Pandas DataFrame を Wide から Long に変更する
- Pandas のワイド データ形式とロング データ形式
- ワイド データ フォーマットの使用
- 長いデータ形式の使用
-
pd.melt()を使用して Pandas DataFrame をワイド フォーマットからロング フォーマットに再形成する -
pd.unstack()を使用して、Pandas DataFrame をワイド フォーマットからロング フォーマットに再形成する -
pd.wide_to_long()を使用して Pandas DataFrame をワイド フォーマットからロング フォーマットに変更する
Pandas データフレームの再形成は、データ分析で最もよく使用されるデータ ラングリング タスクの 1つです。 また、テーブルをワイドからロングに移動、ピボット解除/ピボットすることも扱います。
このチュートリアルでは、ワイド データ フォーマットとロング データ フォーマットの違いを学習し、それらの使用方法を説明します。続いて、Pandas データフレームをワイドからロングに再形成する方法を示すさまざまなコード例を示します。
Pandas のワイド データ形式とロング データ形式
データセットは、ワイドまたはロングの 2つの形式で作成できます。 ワイド データ フォーマットとロング データ フォーマットの主な違いを以下に示します。
- ワイド データ形式 - 最初の列の値は繰り返されません。
- 長いデータ形式 - 最初の列の値が繰り返されます。
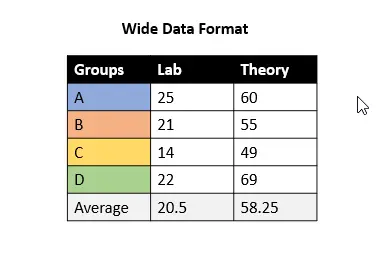
両方の形式を明確に理解するために、グループ A、B、C、および D の lab および theory 試験マークを含むデータ フレームの例を見てみましょう。
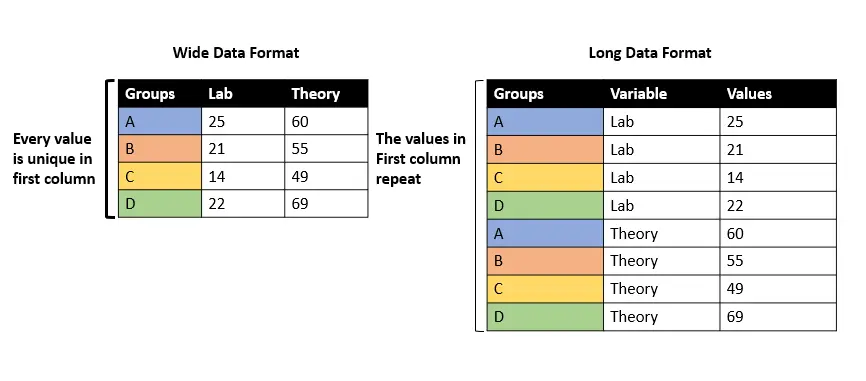
ご覧のとおり、両方のデータ フレームに同じ情報が含まれていますが、形式が異なります。
データセットを表すためにどのデータ形式をいつ使用するか? それは、データで何をしたいかによって異なります。
ワイド データ フォーマットの使用
ワイドデータ形式は、私たちの脳にとって理解しやすいため、実世界のデータを記録するために使用されます。 データを分析する場合も、このデータ形式を使用します。
lab と theory 試験の採点の前の例を見てみましょう。
グループごとの lab と theory 試験の平均を計算したい場合は、ワイド形式でデータを保持する方が簡単です。 同じレコード (行)。
次のスクリーンショットを参照してください。
長いデータ形式の使用
R プログラミング言語などの統計ツールを使用して 1つのプロットで複数の変数を視覚化する場合、主に長いデータ形式を使用します。
ソフトウェアがプロットを作成できるように、ワイド データ形式からロング データ形式に変換する必要があります。
pd.melt() を使用して Pandas DataFrame をワイド フォーマットからロング フォーマットに再形成する
コード例:
import pandas as pd
df = pd.DataFrame(
{
"Groups": ["A", "B", "C", "D"],
"lab": [25, 21, 14, 22],
"theory": [60, 55, 49, 69],
}
)
print("Wide Data Frame:\n")
print(df)
df = pd.melt(df, id_vars="Groups", value_vars=["lab", "theory"])
print("\n\nLong Data Frame:\n")
print(df)
出力:
Wide Data Frame:
Groups lab theory
0 A 25 60
1 B 21 55
2 C 14 49
3 D 22 69
Long Data Frame:
Groups variable value
0 A lab 25
1 B lab 21
2 C lab 14
3 D lab 22
4 A theory 60
5 B theory 55
6 C theory 49
7 D theory 69
ここでは、Groups、lab、および theory の 3つの列を持つデータ フレームがワイド データ形式であり、pd.melt() 関数を使用してロング データ形式に変換します。
pd.melt() は、データフレームをワイド データ形式からロング データ形式にアンピボットするために使用されます (オプションで、識別子を設定したままにします)。 データフレームを、1つまたは複数の列/フィールドが識別子変数 (id_vars) である形式に変換します。
id_vars を除いて、他のすべての列は測定変数 (value_vars) と見なされます。 これらは行軸にピボットされていないため、2つの非識別子列 (variable と value) が残ります。
pd.unstack() を使用して、Pandas DataFrame をワイド フォーマットからロング フォーマットに再形成する
コード例:
import pandas as pd
df = pd.DataFrame(
{
"Groups": ["A", "B", "C", "D"],
"lab": [25, 21, 14, 22],
"theory": [60, 55, 49, 69],
}
)
print("Wide Data Frame:\n")
print(df)
df = df.unstack()
print("\n\nLong Data Frame:\n")
print(df)
出力:
Wide Data Frame:
Groups lab theory
0 A 25 60
1 B 21 55
2 C 14 49
3 D 22 69
Long Data Frame:
Groups 0 A
1 B
2 C
3 D
lab 0 25
1 21
2 14
3 22
theory 0 60
1 55
2 49
3 69
dtype: object
この例では、Groups、lab、および theory, の 3つの列を持つ同じデータ フレームを使用しますが、ここでは、DataFrame.unstack を使用してデータ フレームをワイド データ形式からロング データ形式に再形成します。
(必然的に階層的な) インデックス ラベルのレベルをピボットし、最も内側のレベルにピボットされたインデックス ラベルを持つ新しいレベルのフィールド/列ラベルを含むデータフレームを返します。
インデックスが MultiIndex でない場合、シリーズを出力として取得することを覚えておいてください。 また、特定の問題に対して柔軟で迅速な解決策が必要な場合は、DataFrame.unstack() の代わりに pd.melt() を使用してください。
pd.wide_to_long() を使用して Pandas DataFrame をワイド フォーマットからロング フォーマットに変更する
コード例:
import pandas as pd
df = pd.DataFrame(
{
"Groups": ["A", "B", "C", "D"],
"lab1": [25, 21, 14, 22],
"lab2": [25, 21, 14, 22],
"theory1": [60, 55, 49, 69],
"theory2": [60, 55, 49, 69],
}
)
print("Wide Data Frame:\n")
print(df)
df = pd.wide_to_long(df, stubnames=["lab", "theory"], i="Groups", j="Exams")
print("\n\nLong Data Frame:\n")
print(df)
出力:
Wide Data Frame:
Groups lab1 lab2 theory1 theory2
0 A 25 25 60 60
1 B 21 21 55 55
2 C 14 14 49 49
3 D 22 22 69 69
Long Data Frame:
Groups Exams lab theory
A 1 25 60
B 1 21 55
C 1 14 49
D 1 22 69
A 2 25 60
B 2 21 55
C 2 14 49
D 2 22 69
ここでは、lab1、lab2、theory1、およびtheory2という 4つのグループのマークが付いたデータフレームがあります。A、B、C、およびDです。 pd.wide_to_long() 関数を理解する前に、次のビジュアルを見て、ワイド データ フォーマットがロング データ フォーマットに再形成される方法を理解しましょう。
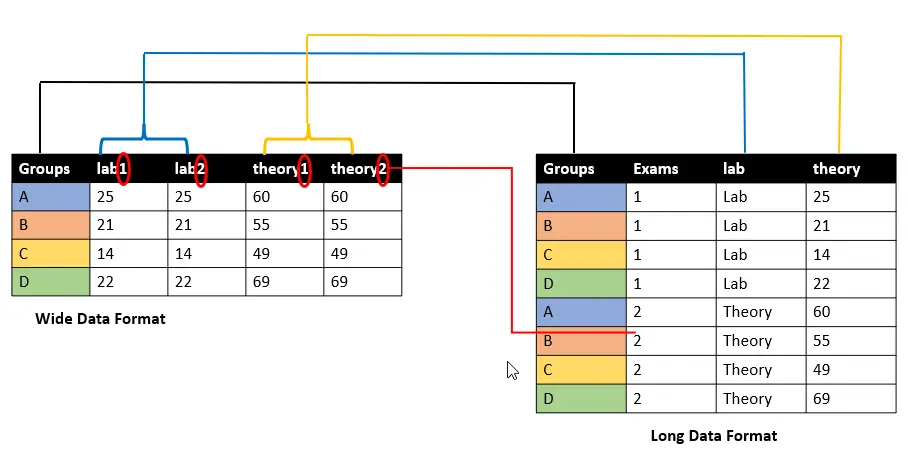
pd.wide_to_long() は非常に特殊な方法で機能します。実際には内部で pd.melt() 関数を使用します。 以下で説明する 4つの必須パラメーターを受け入れますが、重要なのは、列名がどのように形成され、表示されるかです。
wide_to_long() 関数の次の列形式を参照してください。
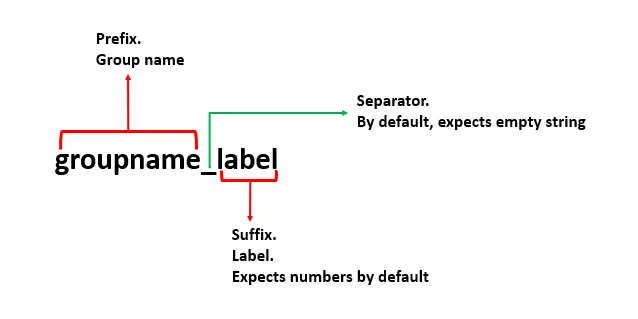
pd.wide_to_long() 関数に 4つのパラメーターを渡して、データ フレームをワイド データ形式からロング データ形式に再形成します。 使用した 4つのパラメーターを以下に示します。
df- これは、再形成したいデータフレームです。stubnames- グループ化する必要があるグループ名 (プレフィックス) とも言えます。 私たちの場合、これらはlabとtheoryです。i- スタックされるべきではない識別子変数です。j- サフィックスを含む列の名前、または列のラベルと言えます。
オプションのパラメータは、sep (セパレータ) と suffix です。 pd.melt()、pd.wide_to_long()、および DataFrame.unstack() こちら の詳細を読むことができます。
