Regresión paso a paso de Python
- Regresión paso a paso en Python
-
Regresión paso a paso con la biblioteca
statsmodelsen Python -
Regresión paso a paso con la biblioteca
sklearnen Python -
Regresión paso a paso con la biblioteca
mlxtenden Python
Este tutorial discutirá los métodos para realizar la regresión paso a paso en Python.
Regresión paso a paso en Python
La regresión paso a paso es un método que se usa en estadísticas y aprendizaje automático para seleccionar un subconjunto de características para construir un modelo de regresión lineal. La regresión paso a paso tiene como objetivo minimizar la complejidad del modelo manteniendo un alto nivel de precisión.
Este método es particularmente útil en los casos en que la cantidad de características es grande y no está claro qué características son importantes para la predicción.
Regresión paso a paso con la biblioteca statsmodels en Python
La biblioteca statsmodels proporciona la clase OLS() que se puede utilizar para realizar una regresión paso a paso. Esta función utiliza una combinación de selección hacia adelante y eliminación hacia atrás para seleccionar el mejor subconjunto de funciones.
La función comienza con un modelo vacío y agrega variables una por una según la importancia de sus coeficientes. Las variables que no son significativas se eliminan del modelo.
Aquí hay un ejemplo de cómo usar la función stepwise en statsmodels.
import numpy as np
import pandas as pd
import statsmodels.api as sm
# Load the data
data = pd.read_csv("data.csv")
# Define the dependent and independent variables
x = data.drop("EstimatedSalary", axis=1)
y = data["EstimatedSalary"]
# Perform stepwise regression
result = sm.OLS(y, x).fit()
# Print the summary of the model
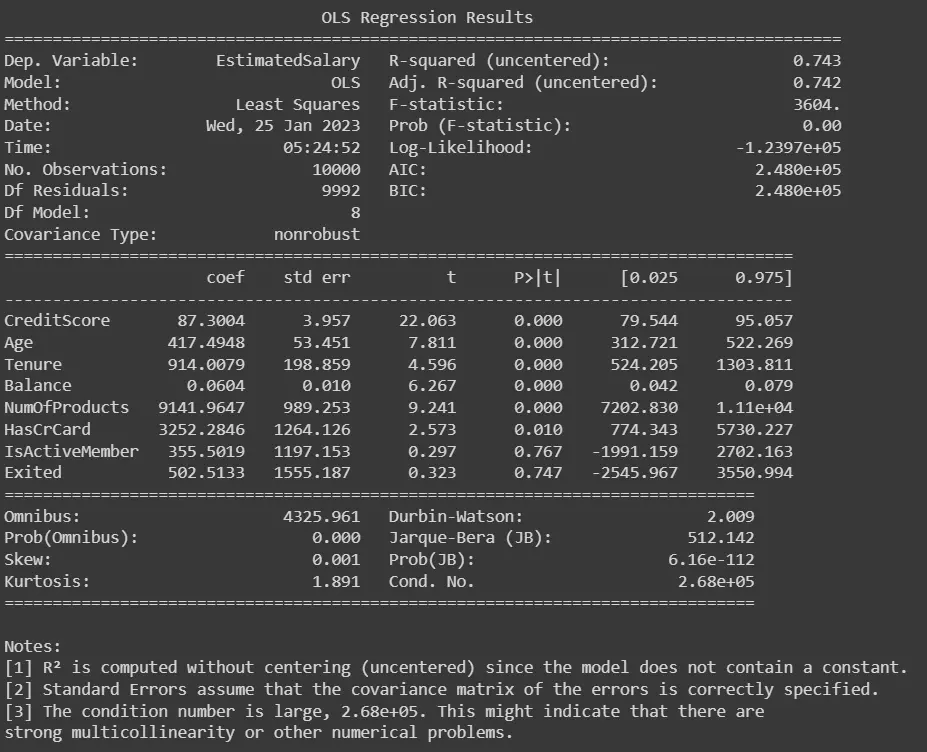
print(result.summary())
Producción:
Primero cargamos los datos en el ejemplo de código anterior y definimos las variables dependientes e independientes. Luego, realizamos una regresión paso a paso usando la función OLS() de la biblioteca statsmodels.formula.api e imprimimos un resumen del modelo, que incluye información como los coeficientes de las variables, valores p y R-cuadrado valor.
Regresión paso a paso con la biblioteca sklearn en Python
La biblioteca sklearn proporciona una clase RFE (Recursive Feature Elimination) para realizar una regresión por pasos. Este método comienza con todas las funciones y elimina recursivamente las funciones en función de su importancia.
El método RFE utiliza un estimador específico (como un modelo de regresión lineal) para estimar la importancia de las características y elimina recursivamente la característica menos importante en cada iteración.
Aquí hay un ejemplo de cómo usar el método RFE en sklearn.
from sklearn.feature_selection import RFE
from sklearn.linear_model import LinearRegression
# Load the data
data = pd.read_csv("data.csv")
# Define the dependent and independent variables
x = data.drop("EstimatedSalary", axis=1)
y = data["EstimatedSalary"]
# Create a linear regression estimator
estimator = LinearRegression()
# Create the RFE object and specify the number of
selector = RFE(estimator, n_features_to_select=5)
# Fit the RFE object to the data
selector = selector.fit(x, y)
# Print the selected features
print(x.columns[selector.support_])
Producción :
Index(['Tenure', 'NumOfProducts', 'HasCrCard', 'IsActiveMember', 'Exited'], dtype='object')
Primero cargamos los datos en el ejemplo de código anterior y definimos las variables dependientes e independientes. Luego, creamos un estimador de regresión lineal y un objeto RFE.
Establecimos el número de características a seleccionar en 5, lo que significa que el modelo final solo incluirá las 5 características principales según su importancia. A continuación, ajustamos el objeto RFE a los datos e imprimimos las características seleccionadas.
Vale la pena señalar que el método RFE() usa el estimador especificado para calcular la importancia de las características, por lo que es importante usar un estimador apropiado para los datos. El método RFE también se puede utilizar con otros estimadores como Random Forest o SVM.
Regresión paso a paso con la biblioteca mlxtend en Python
La biblioteca mlxtend proporciona la clase SFS para realizar una regresión paso a paso. Esta función utiliza una combinación de selección hacia adelante y eliminación hacia atrás para seleccionar el mejor subconjunto de funciones.
Esta función también comienza con un modelo vacío y agrega variables una por una según la importancia de sus coeficientes. Las variables que no son significativas se eliminan del modelo.
Aquí hay un ejemplo de cómo usar la función paso a paso en mlxtend.
from sklearn.linear_model import LinearRegression
from mlxtend.feature_selection import SequentialFeatureSelector as SFS
import joblib
import sys
sys.modules["sklearn.externals.joblib"] = joblib
# Load the data
data = pd.read_csv("data.csv")
# Define the dependent and independent variables
x = data.drop("EstimatedSalary", axis=1)
y = data["EstimatedSalary"]
# Create a linear regression estimator
estimator = LinearRegression()
# Create the SFS object and specify the number of features to select
sfs = SFS(estimator, k_features=5, forward=True, floating=False, scoring="r2", cv=5)
# Fit the SFS object to the data
sfs = sfs.fit(x, y)
# Print the selected features
print(sfs.k_feature_idx_)
Producción :
(1, 2, 4, 6, 7)
Primero cargamos los datos en este ejemplo y definimos las variables dependientes e independientes. Luego, creamos un estimador de regresión lineal y un objeto SFS.
Establecemos el número de características a seleccionar como 5, lo que significa que el modelo final solo incluirá las 5 características principales según su importancia. A continuación, ajustamos el objeto SFS a los datos e imprimimos las características seleccionadas.
Vale la pena señalar que la función stepwise() de mlxtend usa el estimador especificado para calcular la importancia de las características, por lo que es importante usar un estimador apropiado para los datos. La función también nos permite establecer la dirección del proceso de selección, la métrica de puntuación y el número de pliegues de validación cruzada a utilizar.
En resumen, la regresión por pasos es una técnica poderosa para la selección de características en modelos de regresión lineal. Las bibliotecas statsmodels, sklearn y mlxtend proporcionan diferentes métodos para realizar la regresión paso a paso en Python, cada uno con ventajas y desventajas.
La elección del método dependerá de los requisitos específicos del problema y de la disponibilidad de los datos. Es importante tener en cuenta que la regresión por pasos puede ser propensa a sobreajustarse, y se recomienda usarla en combinación con otras técnicas de selección de características y validación cruzada.

Maisam is a highly skilled and motivated Data Scientist. He has over 4 years of experience with Python programming language. He loves solving complex problems and sharing his results on the internet.
LinkedIn