Python-Schrittweise Regression
- Schrittweise Regression in Python
-
Schrittweise Regression mit der Bibliothek
statsmodelsin Python -
Schrittweise Regression mit der Bibliothek
sklearnin Python -
Schrittweise Regression mit der Bibliothek
mlxtendin Python
In diesem Tutorial werden die Methoden zum Ausführen der schrittweisen Regression in Python erläutert.
Schrittweise Regression in Python
Die schrittweise Regression ist eine Methode, die in der Statistik und beim maschinellen Lernen verwendet wird, um eine Teilmenge von Merkmalen zum Erstellen eines linearen Regressionsmodells auszuwählen. Die schrittweise Regression zielt darauf ab, die Komplexität des Modells zu minimieren und gleichzeitig ein hohes Genauigkeitsniveau beizubehalten.
Diese Methode ist besonders nützlich, wenn die Anzahl der Merkmale groß ist und unklar ist, welche Merkmale für die Vorhersage wichtig sind.
Schrittweise Regression mit der Bibliothek statsmodels in Python
Die Bibliothek statsmodels stellt die Klasse OLS() bereit, mit der eine schrittweise Regression durchgeführt werden kann. Diese Funktion verwendet eine Kombination aus Vorwärtsauswahl und Rückwärtseliminierung, um die beste Teilmenge von Merkmalen auszuwählen.
Die Funktion beginnt mit einem leeren Modell und fügt Variablen nacheinander basierend auf der Signifikanz ihrer Koeffizienten hinzu. Nicht signifikante Variablen werden aus dem Modell eliminiert.
Hier ist ein Beispiel für die Verwendung der stepwise-Funktion in statsmodels.
import numpy as np
import pandas as pd
import statsmodels.api as sm
# Load the data
data = pd.read_csv("data.csv")
# Define the dependent and independent variables
x = data.drop("EstimatedSalary", axis=1)
y = data["EstimatedSalary"]
# Perform stepwise regression
result = sm.OLS(y, x).fit()
# Print the summary of the model
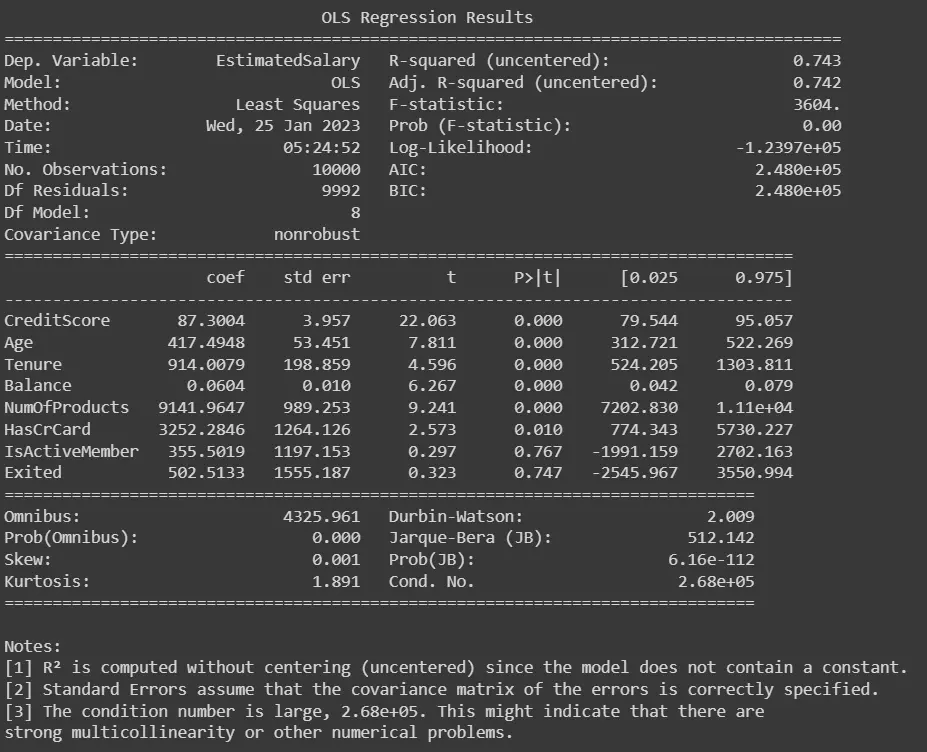
print(result.summary())
Ausgang:
Wir laden zunächst die Daten im obigen Codebeispiel und definieren die abhängigen und unabhängigen Variablen. Dann führen wir eine schrittweise Regression mit der Funktion OLS() aus der Bibliothek statsmodels.formula.api durch und drucken eine Modellzusammenfassung, die Informationen wie die Koeffizienten der Variablen, p-Werte und R-Quadrat enthält Wert.
Schrittweise Regression mit der Bibliothek sklearn in Python
Die Bibliothek sklearn stellt eine Klasse RFE (Recursive Feature Elimination) zur Durchführung einer schrittweisen Regression bereit. Diese Methode beginnt mit allen Features und eliminiert rekursiv Features basierend auf ihrer Wichtigkeit.
Die RFE-Methode verwendet einen bestimmten Schätzer (z. B. ein lineares Regressionsmodell), um die Wichtigkeit der Merkmale abzuschätzen, und entfernt bei jeder Iteration rekursiv das unwichtigste Merkmal.
Hier ist ein Beispiel für die Verwendung der RFE-Methode in sklearn.
from sklearn.feature_selection import RFE
from sklearn.linear_model import LinearRegression
# Load the data
data = pd.read_csv("data.csv")
# Define the dependent and independent variables
x = data.drop("EstimatedSalary", axis=1)
y = data["EstimatedSalary"]
# Create a linear regression estimator
estimator = LinearRegression()
# Create the RFE object and specify the number of
selector = RFE(estimator, n_features_to_select=5)
# Fit the RFE object to the data
selector = selector.fit(x, y)
# Print the selected features
print(x.columns[selector.support_])
Ausgang:
Index(['Tenure', 'NumOfProducts', 'HasCrCard', 'IsActiveMember', 'Exited'], dtype='object')
Wir laden zunächst die Daten im obigen Codebeispiel und definieren die abhängigen und unabhängigen Variablen. Dann erstellen wir einen linearen Regressionsschätzer und ein RFE-Objekt.
Wir legen die Anzahl der auszuwählenden Merkmale auf 5 fest, was bedeutet, dass das endgültige Modell nur die 5 wichtigsten Merkmale entsprechend ihrer Wichtigkeit enthalten wird. Als nächstes passen wir das RFE-Objekt an die Daten an und drucken die ausgewählten Features.
Es ist erwähnenswert, dass die Methode RFE() den angegebenen Schätzer verwendet, um die Wichtigkeit der Merkmale zu berechnen, daher ist es wichtig, einen geeigneten Schätzer für die Daten zu verwenden. Die RFE-Methode kann auch mit anderen Schätzern wie Random Forest oder SVM verwendet werden.
Schrittweise Regression mit der Bibliothek mlxtend in Python
Die Bibliothek mlxtend stellt die Klasse SFS zur Durchführung einer schrittweisen Regression bereit. Diese Funktion verwendet eine Kombination aus Vorwärtsauswahl und Rückwärtseliminierung, um die beste Teilmenge von Merkmalen auszuwählen.
Diese Funktion beginnt ebenfalls mit einem leeren Modell und fügt Variablen nacheinander basierend auf der Signifikanz ihrer Koeffizienten hinzu. Nicht signifikante Variablen werden aus dem Modell eliminiert.
Hier ist ein Beispiel für die Verwendung der stepwise-Funktion in mlxtend.
from sklearn.linear_model import LinearRegression
from mlxtend.feature_selection import SequentialFeatureSelector as SFS
import joblib
import sys
sys.modules["sklearn.externals.joblib"] = joblib
# Load the data
data = pd.read_csv("data.csv")
# Define the dependent and independent variables
x = data.drop("EstimatedSalary", axis=1)
y = data["EstimatedSalary"]
# Create a linear regression estimator
estimator = LinearRegression()
# Create the SFS object and specify the number of features to select
sfs = SFS(estimator, k_features=5, forward=True, floating=False, scoring="r2", cv=5)
# Fit the SFS object to the data
sfs = sfs.fit(x, y)
# Print the selected features
print(sfs.k_feature_idx_)
Ausgang:
(1, 2, 4, 6, 7)
Wir laden in diesem Beispiel zunächst die Daten und definieren die abhängigen und unabhängigen Variablen. Dann erstellen wir einen linearen Regressionsschätzer und ein SFS-Objekt.
Wir setzen die Anzahl der auszuwählenden Features auf 5, was bedeutet, dass das endgültige Modell nur die Top 5 Features entsprechend ihrer Wichtigkeit enthalten wird. Als nächstes passen wir das SFS-Objekt an die Daten an und drucken die ausgewählten Merkmale.
Es ist erwähnenswert, dass die Funktion stepwise() von mlxtend den angegebenen Schätzer verwendet, um die Wichtigkeit der Merkmale zu berechnen, daher ist es wichtig, einen geeigneten Schätzer für die Daten zu verwenden. Die Funktion ermöglicht es uns auch, die Richtung des Auswahlprozesses, die Bewertungsmetrik und die Anzahl der zu verwendenden Kreuzvalidierungsfaltungen festzulegen.
Zusammenfassend lässt sich sagen, dass die schrittweise Regression eine leistungsstarke Technik zur Merkmalsauswahl in linearen Regressionsmodellen ist. Die Bibliotheken statsmodels, sklearn und mlxtend bieten verschiedene Methoden zur Durchführung der schrittweisen Regression in Python, jeweils mit Vor- und Nachteilen.
Die Wahl der Methode hängt von den spezifischen Anforderungen des Problems und der Verfügbarkeit der Daten ab. Es ist wichtig zu beachten, dass die schrittweise Regression anfällig für Überanpassung sein kann, und es wird empfohlen, sie in Kombination mit anderen Merkmalsauswahltechniken und Kreuzvalidierung zu verwenden.

Maisam is a highly skilled and motivated Data Scientist. He has over 4 years of experience with Python programming language. He loves solving complex problems and sharing his results on the internet.
LinkedIn