Python ステップワイズ回帰
- Python での段階的回帰
-
Python の
statsmodelsライブラリを使用した段階的回帰 -
Python の
sklearnライブラリを使用した段階的回帰 -
Python の
mlxtendライブラリを使用した段階的回帰
このチュートリアルでは、Python でステップワイズ回帰を実行する方法について説明します。
Python での段階的回帰
ステップワイズ回帰は、線形回帰モデルを構築するために特徴のサブセットを選択するために、統計および機械学習で使用される方法です。 ステップワイズ回帰は、高い精度レベルを維持しながら、モデルの複雑さを最小限に抑えることを目的としています。
この方法は、特徴の数が多く、どの特徴が予測にとって重要であるかが不明な場合に特に役立ちます。
Python の statsmodels ライブラリを使用した段階的回帰
statsmodels ライブラリは、ステップワイズ回帰を実行するために使用できる OLS() クラス を提供します。 この関数は、前方選択と後方除去の組み合わせを使用して、特徴の最良のサブセットを選択します。
関数は空のモデルから開始し、係数の有意性に基づいて変数を 1つずつ追加します。 有意でない変数はモデルから除外されます。
statsmodels で stepwise 関数を使用する方法の例を次に示します。
import numpy as np
import pandas as pd
import statsmodels.api as sm
# Load the data
data = pd.read_csv("data.csv")
# Define the dependent and independent variables
x = data.drop("EstimatedSalary", axis=1)
y = data["EstimatedSalary"]
# Perform stepwise regression
result = sm.OLS(y, x).fit()
# Print the summary of the model
print(result.summary())
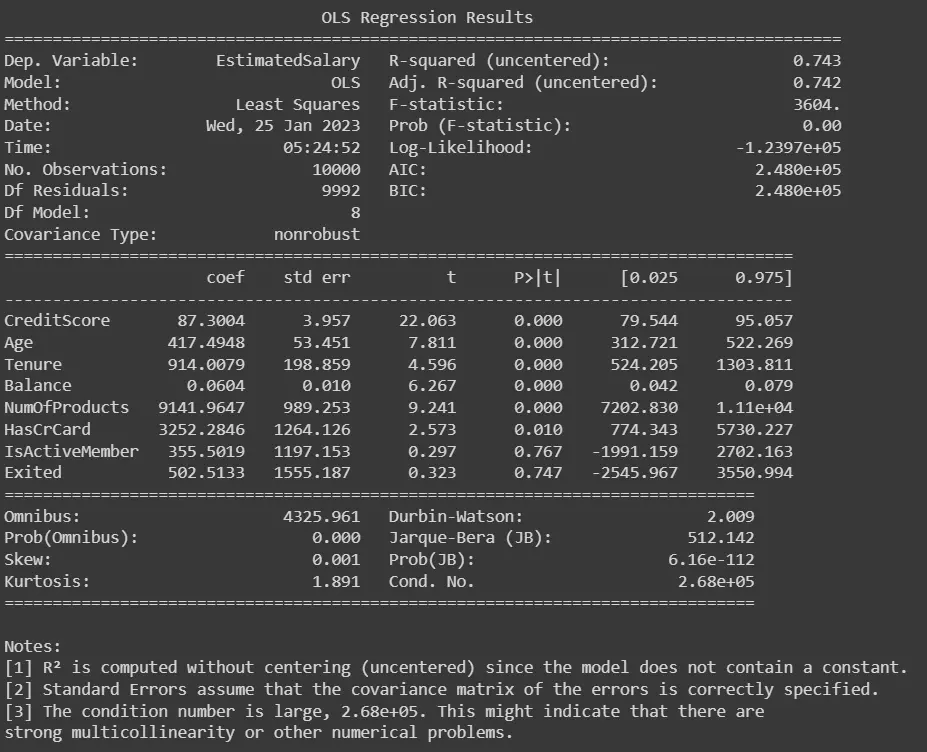
出力:
最初に上記のコード例のデータをロードし、従属変数と独立変数を定義します。 次に、statsmodels.formula.api ライブラリの OLS() 関数を使用して段階的回帰を実行し、変数の係数、p 値、R 2 乗などの情報を含むモデルの要約を出力します。 価値。
Python の sklearn ライブラリを使用した段階的回帰
sklearn ライブラリは、段階的な回帰を実行するための RFE (Recursive Feature Elimination) クラス を提供します。 この方法は、すべての機能から開始し、重要度に基づいて再帰的に機能を削除します。
RFE メソッドは、指定された推定量 (線形回帰モデルなど) を使用して特徴の重要性を推定し、各反復で最も重要でない特徴を再帰的に削除します。
sklearn で RFE メソッドを使用する方法の例を次に示します。
from sklearn.feature_selection import RFE
from sklearn.linear_model import LinearRegression
# Load the data
data = pd.read_csv("data.csv")
# Define the dependent and independent variables
x = data.drop("EstimatedSalary", axis=1)
y = data["EstimatedSalary"]
# Create a linear regression estimator
estimator = LinearRegression()
# Create the RFE object and specify the number of
selector = RFE(estimator, n_features_to_select=5)
# Fit the RFE object to the data
selector = selector.fit(x, y)
# Print the selected features
print(x.columns[selector.support_])
出力:
Index(['Tenure', 'NumOfProducts', 'HasCrCard', 'IsActiveMember', 'Exited'], dtype='object')
最初に上記のコード例のデータをロードし、従属変数と独立変数を定義します。 次に、線形回帰推定器と RFE オブジェクトを作成します。
選択する機能の数を 5 に設定しました。これは、最終的なモデルには、重要度に応じて上位 5つの機能のみが含まれることを意味します。 次に、RFE オブジェクトをデータに適合させ、選択した特徴を出力します。
RFE() メソッドは、指定された推定量を使用して特徴の重要性を計算することに注意してください。そのため、データに適切な推定量を使用することが重要です。 RFE 法は、ランダム フォレストや SVM などの他の推定器でも使用できます。
Python の mlxtend ライブラリを使用した段階的回帰
mlxtend ライブラリは、ステップワイズ回帰を実行するための SFS クラス を提供します。 この関数は、前方選択と後方除去の組み合わせを使用して、特徴の最良のサブセットを選択します。
この関数も空のモデルから開始し、係数の有意性に基づいて変数を 1つずつ追加します。 有意でない変数はモデルから除外されます。
mlxtend で stepwise 関数を使用する方法の例を次に示します。
from sklearn.linear_model import LinearRegression
from mlxtend.feature_selection import SequentialFeatureSelector as SFS
import joblib
import sys
sys.modules["sklearn.externals.joblib"] = joblib
# Load the data
data = pd.read_csv("data.csv")
# Define the dependent and independent variables
x = data.drop("EstimatedSalary", axis=1)
y = data["EstimatedSalary"]
# Create a linear regression estimator
estimator = LinearRegression()
# Create the SFS object and specify the number of features to select
sfs = SFS(estimator, k_features=5, forward=True, floating=False, scoring="r2", cv=5)
# Fit the SFS object to the data
sfs = sfs.fit(x, y)
# Print the selected features
print(sfs.k_feature_idx_)
出力:
(1, 2, 4, 6, 7)
この例では、最初にデータを読み込み、従属変数と独立変数を定義します。 次に、線形回帰推定器と SFS オブジェクトを作成します。
選択する機能の数を 5 に設定します。これは、最終的なモデルには、重要度に応じて上位 5つの機能のみが含まれることを意味します。 次に、SFS オブジェクトをデータに適合させ、選択した特徴を出力します。
mlxtend の stepwise() 関数は、指定された推定量を使用して特徴の重要性を計算することに注意してください。そのため、データに適切な推定量を使用することが重要です。 この関数を使用すると、選択プロセスの方向、スコアリング メトリクス、および使用する交差検証フォールドの数を設定することもできます。
要約すると、ステップワイズ回帰は、線形回帰モデルで特徴を選択するための強力な手法です。 statsmodels、sklearn、および mlxtend ライブラリは、Python で段階的回帰を実行するためのさまざまな方法を提供しますが、それぞれに長所と短所があります。
方法の選択は、問題の特定の要件とデータの可用性によって異なります。 ステップワイズ回帰は過適合になりやすいことに注意することが重要であり、他の機能選択手法および交差検証と組み合わせて使用することをお勧めします。

Maisam is a highly skilled and motivated Data Scientist. He has over 4 years of experience with Python programming language. He loves solving complex problems and sharing his results on the internet.
LinkedIn