パンダの反結合

このチュートリアルでは、Pandas のアンチ結合について説明し、それらの型について簡単に説明し、サンプル コードを使用してそれぞれを示します。
Pandas アンチ結合とその型
アンチ結合を使用すると、1つのデータセットで一致する値が見つからないすべての行 (レコードおよびドキュメントとも呼ばれる) を、他のデータセットで返すことができます。 これらは、プロジェクトの要件に従ってデータセットを操作するために使用されます。
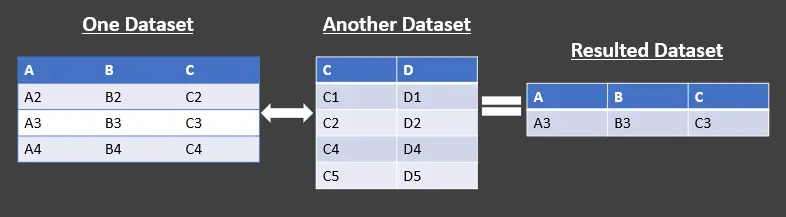
Pandas には、以下に示す 2 種類のアンチ結合があります。
- 左側のアンチ結合 - 右側のデータセットに一致するレコードがない左側のデータセットのレコードを返します。
- 右側のアンチ結合 - 左側のデータセットのレコードと一致しない右側のデータセットのレコードを返します。
上記の表形式の表現を参照してください。 交差点を除く左のデータセットを返す左のアンチ結合を使用しています。
右側からではなく、左側のデータセットから列のみを返すことに注意してください。
同様に、右のアンチ結合を使用すると、交差を除いて正しいデータセットが返されます。 左アンチ結合と同様に、左側からではなく、右側のデータセットからのみ列を返します。
Pandas でこれらの両方のアンチ結合を使用する方法を学びましょう。 なお、アンチジョインをしっかりと把握するにはSQLジョインの知識が必要です。
Pandas で左反結合を実行する
-
ライブラリをインポートします。
import pandas as pdまず、
pandasライブラリをインポートして、データ フレームを操作します。 -
2つのデータ フレームを作成します。
# first DataFrame df1 = pd.DataFrame( {"sections": ["A", "B", "C", "D", "E"], "points": [19, 23, 20, 15, 31]} ) print("First DataFrame:") print(df1) # second DataFrame df2 = pd.DataFrame( {"sections": ["A", "B", "C", "F", "G"], "points": [19, 23, 20, 24, 30]} ) print("\n\nSecond DataFrame:") print(df2)以下に示すように、さまざまな
セクションのサンプルポイントを含む 2つのデータ フレームを作成します。出力:
First DataFrame: sections points 0 A 19 1 B 23 2 C 20 3 D 15 4 E 31 Second DataFrame: sections points 0 A 19 1 B 23 2 C 20 3 F 24 4 G 30 -
外部結合を実行します。
outer_join = df1.merge(df2, how="outer", indicator=True) print(outer_join)アンチ結合を実行するには、いずれかまたは両方のデータセットから一致する値と一致しない値を返す外部結合を実行する必要があります。 両方のデータセットから一致する値と一致しない値を取得しています (これは次の出力で確認できます)。
ここでは、
merge()メソッドを使用して、特定のメソッドを使用して 2つのデータ フレームのデータを更新し、それらをマージします。 どの値を置き換え、何を保持するかを制御するために、いくつかのパラメーターを使用しています。df2- マージする別のデータ フレームです。how- マージ方法を指定します。 これはオプションのパラメーターで、値はleft、right、outer、inner、またはcrossのいずれかです。 デフォルトではinnerです。indicator-True、False、または文字列型の値に設定できます。Trueに設定すると、すべての行のソースに関する情報を持つ出力データ フレームに_merge列が追加されます。
文字列引数を指定して、
_merge列に別の名前を付けることもできます。 この列には、次の出力にあるように、left_only、right_only、bothなどのカテゴリ型の値が含まれます。ここで、
bothは観測 (行) のマージ キーが両方のデータセットで見つかった場合を意味し、left_onlyは観測のマージ キーが左側のデータセットでのみ見つかったことを示し、right_onlyは観測のマージ キーが見つかったことを示します。 キーは正しいデータセットでのみ見つかります。出力:
sections points _merge 0 A 19 both 1 B 23 both 2 C 20 both 3 D 15 left_only 4 E 31 left_only 5 F 24 right_only 6 G 30 right_only -
左アンチ結合を実行します。
lef_anti_join = outer_join[(outer_join._merge == "left_only")].drop("_merge", axis=1) print(lef_anti_join)まず、
outer_join[(outer_join._merge=='left_only')]を使用して、_merge列にleft_only値を持つすべての行を取得し、.drop()メソッドで連鎖させます。_merge列を出力データ フレームから削除します。出力:
sections points 3 D 15 4 E 31ここで、交差点を除いて、左側のデータ フレーム (
df1) から列を取得します。 -
Pandas で左反結合を実行するには、完全なソース コードを参照してください。
import pandas as pd # first DataFrame df1 = pd.DataFrame( {"sections": ["A", "B", "C", "D", "E"], "points": [19, 23, 20, 15, 31]} ) print("First DataFrame:") print(df1) # second DataFrame df2 = pd.DataFrame( {"sections": ["A", "B", "C", "F", "G"], "points": [19, 23, 20, 24, 30]} ) print("\n\nSecond DataFrame:") print(df2) # outer join outer_join = df1.merge(df2, how="outer", indicator=True) # left anti join lef_anti_join = outer_join[(outer_join._merge == "left_only")].drop("_merge", axis=1) print("\n\nLeft Anti-join:") print(lef_anti_join)出力:
First DataFrame: sections points 0 A 19 1 B 23 2 C 20 3 D 15 4 E 31 Second DataFrame: sections points 0 A 19 1 B 23 2 C 20 3 F 24 4 G 30 Left Anti-join: sections points 3 D 15 4 E 31
Pandas で適切なアンチ結合を実行する
Pandas で左反結合を実行する方法を段階的に学びました。 右側のアンチ結合も同様に行うことができますが、ここでは _merge 列に right_only の値を持つ行を選択します。
コード例:
import pandas as pd
# first DataFrame
df1 = pd.DataFrame(
{"sections": ["A", "B", "C", "D", "E"], "points": [19, 23, 20, 15, 31]}
)
print("First DataFrame:")
print(df1)
# second DataFrame
df2 = pd.DataFrame(
{"sections": ["A", "B", "C", "F", "G"], "points": [19, 23, 20, 24, 30]}
)
print("\n\nSecond DataFrame:")
print(df2)
# outer join
outer_join = df1.merge(df2, how="outer", indicator=True)
# right anti join
right_anti_join = outer_join[(outer_join._merge == "right_only")].drop("_merge", axis=1)
print("\n\nRight Anti-join:")
print(right_anti_join)
出力:
First DataFrame:
sections points
0 A 19
1 B 23
2 C 20
3 D 15
4 E 31
Second DataFrame:
sections points
0 A 19
1 B 23
2 C 20
3 F 24
4 G 30
Right Anti-join:
sections points
5 F 24
6 G 30
今回は、交差点を除いて、右側のデータ フレーム (df2) から列を取得します。
