Reformar el marco de datos de Pandas de ancho a largo
- Formato de datos ancho frente a formato de datos largo en Pandas
- Usos del formato de datos amplio
- Usos del formato de datos largos
-
Use
pd.melt()para remodelar el marco de datos de Pandas de formato ancho a largo -
Use
pd.unstack()para remodelar el marco de datos de Pandas de formato ancho a largo -
Use
pd.wide_to_long()para remodelar el marco de datos de Pandas de formato ancho a largo
Remodelar el marco de datos de Pandas es una de las tareas de disputa de datos más utilizadas en el análisis de datos. También se aborda como transportar, desmontar/girar una mesa de ancho a largo.
En este tutorial, aprenderemos la diferencia entre los formatos de datos anchos y largos, lo que conducirá a sus usos, seguido de diferentes ejemplos de código que demuestran cómo remodelar el marco de datos de Pandas de ancho a largo.
Formato de datos ancho frente a formato de datos largo en Pandas
Podemos tener un conjunto de datos en dos formatos: ancho o largo. La principal diferencia entre los formatos de datos anchos y largos se indica a continuación.
- Formato de datos amplio: los valores de la primera columna no se repiten.
- Formato de datos largo: los valores de la primera columna se repiten.
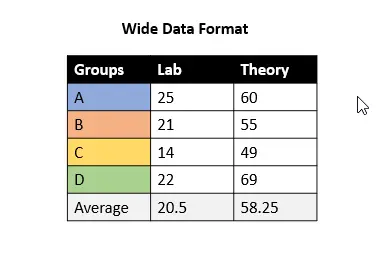
Tomemos los marcos de datos de ejemplo que contienen calificaciones de exámenes de “laboratorio” y “teoría” para los grupos A, B, C y D para comprender ambos formatos claramente.
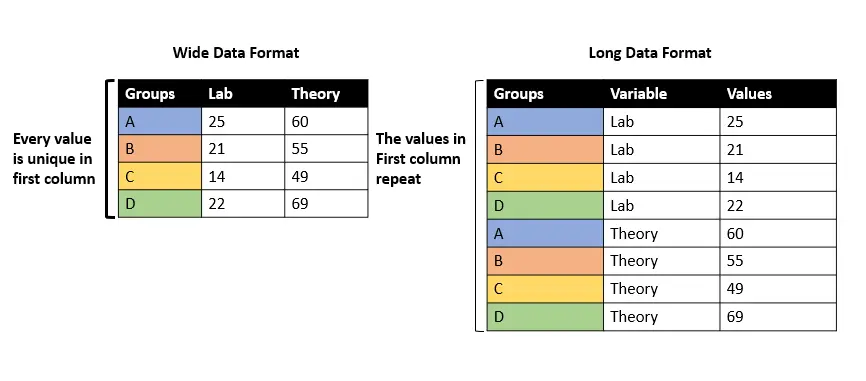
Como podemos ver, ambos marcos de datos tienen la misma información pero en diferentes formatos.
¿Cuándo usar qué formato de datos para representar el conjunto de datos? Depende de lo que queramos hacer con los datos.
Usos del formato de datos amplio
El formato de datos amplio se usa para registrar datos del mundo real porque es fácil de entender para nuestros cerebros. También usamos este formato de datos si estamos analizando datos.
Tomemos el ejemplo anterior de tener calificaciones para los exámenes de laboratorio y teoría.
Si queremos calcular el promedio de los exámenes de laboratorio y teoría por grupo, sería más fácil mantener los datos en el formato ancho porque sería más fácil leer los valores de laboratorio y teoría para cada grupo en el mismo registro (fila).
Vea la siguiente captura de pantalla.
Usos del formato de datos largos
Principalmente usamos formato de datos largos cuando visualizamos múltiples variables en un gráfico usando alguna herramienta estadística, por ejemplo, el lenguaje de programación R.
Debemos tener que convertir el formato de datos ancho a largo para permitir que el software cree el gráfico, por ejemplo, trazar columnas múltiples, crear mapa de calor, etc. A veces, también necesitamos remodelar los conjuntos de datos para la disputa de datos usando Python.
Use pd.melt() para remodelar el marco de datos de Pandas de formato ancho a largo
Código de ejemplo:
import pandas as pd
df = pd.DataFrame(
{
"Groups": ["A", "B", "C", "D"],
"lab": [25, 21, 14, 22],
"theory": [60, 55, 49, 69],
}
)
print("Wide Data Frame:\n")
print(df)
df = pd.melt(df, id_vars="Groups", value_vars=["lab", "theory"])
print("\n\nLong Data Frame:\n")
print(df)
Producción :
Wide Data Frame:
Groups lab theory
0 A 25 60
1 B 21 55
2 C 14 49
3 D 22 69
Long Data Frame:
Groups variable value
0 A lab 25
1 B lab 21
2 C lab 14
3 D lab 22
4 A theory 60
5 B theory 55
6 C theory 49
7 D theory 69
Aquí tenemos un marco de datos con tres columnas, Grupos, laboratorio y teoría en un formato de datos ancho que convertimos a un formato de datos largo usando la función pd.melt().
pd.melt() se usa para cambiar un marco de datos de formato de datos ancho a largo (opcionalmente, dejando los identificadores establecidos). Transforma un marco de datos en un formato en el que una o varias columnas/campos son variables de identificación (id_vars).
Excluyendo los id_vars, todas las demás columnas se consideran variables medidas (value_vars). Estos no están pivotados en el eje de la fila, dejando dos columnas sin identificador (variable y valor).
Use pd.unstack() para remodelar el marco de datos de Pandas de formato ancho a largo
Código de ejemplo:
import pandas as pd
df = pd.DataFrame(
{
"Groups": ["A", "B", "C", "D"],
"lab": [25, 21, 14, 22],
"theory": [60, 55, 49, 69],
}
)
print("Wide Data Frame:\n")
print(df)
df = df.unstack()
print("\n\nLong Data Frame:\n")
print(df)
Producción :
Wide Data Frame:
Groups lab theory
0 A 25 60
1 B 21 55
2 C 14 49
3 D 22 69
Long Data Frame:
Groups 0 A
1 B
2 C
3 D
lab 0 25
1 21
2 14
3 22
theory 0 60
1 55
2 49
3 69
dtype: object
Este ejemplo usa el mismo marco de datos que tiene tres columnas, “Grupos”, “laboratorio” y “teoría”, pero aquí estamos usando DataFrame.unstack para remodelar el marco de datos de formato de datos ancho a largo.
Gira el nivel de las etiquetas de índice (necesariamente jerárquicas) y devuelve un marco de datos que contiene un nuevo nivel de etiquetas de campo/columna cuyo nivel más interno tiene las etiquetas de índice pivotadas.
Recuerde, obtendremos una serie como salida si un índice no es el MultiIndex. Además, si se requiere una solución flexible y rápida para un problema en particular, prefiera pd.melt() en lugar de DataFrame.unstack().
Use pd.wide_to_long() para remodelar el marco de datos de Pandas de formato ancho a largo
Código de ejemplo:
import pandas as pd
df = pd.DataFrame(
{
"Groups": ["A", "B", "C", "D"],
"lab1": [25, 21, 14, 22],
"lab2": [25, 21, 14, 22],
"theory1": [60, 55, 49, 69],
"theory2": [60, 55, 49, 69],
}
)
print("Wide Data Frame:\n")
print(df)
df = pd.wide_to_long(df, stubnames=["lab", "theory"], i="Groups", j="Exams")
print("\n\nLong Data Frame:\n")
print(df)
Producción :
Wide Data Frame:
Groups lab1 lab2 theory1 theory2
0 A 25 25 60 60
1 B 21 21 55 55
2 C 14 14 49 49
3 D 22 22 69 69
Long Data Frame:
Groups Exams lab theory
A 1 25 60
B 1 21 55
C 1 14 49
D 1 22 69
A 2 25 60
B 2 21 55
C 2 14 49
D 2 22 69
Aquí, tenemos un marco de datos con marcas lab1, lab2, theory1ytheory2 para cuatro grupos: A, B, C y D. Antes de entender la función pd.wide_to_long(), veamos la siguiente imagen para comprender cómo se transforma el formato de datos ancho en el formato de datos largos.
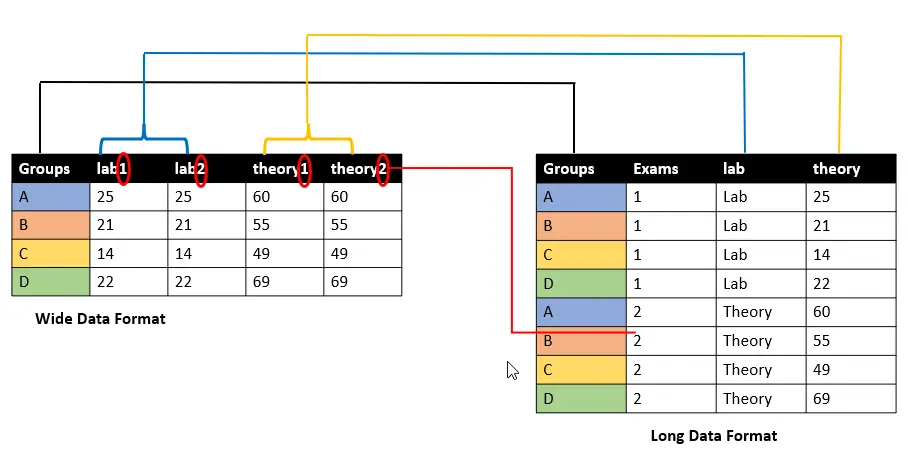
El pd.wide_to_long() funciona de una manera muy particular, en realidad usa la función pd.melt() debajo del capó. Acepta cuatro parámetros obligatorios que entenderemos a continuación, pero lo esencial es cómo se forman y muestran los nombres de las columnas.
Consulte el siguiente formato de columna para la función wide_to_long().
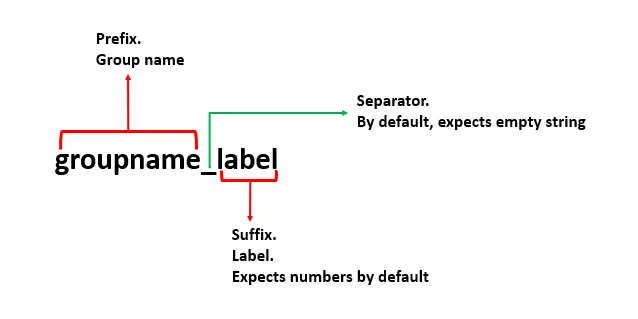
Estamos pasando cuatro parámetros a la función pd.wide_to_long() para remodelar el marco de datos de formato de datos ancho a largo. Los cuatro parámetros que utilizamos se enumeran a continuación:
df: este es el marco de datos que queremos remodelar.stubnames: también podemos decir nombres de grupos (prefijos) que deben agruparse. En nuestro caso, se trata delaboratorioyteoría.i: es la(s) variable(s) de identificador que se supone que no debe apilarse.j- El nombre de la columna que contiene los sufijos, o podemos decir las etiquetas de las columnas.
Los parámetros opcionales son sep (separador) y sufijo. Puede leer más sobre pd.melt(), pd.wide_to_long() y DataFrame.unstack() aquí.

Artículo relacionado - Pandas DataFrame
- Cómo obtener las cabeceras de columna de Pandas DataFrame como una lista
- Cómo borrar la columna de Pandas DataFrame
- Cómo convertir la columna del DataFrame a Datetime en Pandas
- Cómo convertir un float en un entero en Pandas DataFrame
- Cómo clasificar Pandas DataFrame por los valores de una columna
- Cómo obtener el agregado de Pandas grupo por y suma