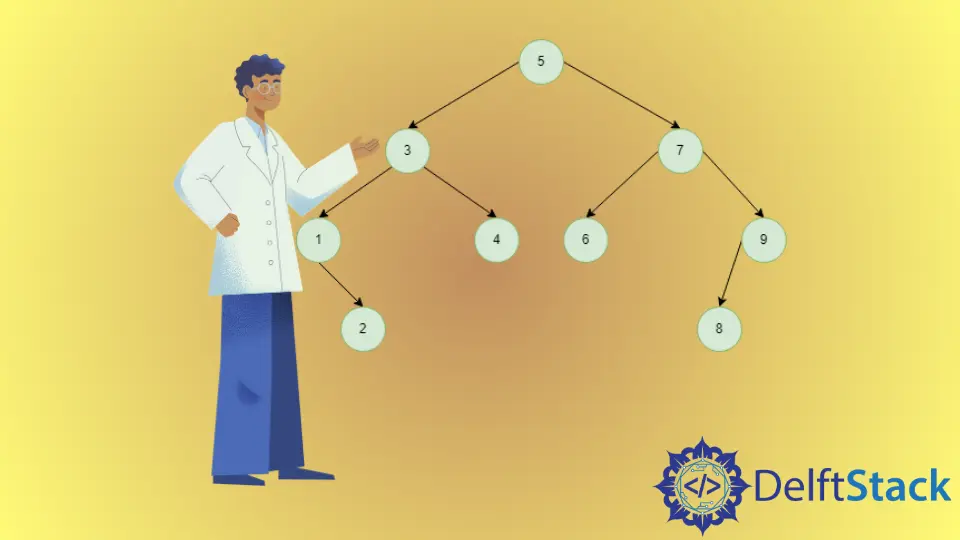
Der Inorder-Nachfolger eines Binärbaums ist der Knoten, der in der Inorder-Traversierung des Binärbaums als nächstes kommt. Für den letzten Knoten innerhalb des Baums ist er also NULL. Da die Inorder-Traversal des binären Suchbaums ein sortiertes Array ist. Der Knoten mit dem kleinsten Schlüssel, der größer als der angegebene Knoten ist, wird als dessen Nachfolger in der Reihenfolge definiert. In einem BST gibt es zwei Möglichkeiten für den Inorder-Nachfolger, den Knoten mit dem kleinsten Wert im rechten Teilbaum des Knotens oder den Vorgänger. Andernfalls existiert der Inorder-Nachfolger für den Knoten nicht.
Inorder-Nachfolger im BST-Algorithmus
- Wenn
root==NULL, dannsuccalsNULLsetzen und zurückgeben. - Wenn
root->data<current->data, dannsuccalscurrentundcurrentalscurrent->left. - Wenn
root->data>current->data, danncurrentalscurrent->right. - Wenn
root->data==current->dataundroot->right!=NULL,succ=Minimum(current->right). - return
succ.
Inorder Successor in BST Veranschaulichung

Der Inorder-Nachfolger von 3 ist 4, weil 3 einen rechten Knoten hat und 4 der kleinste Knoten ist, der größer als 3 im rechten Teilbaum ist.
Der inorder successor von 4 ist 5, weil 4 keinen rechten Knoten hat und wir uns seine Vorfahren ansehen müssen und unter diesen ist 5 der kleinste Knoten, der größer als 4 ist.
Inorder Successor in der BST-Implementierung
#include <iostream>
using namespace std;
class Node {
public:
int data;
Node *left, *right;
Node(int x) {
this->data = x;
this->left = this->right = NULL;
}
};
Node* insert(Node* root, int key) {
if (root == NULL) {
return new Node(key);
}
if (key < root->data) {
root->left = insert(root->left, key);
} else {
root->right = insert(root->right, key);
}
return root;
}
Node* getNextleft(Node* root) {
while (root->left) {
root = root->left;
}
return root;
}
void inorderSuccessor(Node* root, Node*& succ, int key) {
if (root == NULL) {
succ = NULL;
return;
}
if (root->data == key) {
if (root->right) {
succ = getNextleft(root->right);
}
}
else if (key < root->data) {
succ = root;
inorderSuccessor(root->left, succ, key);
} else {
inorderSuccessor(root->right, succ, key);
}
}
int main() {
int keys[] = {1, 5, 8, 2, 6, 3, 7, 4};
Node* root = NULL;
for (int key : keys) {
root = insert(root, key);
}
for (int key : keys) {
Node* prec = NULL;
inorderSuccessor(root, prec, key);
if (prec) {
cout << "Inorder successor of node " << key << " is " << prec->data;
} else {
cout << "No inorder Successor of node " << key;
}
cout << '\n';
}
return 0;
}
Komplexität des Inorder Successor in BST-Algorithmus
Zeitkomplexität
- Durchschnittlicher Fall
Im Durchschnittsfall ist die Zeitkomplexität beim Finden eines Nachfolgers in einem BST in der Größenordnung der Höhe des binären Suchbaums. Im Durchschnitt ist die Höhe eines BST O(logn). Sie tritt auf, wenn der gebildete BST ein balancierter BST ist. Daher ist die Zeitkomplexität in der Größenordnung von [Big Theta]: O(logn).
- Bester Fall
Der Best-Case tritt auf, wenn der Baum ein balanciertes BST ist. Die Best-Case-Zeitkomplexität des Löschens ist in der Größenordnung von O(logn). Sie ist identisch mit der Zeitkomplexität im mittleren Fall.
- Schlechtester Fall
Im schlimmsten Fall müssen wir von der Wurzel bis zum tiefsten Blattknoten, d. h. über die gesamte Höhe h des Baums, gehen. Wenn der Baum unbalanciert ist, d.h. schief, kann die Höhe des Baums n werden, und daher ist die Worst-Case-Zeitkomplexität sowohl der Einfüge- als auch der Suchoperation O(n).
Raumkomplexität
Die Platzkomplexität des Algorithmus ist O(h) aufgrund des zusätzlichen Platzbedarfs durch Rekursionsaufrufe.

Harshit Jindal has done his Bachelors in Computer Science Engineering(2021) from DTU. He has always been a problem solver and now turned that into his profession. Currently working at M365 Cloud Security team(Torus) on Cloud Security Services and Datacenter Buildout Automation.
LinkedInVerwandter Artikel - Data Structure
- Binärbaum in Binärsuchbaum konvertieren
- Binärbaum-Traversal
- Binärer Suchbaum
- Binärer Suchbaum Iteratives Einfügen
- Binärer Suchbaum löschen
Verwandter Artikel - Binary Tree
- Binärbaum in Binärsuchbaum konvertieren
- Binärbaum-Traversal
- Binärer Suchbaum
- Binärer Suchbaum Iteratives Einfügen
- Binärer Suchbaum löschen